参考《算法竞赛进阶指南》 、AcWing题库
位运算
bit 是度量信息的单位, 包含 0 和 1 两种状态。计算机的各种运算最后无不归结为 一个个 bit 的变化。熟练掌握并利用位运算, 能够帮助我们理解程序运行中的种种表现, 提高程序运行的时空效率, 降低编程复杂度。
在 C + + \mathrm{C}++ C + + − 128 ∼ 127 -128 \sim 127 − 128 ∼ 127 0 × F F 0 \times F F 0 × FF 0 × 7 F 0 \times 7 F 0 × 7 F
在阅读本节之前, 读者应该对以下算术位运算有一个初步的认识:
与
或
非
异或
a n d , & and,\& an d , & $or,
$
n o t , ∼ not,\sim n o t , ∼
它们不局限于逻辑运算, 均可作用于二进制整数。为了避免混淆, 统一用单词 xor 表示异或运算 , 而用符号 “^” 表示乘方运算 (虽然该符号在 C++中表示异或)。
另外, 在 m m m 最低位为第 0 位, 从右到左依此类推, 最高位为第 m − 1 m-1 m − 1 。默认使用这种表示方法来指明二进制数以及整数在二进制表示下的位数。
下面我们以 32 位二进制数, 即 C + + \mathrm{C}++ C + +
补码
32 位无符号整数 unsigned int:
直接把这 32 位编码 C C C N N N
32 位有符号整数 int:
以最高位为符号位, 0 表示非负数, 1 表示负数。
对于最高位为 0 的每种编码 C C C S S S
同时, 定义该编码按位取反后得到的编码 ∼ C \sim C ∼ C − 1 − S -1-S − 1 − S
32位补码表示
unsigned int
int
000000 ⋯ 000000 000000\cdots000000 000000 ⋯ 000000 0
0
011111 ⋯ 111111 011111\cdots111111 011111 ⋯ 111111 2 147 483 647
2 147 483 647
100000 ⋯ 000000 100000\cdots000000 100000 ⋯ 000000 2 147 483 648
-2 147 483 648
111111 ⋯ 111111 111111\cdots111111 111111 ⋯ 111111 4 294 967 295
-1
可以发现在补码下每个数值都有唯一的表示方式, 并且任意两个数值做加减法运算, 都等价于在 32 位补码下做最高位不进位 的二进制加减法运算。发生算术溢出时, 32 位无符号整数相当于自动对 2 32 2^{32} 2 32 。这也解释了 “有符号整数” 算术上溢时出现负数的现象。
补码也被称为 “二补数”。还有一种编码称为反码, 也叫 “一补数” , 直接把 C C C C C C 2 、 3 2 、 3 2 、 3
形式
加数
加数
和
32位补码
111 ⋯ 111 111\cdots111 111 ⋯ 111 000 ⋯ 001 000\cdots001 000 ⋯ 001 (1 )000 ⋯ 000 000\cdots000 000 ⋯ 000
int
-1
1
0
unsigned int
4 294 967 295
1
0(mod 2 32 2^{32} 2 32
32位补码
011 ⋯ 111 011\cdots111 011 ⋯ 111 000 ⋯ 001 000\cdots001 000 ⋯ 001 0
int
2 147 483 647
1
-2 147 483 648
unsigned int
2 147 483 647
1
2 147 483 648
因为用二进制表示一个 int 需要写出 32 位, 比较繁琐, 而用十进制表示, 又不容易明显地体现出补码的每一位, 所以在程序设计中, 常用十六进制来表示一个常数, 这样只需要书写 8 个字符, 每个字符 ( 0 ∼ 9 , A ∼ F ) (0 \sim 9, A \sim F) ( 0 ∼ 9 , A ∼ F ) C + + C++ C + + 0 x 0 \mathrm{x} 0 x 0 x 0 \mathrm{x} 0 x 0 x 0 \mathrm{x} 0 x
32位补码表示
int(十进制)
int(十六进制)
000000 ⋯ 000000 000000\cdots000000 000000 ⋯ 000000 0
0x0
