参考《算法竞赛进阶指南》 、AcWing题库
二叉搜索树与平衡树初步
在二叉树中, 有两组非常重要的条件, 分别是两类数据结构的基础性质。其一是 “堆性质”。二叉堆以及高级数据结构中的所有可合并堆, 都满足 “堆性质”。其二就是本节即将探讨的 “BST 性质”, 它是二叉搜索树 (Binary Search Tree)以及所有平衡树的基础。
BST
给定一棵二叉树, 树上的每个节点带有一个数值, 称为节点的 “关键码 ” 。所谓 “BST 性质” 是指, 对于树中的任意一个节点:
该节点的关键码不小于它的左子树中任意节点的关键码;
该节点的关键码不大于它的右子树中任意节点的关键码。
满足上述性质的二叉树就是一棵 “二叉搜索树” (BST)。显然, 二叉搜索树的中序遍历是一个关键码单调递增的节点序列。
BST 的建立
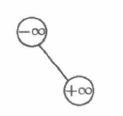
为了避免越界, 减少边界情况的特殊判断, 我们一般在 BST 中额外插入一个关键码为正无穷 (一个很大的正整数) 和一个关键码为负无穷的节点。仅由这两个节点构成的 BST 就是一棵初始的空 BST。如图所示。
简便起见, 在接下来的操作中, 我们假设 BST 不会含有关键码相同的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct BST { int l, r; int val; } a[SIZE]; int tot, root, INF = 1 <<30 ;int New (int val) a[++tot].val = val; return tot; } void Build () New (-INF), New (INF); root = 1 , a[1 ].r = 2 ; }
BST 的检索
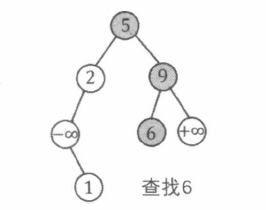
在 BST 中检索是否存在关键码为 v a l val v a l p p p r o o t root roo t
若 p p p
若 p p p v a l v a l v a l p p p v a l v a l v a l p p p p p p
若 p p p v a l v a l v a l p p p v a l v a l v a l p p p p p p
1 2 3 4 5 int Get (int p, int val) if (p == 0 ) return 0 ; if (val == a[p].val) return p; return val < a[p].val ? Get (a[p].l, val) : Get (a[p].r, val); }
BST 的插入
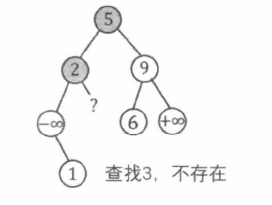
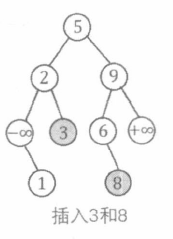
在 BST 中插入一个新的值 v a l v a l v a l v a l v a l v a l
与 BST 的检索过程类似。
在发现要走向的 p p p v a l val v a l v a l val v a l p p p
1 2 3 4 5 6 7 8 9 void Insert (int &p, int val) if (p == 0 ) { p = New (val); return ; } if (val == a[p].val) return ; if (val < a[p].val) Insert (a[p].l, val); else Insert (a[p].r, val); }
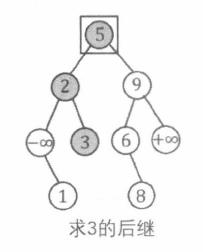
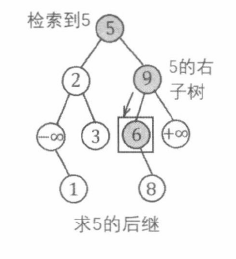
BST 求前驱 / 后继
以 “后继” 为例。v a l val v a l v a l val v a l
初始化 a n s ans an s v a l val v a l a n s ans an s
检索完成后, 有三种可能的结果:
没有找到 v a l val v a l v a l val v a l a n s ans an s
找到了关键码为 v a l val v a l p p p p p p a n s ans an s
找到了关键码为 v a l val v a l p p p p p p p p p v a l val v a l
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int GetNext (int val) int ans = 2 ; int p = root; while (p) { if (val == a[p].val) { if (a[p].r > 0 ) { p = a[p].r; while (a[p].l > 0 ) p = a[p].l; ans = p; } break ; } if (a[p].val > val && a[p].val < a[ans].val) ans = p; p = val < a[p].val ? a[p].l : a[p].r; } return ans; }
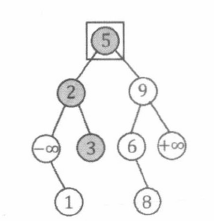
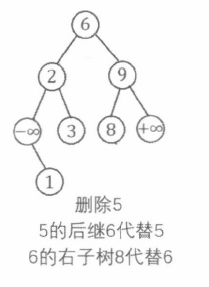
BST 的节点删除
从 BST 中删除关键码为 v a l v a l v a l
首先, 在 BST 中检索 v a l v a l v a l p p p
若 p p p p p p p p p p p p p p p
若 p p p v a l v a l v a l n e x t next n e x t n e x t next n e x t n e x t next n e x t n e x t next n e x t n e x t next n e x t n e x t next n e x t p p p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void Remove (int &p, int val) if (p == 0 ) return ; if (val == a[p].val) { if (a[p].l == 0 ) { p = a[p].r; } else if (a[p].r == 0 ) { p = a[p].l; } else { int next = a[p].r; while (a[next].l > 0 ) next = a[next].l; Remove (a[p].r, a[next].val); a[next].l = a[p].l, a[next].r = a[p].r; p = next; } return ; } if (val < a[p].val) { Remove (a[p].l, val); } else { Remove (a[p].r, val); } }
在随机数据中, BST 一次操作的期望复杂度为 O ( log N ) O(\log N) O ( log N ) O ( N ) \mathrm{O}(N) O ( N )
Treap
满足 BST 性质且中序遍历为相同序列的二叉查找树是不唯一的。这些二叉查找树是等价的, 它们维护的是相同的一组数值。在这些二叉查找树上执行同样的操作, 将得到相同的结果。因此, 我们可以在维持 BST 性质的基础上, 通过改变二叉查找树的形态, 使得树上每个节点的左右子树大小达到平衡, 从而使整棵树的深度维持在 O ( log N ) O(\log N) O ( log N )
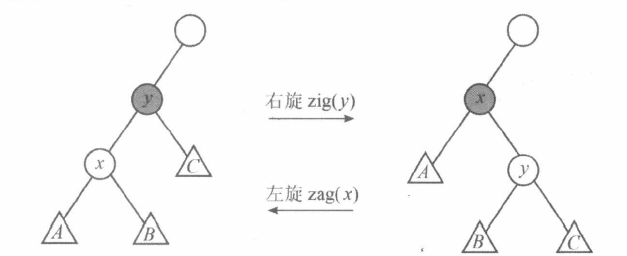
改变形态并保持 BST 性质的方法就是 “旋转 ”。最基本的旋转操作称为 “单旋转”, 它又分为 “左旋” 和 “右旋” 。如下图所示。
注意: 某些书籍中把左、右旋操作定义为一个节点绕其父节点向左或右旋转。本文后面即将讲解的 Treap 代码仅记录左右子节点, 没有记录父节点, 为了方便起见, 统一以 “旋转前处于父节点位置” (旋转后处于子节点位置) 的节点作为左、右旋的作用对象 (函数参数)。
以右旋为例。在初始情况下, x x x y y y A A A B B B x x x C C C y y y
“右旋” 操作在保持 BST 性质的基础上, 把 x x x y y y x x x y y y y y y x x x
当 x x x y y y y y y x x x B B B y y y
右旋操作的代码如下, zig ( p ) \operatorname{zig}(p) zig ( p ) p p p p p p
1 2 3 4 5 void zig (int &p) int ls = a[p].l; a[p].l = a[ls].r, a[ls].r = p; p = ls; }
左旋操作的代码如下, zag ( p ) \operatorname{zag}(p) zag ( p ) p p p p p p
1 2 3 4 5 void zag (int &p) int rs = a[p].r; a[p].r = a[rs].l, a[rs].l = p; p = rs; }
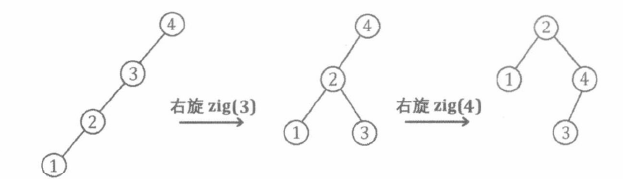
合理的旋转操作可使 BST 变得更 “平衡”。如下图所示, 对形态为一条链的 BST 进行一系列单旋转操作后, 这棵 BST 变得比较平衡了。
现在, 我们的问题是, 怎样才算 “合理” 的旋转操作呢? 我们发现, 在随机数据下, 普通的 BST 就是趋近平衡的。Treap 的思想就是利用 “随机” 来创造平衡条件。因为在旋转过程中必须维持 BST 性质,所以 Treap 就把 “随机” 作用在堆性质上。
Treap 是英文 Tree 和 Heap 的合成词。Treap 在插入每个新节点时, 给该节点随机生成一个额外的权值。然后像二叉堆的插入过程一样, 自底向上依次检查, 当某个节点不满足大根堆性质时, 就执行单旋转, 使该点与其父节点的关系发生对换。
特别地, 对于删除操作, 因为 Treap 支持旋转, 我们可以直接找到需要删除的节点, 并把它向下旋转成叶节点, 最后直接删除 。这样就避免了采取类似普通 BST 的删除方法可能导致的节点信息更新、堆性质维护等复杂问题。
总而言之, Treap 通过适当的单旋转, 在维持节点关键码满足 BST 性质的同时, 还使每个节点上随机生成的额外权值满足大根堆性质 。Treap 是一种平衡二叉搜索树, 检索、插入、求前驱后继以及删除节点的时间复杂度都是 O ( log N ) O(\log N) O ( log N )
除了 Treap 以外, 常见的平衡二叉查找树还有 Splay、红黑树、AVL、SBT、替罪羊树等。其中, C++ STL 的 set、map 等就采用了效率很高的红黑树的一种变体。不过, 大多数平衡树因为实现比较复杂, 或者应用范围能被其他平衡树替代, 在算法竞赛等短时间程序设计中并不常用。在这些平衡树中, Splay (伸展树) 灵活多变, 应用广泛, 能够很方便地支持各种动态的区间操作, 是用于解决复杂问题的一个重要的高级数据结构。
您需要写一种数据结构(可参考题目标题),来维护一些数,其中需要提供以下操作:
插入数值 x x x
删除数值 x x x
查询数值 x x x