011111 ⋯ 111111 011111\cdots111111 011111 ⋯ 111111 2 147 483 647
0x7F FF FF FF
0011 1111 重复4次
1 061 109 567
0x3F 3F 3F 3F
111111 ⋯ 111111 111111\cdots111111 111111 ⋯ 111111 -1
-1
上表中的 0x3F 3F 3F 3F 是一个很有用的数值, 它是满足以下两个条件的最大整数。
整数的两倍不超过 0x7F FF FF FF , 即 int 能表示的最大正整数。
整数的每 8 位 (每个字节) 都是相同的。
我们在程序设计中经常需要使用 memset ( a, val, sizeof(a)) 初始化一个 int 数组 a a a a a a
综上所述, 0x7F FF FF FF 是用 memset 语句能初始化出的最大数值。不过, 当需要把一个数组中的数值初始化成正无穷时, 为了避免加法算术上温或者繁琐的判断, 我们经常用 memset (a, 0x3f, sizeof (a)) 给数组赋 0x3F 3F 3F 3F 的值来代替。
2 30 = 1073741824 2^{30}=1 073 741 824 2 30 = 1073741824
移位运算
左移
在二进制表示下把数字同时向左移动, 低位以 0 填充, 高位越界后舍弃。
1 ≪ n = 2 n , n ≪ 1 = 2 n 1 \ll n=2^{n}, \quad n \ll 1=2 n
1 ≪ n = 2 n , n ≪ 1 = 2 n
算术右移
在二进制补码表示下把数字同时向右移动, 高位以符号位填充, 低位越界后舍弃。
n ≫ 1 = ⌊ n 2.0 ⌋ n \gg 1=\left\lfloor\frac{n}{2.0}\right\rfloor
n ≫ 1 = ⌊ 2.0 n ⌋
算术右移等于除以 2 向下取整, ( − 3 ) ≫ 1 = − 2 , 3 ≫ 1 = 1 (-3) \gg 1=-2,3 \gg 1=1 ( − 3 ) ≫ 1 = − 2 , 3 ≫ 1 = 1
值得一提的是, “整数/2” 在 C++ 中实现为 “除以 2 向零取整”, ( − 3 ) / 2 = − 1 , 3 / 2 = 1 (-3) / 2=-1,\;3 / 2=1 ( − 3 ) /2 = − 1 , 3/2 = 1
逻辑右移
在二进制补码表示下把数字同时向右移动, 高位以 0 填充, 低位越界后舍弃。
C++语法没有规定右移的实现方式, 使用算术右移还是逻辑右移由编译器决定。一般的编译器 (较新版本的 GNU C++与 Visual StudioC++ 均使用算术右移。除非特殊提示, 我们默认右移操作采用算术右移方式实现。
题目描述
求 a a a b b b p p p
输入格式
三个整数 a , b , p a,b,p a , b , p
输出格式
输出一个整数,表示a^b mod p的值。
数据范围
0 ≤ a , b ≤ 1 0 9 0 \le a,b \le 10^9 0 ≤ a , b ≤ 1 0 9 1 ≤ p ≤ 1 0 9 1 \le p \le 10^9 1 ≤ p ≤ 1 0 9
输入样例:
输出样例:
算法分析
根据数学常识, 每一个正整数可以唯一表示为若干指数不重复的 2 的次幂的和。 也就是说, 如果 b b b k k k i ( 0 ≤ i < k ) i(0 \leq i<k) i ( 0 ≤ i < k ) c i c_{i} c i
b = c k − 1 2 k − 1 + c k − 2 2 k − 2 + ⋯ + c 0 2 0 b=c_{k-1} 2^{k-1}+c_{k-2} 2^{k-2}+\cdots+c_{0} 2^{0}
b = c k − 1 2 k − 1 + c k − 2 2 k − 2 + ⋯ + c 0 2 0
于是:
a b = a c k − 1 ∗ 2 k − 1 ∗ a c k − 2 ∗ 2 k − 2 ∗ ⋯ ∗ a c 0 ∗ 2 0 a^{b}=a^{c_{k-1} * 2^{k-1}} * a^{c_{k-2} * 2^{k-2}} * \cdots * a^{c_{0} * 2^{0}}
a b = a c k − 1 ∗ 2 k − 1 ∗ a c k − 2 ∗ 2 k − 2 ∗ ⋯ ∗ a c 0 ∗ 2 0
因为 k = ⌈ log 2 ( b + 1 ) ⌉ k=\left\lceil\log _{2}(b+1)\right\rceil k = ⌈ log 2 ( b + 1 ) ⌉ ⌈ ⌉ \lceil\;\rceil ⌈ ⌉ ⌈ log 2 ( b + 1 ) ⌉ \left\lceil\log _{2}(b+1)\right\rceil ⌈ log 2 ( b + 1 ) ⌉
a 2 i = ( a 2 i − 1 ) 2 a^{2^{i}}=\left(a^{2^{i-1}}\right)^{2}
a 2 i = ( a 2 i − 1 ) 2
所以我们很容易通过 k k k c i = 1 c_{i}=1 c i = 1 b & 1 b \& 1 b &1 b b b b ≫ 1 b \gg1 b ≫ 1 b b b c i c_{i} c i O ( log 2 b ) O\left(\log _{2} b\right) O ( log 2 b )
1 2 3 4 5 6 7 8 9 int power (int a, int b, int p) int ans = 1 ; for (; b; b >>= 1 ) { if (b & 1 ) ans = (long long )ans * a % p; a = (long long )a * a % p; } return ans; }
在上面的代码片段中, 我们通过 “右移 ( > > ) (>>) ( >> ) & \& & b b b i i i a a a a 2 i a^{2^{i}} a 2 i b b b a a a
值得提醒的是, 在 C++ 语言中, 两个数值执行算术运算时, 以参与运算 的最高数值类型为基准, 与保存结果的变量类型无关。换言之, 虽然两个 32 位整数的乘积可能超过 int 类型的表示范围,但 CPU 只会用 1 个 32 位寄存器保存结果,造成我们常说的越界现象。因此,我们必须把其中一个数强制转换成64位整数类型 long long 参与运算,从而得到正确的结果。最终对 p 取模以后,执行赋值操作时,该结果会被隐式转换成 int 存回 ans 中。从而得到正确的结果。
于是一个问题就出现了。因为 C++ 内置的最高整数类型是 64 位, 若运算 a ∗ b m o d p a*b\bmod p a ∗ b mod p a , b , p a, b, p a , b , p 1 0 18 10^{18} 1 0 18
Solution
题目描述
求 a a a b b b p p p
输入格式
第一行输入整数a a a b b b p p p
输出格式
输出一个整数,表示a*b mod p的值。
数据范围
1 ≤ a , b , p ≤ 1 0 18 1 \le a,b,p \le 10^{18} 1 ≤ a , b , p ≤ 1 0 18
输入样例:
输出样例:
算法分析
方法一
类似于快速幂的思想, 把整数 b b b b = c k − 1 2 k − 1 + c k − 2 2 k − 2 + b=c_{k-1} 2^{k-1}+c_{k-2} 2^{k-2}+ b = c k − 1 2 k − 1 + c k − 2 2 k − 2 + ⋯ + c 0 2 0 \cdots+c_{0} 2^{0} ⋯ + c 0 2 0 a ∗ b = c k − 1 ∗ a ∗ 2 k − 1 + c k − 2 ∗ a ∗ 2 k − 2 + ⋯ + c 0 ∗ a ∗ 2 0 a * b=c_{k-1} * a * 2^{k-1}+c_{k-2} * a * 2^{k-2}+\cdots+c_{0} * a * 2^{0} a ∗ b = c k − 1 ∗ a ∗ 2 k − 1 + c k − 2 ∗ a ∗ 2 k − 2 + ⋯ + c 0 ∗ a ∗ 2 0
因为 a ∗ 2 i = ( a ∗ 2 i − 1 ) ∗ 2 a * 2^{i}=\left(a * 2^{i-1}\right) * 2 a ∗ 2 i = ( a ∗ 2 i − 1 ) ∗ 2 a ∗ 2 i − 1 m o d p a * 2^{i-1} \bmod p a ∗ 2 i − 1 mod p ( a ∗ 2 i − 1 ) ∗ \left(a * 2^{i-1}\right) * ( a ∗ 2 i − 1 ) ∗ 2 m o d p 2 \bmod p 2 mod p 2 ∗ 1 0 18 2 * 10^{18} 2 ∗ 1 0 18 k k k c i = 1 c_{i}=1 c i = 1 O ( log 2 b ) \mathrm{O}\left(\log _{2} b\right) O ( log 2 b )