查询排名为 x x x
求数值 x x x x x x
求数值 x x x x x x
注意: 数据保证查询的结果一定存在。
输入格式
第一行为 n n n
接下来 n n n o p t opt o pt x x x o p t opt o pt 1 ≤ o p t ≤ 6 1 \le opt \le 6 1 ≤ o pt ≤ 6
输出格式
对于操作 3 , 4 , 5 , 6 3,4,5,6 3 , 4 , 5 , 6
数据范围
1 ≤ n ≤ 100000 1 \le n \le 100000 1 ≤ n ≤ 100000 − 1 0 7 -10^7 − 1 0 7 1 0 7 10^7 1 0 7
输入样例:
1 2 3 4 5 6 7 8 9 8 1 10 1 20 1 30 3 20 4 2 2 10 5 25 6 -1
输出样例:
算法分析
这是一道平衡树的模板题, 我们直接用 Treap 实现即可。
根据题意, 数据中可能有相同的数值, 我们可以给每个节点增加一个域 c n t \mathrm{cnt} cnt , 初始为 1 。若插入已经存在的数值, 就直接把 “副本数” 加 1 。在删除时, 减少节点的 “副本数”, 当减为 0 时删除该节点。这样就可以比较容易地处理关键码相同的问题。
题目还要求查询排名, 我们可以给每个节点增加一个域 s i z e size s i ze 。当不存在重复数值时, s i z e size s i ze
与线段树一样, 我们需要在插入或删除时从下往上更新 s i z e size s i ze s i z e size s i ze s i z e size s i ze
因为在插入和删除操作时, Treap 的形态会发生变化, 所以我们一般使用递归实现, 以便于在回溯时更新 Treap 上存储的 s i z e size s i ze
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> using namespace std;const int SIZE = 100010 ;struct Treap { int l, r; int val, dat; int cnt, size; } a[SIZE]; int tot, root, n, INF = 0x7fffffff ;int New (int val) a[++tot].val = val; a[tot].dat = rand (); a[tot].cnt = a[tot].size = 1 ; return tot; } void Update (int p) a[p].size = a[a[p].l].size + a[a[p].r].size + a[p].cnt; } void Build () New (-INF), New (INF); root = 1 , a[1 ].r = 2 ; Update (root); } int GetRankByVal (int p, int val) if (p == 0 ) return 0 ; if (val == a[p].val) return a[a[p].l].size + 1 ; if (val < a[p].val) return GetRankByVal (a[p].l, val); return GetRankByVal (a[p].r, val) + a[a[p].l].size + a[p].cnt; } int GetValByRank (int p, int rank) if (p == 0 ) return INF; if (a[a[p].l].size >= rank) return GetValByRank (a[p].l, rank); if (a[a[p].l].size + a[p].cnt >= rank) return a[p].val; return GetValByRank (a[p].r, rank - a[a[p].l].size - a[p].cnt); } void zig (int &p) int q = a[p].l; a[p].l = a[q].r, a[q].r = p, p = q; Update (a[p].r), Update (p); } void zag (int &p) int q = a[p].r; a[p].r = a[q].l, a[q].l = p, p = q; Update (a[p].l), Update (p); } void Insert (int &p, int val) if (p == 0 ) { p = New (val); return ; } if (val == a[p].val) { a[p].cnt++, Update (p); return ; } if (val < a[p].val) { Insert (a[p].l, val); if (a[p].dat < a[a[p].l].dat) zig (p); } else { Insert (a[p].r, val); if (a[p].dat < a[a[p].r].dat) zag (p); } Update (p); } int GetPre (int val) int ans = 1 ; int p = root; while (p) { if (val == a[p].val) { if (a[p].l > 0 ) { p = a[p].l; while (a[p].r > 0 ) p = a[p].r; ans = p; } break ; } if (a[p].val < val && a[p].val > a[ans].val) ans = p; p = val < a[p].val ? a[p].l : a[p].r; } return a[ans].val; } int GetNext (int val) int ans = 2 ; int p = root; while (p) { if (val == a[p].val) { if (a[p].r > 0 ) { p = a[p].r; while (a[p].l > 0 ) p = a[p].l; ans = p; } break ; } if (a[p].val > val && a[p].val < a[ans].val) ans = p; p = val < a[p].val ? a[p].l : a[p].r; } return a[ans].val; } void Remove (int &p, int val) if (p == 0 ) return ; if (val == a[p].val) { if (a[p].cnt > 1 ) { a[p].cnt--, Update (p); return ; } if (a[p].l || a[p].r) { if (a[p].r == 0 || a[a[p].l].dat > a[a[p].r].dat) zig (p), Remove (a[p].r, val); else zag (p), Remove (a[p].l, val); Update (p); } else p = 0 ; return ; } val < a[p].val ? Remove (a[p].l, val) : Remove (a[p].r, val); Update (p); } int main () Build (); cin >> n; while (n--) { int opt, x; scanf ("%d%d" , &opt, &x); switch case 1 : Insert (root, x); break ; case 2 : Remove (root, x); break ; case 3 : printf ("%d\n" , GetRankByVal (root, x) - 1 ); break ; case 4 : printf ("%d\n" , GetValByRank (root, x + 1 )); break ; case 5 : printf ("%d\n" , GetPre (x)); break ; case 6 : printf ("%d\n" , GetNext (x)); break ; } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 #include <bits/stdc++.h> using namespace std;struct Node { Node* left; Node* right; int key, val; int cnt, size; Node (int data) { key = data; val = rand (); cnt = size = 1 ; left = right = nullptr ; } }; class Treap {public : Treap () { root = new Node (-1e9 ); root->right = new Node (1e9 ); update (root); } void Insert (int data) root = Insert (root, data); } void Remove (int data) root = Remove (root, data); } int GetRankByVal (int target) return GetRankByVal (root, target) - 1 ; } int GetValByRank (int rank) return GetValByRank (root, rank + 1 ); } int GetPre (int target) int ans = -1e9 ; Node* p = root; while (p) { if (target == p->key) { if (p->left) { p = p->left; while (p->right) p = p->right; ans = p->key; } break ; } if (p->key < target && p->key > ans) ans = p->key; p = target < p->key ? p->left : p->right; } return ans; } int GetNext (int target) int ans = 1e9 ; Node* p = root; while (p) { if (target == p->key) { if (p->right) { p = p->right; while (p->left) p = p->left; ans = p->key; } break ; } if (p->key > target && p->key < ans) ans = p->key; p = target < p->key ? p->left : p->right; } return ans; } private : int GetRankByVal (Node* p, int target) if (p == nullptr ) return 0 ; int left_size = p->left ? p->left->size : 0 ; if (target == p->key) return left_size + 1 ; if (target < p->key) return GetRankByVal (p->left, target); return left_size + p->cnt + GetRankByVal (p->right, target); } int GetValByRank (Node* p, int rank) if (p == nullptr ) return 1e9 ; int left_size = p->left ? p->left->size : 0 ; if (left_size >= rank) return GetValByRank (p->left, rank); if (left_size + p->cnt >= rank) return p->key; return GetValByRank (p->right, rank - left_size - p->cnt); } Node* Insert (Node* p, int data) { Node* res = p; if (p == nullptr ) { res = new Node (data); } else if (data == p->key) { p->cnt++; } else if (data < p->key) { p->left = Insert (p->left, data); if (p->val < p->left->val) res = zig (p); } else { p->right = Insert (p->right, data); if (p->val < p->right->val) res = zag (p); } update (res); return res; } Node* Remove (Node* p, int data) { if (p == nullptr ) return nullptr ; if (data == p->key) { if (p->cnt > 1 ) { p->cnt--; update (p); return p; } if (!p->left && !p->right) { delete p; return nullptr ; } Node* res = p; if (!p->right || (p->left && p->left->key > p->right->key)) { res = zig (p); res->right = Remove (res->right, data); } else { res = zag (p); res->left = Remove (res->left, data); } if (res) update (res); return res; } if (data < p->key) p->left = Remove (p->left, data); else p->right = Remove (p->right, data); if (p) update (p); return p; } Node* zig (Node* p) { Node* q = p->left; p->left = q->right; q->right = p; update (p); update (q); return q; } Node* zag (Node* p) { Node* q = p->right; p->right = q->left; q->left = p; update (p); update (q); return q; } void update (Node* p) int left_size = p->left ? p->left->size : 0 ; int right_size = p->right ? p->right->size : 0 ; p->size = left_size + right_size + p->cnt; } Node* root; }; int main () Treap treap; int n; cin >> n; while (n--) { int opt, x; scanf ("%d%d" , &opt, &x); switch case 1 : treap.Insert (x); break ; case 2 : treap.Remove (x); break ; case 3 : printf ("%d\n" , treap.GetRankByVal (x)); break ; case 4 : printf ("%d\n" , treap.GetValByRank (x)); break ; case 5 : printf ("%d\n" , treap.GetPre (x)); break ; case 6 : printf ("%d\n" , treap.GetNext (x)); break ; } } }
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int N = 100010 , INF = 1e9 ;int n;struct Node { int l, r; int key, val; int cnt, size; } tr[N]; int root, idx;void pushup (int u) int ls = tr[u].l, rs = tr[u].r; tr[u].size = tr[ls].size + tr[rs].size + tr[u].cnt; } int getNode (int key) tr[++idx].key = key; tr[idx].val = rand (); tr[idx].cnt = tr[idx].size = 1 ; return idx; } void zig (int &u) int