1 2 3 4 5 6 7 8 9 long long mul (long long a, long long b, long long p) long long ans = 0 ; for (; b; b >>= 1 ) { if (b & 1 ) ans = (ans + a) % p; a = a * 2 % p; } return ans; }
方法二
利用 a ∗ b m o d p = a ∗ b − ⌊ a ∗ b / p ⌋ ∗ p a * b \bmod p=a * b-\lfloor a * b / p\rfloor * p a ∗ b mod p = a ∗ b − ⌊ a ∗ b / p ⌋ ∗ p ⌊ ⌋ \lfloor\;\rfloor ⌊ ⌋
首先, 当 a , b < p a, b<p a , b < p a ∗ b / p a * b / p a ∗ b / p p p p a ∗ b / p a * b / p a ∗ b / p
另外, 虽然 a ∗ b a * b a ∗ b ⌊ a ∗ b / p ⌋ ∗ p \lfloor a * b / p\rfloor * p ⌊ a ∗ b / p ⌋ ∗ p 0 ∼ p − 1 0 \sim p-1 0 ∼ p − 1 a ∗ b a * b a ∗ b ⌊ a ∗ b / p ⌋ ∗ p \lfloor a * b / p\rfloor * p ⌊ a ∗ b / p ⌋ ∗ p
64位整数乘法的long double算法 1 2 3 4 5 6 7 8 9 typedef unsigned long long ull; ull mul(ull a, ull b, ull p) { a %= p, b %= p; // 当a,b一定在0~p之间时,此行不必要 ull c = (long double)a * b / p; ull x = a * b, y = c * p; long long ans = (long long)(x % p) - (long long)(y % p); if (ans < 0) ans += p; return ans; }
Solution
二进制状态压缩
二进制状态压缩, 是指将一个长度为 m m m m m m
操作 运算 取出整数 n 在二进制表示下的第 k 位 ( n ≫ k ) & 1 取出整数 n 在二进制表示下的第 0 ∼ k − 1 位 ( 后 k 位 ) n & ( ( 1 ≪ k ) − 1 ) 把整数 n 在二进制表示下的第 k 位取反 n xor ( 1 ≪ k ) 对整数 n 在二进制表示下的第 k 位赋值 1 n ∣ ( 1 ≪ k ) 对整数 n 在二进制表示下的第 k 位赋值 0 n & ( ∼ ( 1 ≪ k ) ) \begin{array}{l|l}
{\text { 操作 }} & {\text { 运算 }} \\
\hline \text { 取出整数 } n \text { 在二进制表示下的第 } k \text { 位 } & (n \gg k) \& 1 \\
\text { 取出整数 } n \text { 在二进制表示下的第 } 0 \sim k-1 \text { 位 }(\text { 后 } k \text { 位 }) & n \&((1 \ll k)-1) \\
\text { 把整数 } n \text { 在二进制表示下的第 } k \text { 位取反 } & n \text { xor }(1 \ll k) \\
\text { 对整数 } n \text { 在二进制表示下的第 } k \text { 位赋值 } 1 & n \mid(1 \ll k) \\
\text { 对整数 } n \text { 在二进制表示下的第 } k \text { 位赋值 } 0 & n \&(\sim(1 \ll k))
\end{array}
操作 取出整数 n 在二进制表示下的第 k 位 取出整数 n 在二进制表示下的第 0 ∼ k − 1 位 ( 后 k 位 ) 把整数 n 在二进制表示下的第 k 位取反 对整数 n 在二进制表示下的第 k 位赋值 1 对整数 n 在二进制表示下的第 k 位赋值 0 运算 ( n ≫ k ) &1 n & (( 1 ≪ k ) − 1 ) n xor ( 1 ≪ k ) n ∣ ( 1 ≪ k ) n & ( ∼ ( 1 ≪ k ))
这种方法运算简便, 并且节省了程序运行的时间和空问。当 m m m m m m