ls = tr[u].l; tr[u].l = tr[ls].r, tr[ls].r = u, u = ls; pushup (tr[u].r), pushup (u); } void zag (int &u) int rs = tr[u].r; tr[u].r = tr[rs].l, tr[rs].l = u, u = rs; pushup (tr[u].l), pushup (u); } void build () getNode (-INF), getNode (INF); root = 1 , tr[1 ].r = 2 ; pushup (root); if (tr[1 ].val < tr[2 ].val) zag (root); } void insert (int &p, int key) if (p == 0 ) { p = getNode (key); return ; } if (tr[p].key == key) { ++tr[p].cnt; } else if (key < tr[p].key) { insert (tr[p].l, key); if (tr[tr[p].l].val > tr[p].val) zig (p); } else { insert (tr[p].r, key); if (tr[tr[p].r].val > tr[p].val) zag (p); } pushup (p); } void Remove (int &p, int key) if (p == 0 ) return ; if (tr[p].key == key) { if (tr[p].cnt > 1 ) { --tr[p].cnt; } else if (tr[p].l || tr[p].r) { if (tr[p].r == 0 || tr[tr[p].l].val > tr[tr[p].r].val) { zig (p); Remove (tr[p].r, key); } else { zag (p); Remove (tr[p].l, key); } } else { p = 0 ; } } else if (key < tr[p].key) { Remove (tr[p].l, key); } else { Remove (tr[p].r, key); } pushup (p); } int getRankByKey (int p, int key) if (p == 0 ) return 0 ; if (tr[p].key == key) { return tr[tr[p].l].size + 1 ; } else if (key < tr[p].key) { return getRankByKey (tr[p].l, key); } else { return tr[tr[p].l].size + tr[p].cnt + getRankByKey (tr[p].r, key); } } int getKeyByRank (int p, int rank) if (p == 0 ) return INF; if (tr[tr[p].l].size >= rank) { return getKeyByRank (tr[p].l, rank); } else if (tr[tr[p].l].size + tr[p].cnt >= rank) { return tr[p].key; } else { return getKeyByRank (tr[p].r, rank - tr[tr[p].l].size - tr[p].cnt); } } int getPrev (int p, int key) if (p == 0 ) return -INF; if (key <= tr[p].key) { return getPrev (tr[p].l, key); } else { return max (tr[p].key, getPrev (tr[p].r, key)); } } int getNext (int p, int key) if (p == 0 ) return INF; if (key >= tr[p].key) { return getNext (tr[p].r, key); } else { return min (tr[p].key, getNext (tr[p].l, key)); } } int main () build (); cin >> n; while (n--) { int opt, x; cin >> opt >> x; if (opt == 1 ) insert (root, x); else if (opt == 2 ) Remove (root, x); else if (opt == 3 ) cout << getRankByKey (root, x) - 1 << endl; else if (opt == 4 ) cout << getKeyByRank (root, x + 1 ) << endl; else if (opt == 5 ) cout << getPrev (root, x) << endl; else cout << getNext (root, x) << endl; } }
Tiger 最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况。
Tiger 拿出了公司的账本,账本上记录了公司成立以来每天的营业额。
分析营业情况是一项相当复杂的工作。
由于节假日,大减价或者是其他情况的时候,营业额会出现一定的波动,当然一定的波动是能够接受的,但是在某些时候营业额突变得很高或是很低,这就证明公司此时的经营状况出现了问题。
经济管理学上定义了一种最小波动值来衡量这种情况。
设第 i i i a i a_i a i i i i i ≥ 2 i \ge 2 i ≥ 2 f i f_i f i
f i = m i n 1 ≤ j < i ∣ a i − a j ∣ f_i=min_{1 \le j < i}|a_i-a_j|
f i = mi n 1 ≤ j < i ∣ a i − a j ∣
当最小波动值越大时,就说明营业情况越不稳定。
而分析整个公司的从成立到现在营业情况是否稳定,只需要把每一天的最小波动值加起来就可以了。
你的任务就是编写一个程序帮助 Tiger 来计算这一个值。
第一天的最小波动值为第一天的营业额 a 1 a_1 a 1
输入格式
第一行为正整数 n n n
接下来的 n n n a i a_i a i i i i
输出格式
输出一个正整数,表示最小波动值的和。
数据范围
1 ≤ n ≤ 32767 , ∣ a i ∣ ≤ 1 0 6 1 \le n \le 32767, |a_i| \le 10^6 1 ≤ n ≤ 32767 , ∣ a i ∣ ≤ 1 0 6
输入样例:
输出样例:
样例解释
在样例中,5 + ∣ 1 − 5 ∣ + ∣ 2 − 1 ∣ + ∣ 5 − 5 ∣ + ∣ 4 − 5 ∣ + ∣ 6 − 5 ∣ = 5 + 4 + 1 + 0 + 1 + 1 = 12 5+|1-5|+|2-1|+|5-5|+|4-5|+|6-5|=5+4+1+0+1+1=12 5 + ∣1 − 5∣ + ∣2 − 1∣ + ∣5 − 5∣ + ∣4 − 5∣ + ∣6 − 5∣ = 5 + 4 + 1 + 0 + 1 + 1 = 12
算法分析
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include <iostream> #include <cstring> #include <algorithm> using namespace std;using LL = long long ;const int N = 33010 , INF = 1e9 ;int n;int root, idx;struct Node { int l, r; int key, val; } tr[N]; int getNode (int key) tr[++idx].key = key; tr[idx].val = rand (); return idx; } void build () getNode (-INF), getNode (INF); root = 1 , tr[1 ].r = 2 ; } void zig (int &u) int ls = tr[u].l; tr[u].l = tr[ls].r, tr[ls].r = u, u = ls; } void zag (int &u) int rs = tr[u].r; tr[u].r = tr[rs].l, tr[rs].l = u, u = rs; } void insert (int &p, int key) if (p == 0 ) { p = getNode (key); } else if (key == tr[p].key) { return ; } else if (key < tr[p].key) { insert (tr[p].l, key); if (tr[tr[p].l].val > tr[p].val) zig (p); } else { insert (tr[p].r, key); if (tr[tr[p].r].val > tr[p].val) zag (p); } } int getPrev (int p, int key) if (p == 0 ) return -INF; if (key < tr[p].key) return getPrev (tr[p].l, key); else return max (tr[p].key, getPrev (tr[p].r, key)); } int getNext (int p, int key) if (p == 0 ) return INF; if (key > tr[p].key) return getNext (tr[p].r, key); else return min (tr[p].key, getNext (tr[p].l, key)); } int main () build (); cin >> n; LL ans = 0 ; for (int i = 1 ; i <= n; ++i) { int x; cin >> x; if (i == 1 ) ans += x; else ans += min (x - getPrev (root, x), getNext (root, x) - x); insert (root, x); } cout << ans; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <set> using namespace std;const int N = 33010 , INF = 1e9 ;int n;int main () cin >> n; multiset<int > s; s.insert (INF); s.insert (-INF); long long ans = 0 ; for (int i = 1 ; i <= n; ++i) { int x; cin >> x; if (i == 1 ) ans += x; else ans += min (*s.lower_bound (x) - x, x - *(--s.upper_bound (x))); s.insert (x); } cout << ans; }