题目描述
给定一张 n n n 0 ∼ n − 1 0 \sim n-1 0 ∼ n − 1 0 0 0 n − 1 n-1 n − 1
Hamilton 路径的定义是从 0 0 0 n − 1 n-1 n − 1
输入格式
第一行输入整数 n n n
接下来 n n n n n n i i i j j j i i i j j j a [ i , j ] a[i,j] a [ i , j ]
对于任意的 x , y , z x,y,z x , y , z a [ x , x ] = 0 , a [ x , y ] = a [ y , x ] a[x,x]=0,a[x,y]=a[y,x] a [ x , x ] = 0 , a [ x , y ] = a [ y , x ] a [ x , y ] + a [ y , z ] ≥ a [ x , z ] a[x,y]+a[y,z] \ge a[x,z] a [ x , y ] + a [ y , z ] ≥ a [ x , z ]
输出格式
输出一个整数,表示最短 Hamilton 路径的长度。
数据范围
1 ≤ n ≤ 20 1 \le n \le 20 1 ≤ n ≤ 20 0 ≤ a [ i , j ] ≤ 1 0 7 0 \le a[i,j] \le 10^7 0 ≤ a [ i , j ] ≤ 1 0 7
输入样例:
1 2 3 4 5 6 5 0 2 4 5 1 2 0 6 5 3 4 6 0 8 3 5 5 8 0 5 1 3 3 5 0
输出样例:
算法分析
很容易想到本题的一种 “朴素” 做法, 就是枚举 n n n O ( n ∗ n ! ) O(n * n !) O ( n ∗ n !) O ( n 2 ∗ 2 n ) O\left(n^{2} * 2^{n}\right) O ( n 2 ∗ 2 n )
在任意时刻如何表示哪些点已经被经过, 哪些点没有被经过? 可以使用一个 n n n i i i ( 0 ≤ i < n ) (0 \leq i<n) ( 0 ≤ i < n ) i i i F [ i , j ] ( 0 ≤ i < 2 n , 0 ≤ F[i, j]\left(0 \leq i<2^{n}, 0 \leq\right. F [ i , j ] ( 0 ≤ i < 2 n , 0 ≤ j < n ) j<n) j < n ) i i i j j j
在起点时, 有 F [ 1 , 0 ] = 0 F[1,0]=0 F [ 1 , 0 ] = 0 i i i F F F F [ ( 1 ≪ n ) − 1 , n − 1 ] F[(1 \ll n)-1, n-1] F [( 1 ≪ n ) − 1 , n − 1 ] ( i (i ( i ) ) ) n − 1 n-1 n − 1
在任意时刻, 有公式 F [ i , j ] = min { F [ i xor ( 1 ≪ j ) , k ] + weight ( k , j ) } F[i, j]=\min \{F[i \text{ xor } (1 \ll j), k]+\operatorname{weight}(k, j)\} F [ i , j ] = min { F [ i xor ( 1 ≪ j ) , k ] + weight ( k , j )} 0 ≤ k < n 0\leq k<n 0 ≤ k < n ( ( i ≫ j ) & 1 ) = 1 ((i \gg j) \& 1)=1 (( i ≫ j ) &1 ) = 1 i i i j j j j j j j j j i xor ( 1 ≪ j ) i \text{ xor } (1 \ll j) i xor ( 1 ≪ j ) i xor ( 1 ≪ j ) i \text { xor } (1 \ll j) i xor ( 1 ≪ j ) k k k k k k j j j weight ( k , j ) \operatorname{weight}(k, j) weight ( k , j ) k k k
1 2 3 4 5 6 7 8 9 10 11 12 13 int f[1 << 20 ][20 ];int hamilton (int n, int weight[20 ][20 ]) memset (f, 0x3f , sizeof f[1 ][0 ] = 0 ; for (int i = 1 ; i < 1 << n; i++) for (int j = 0 ; j < n; j++) if (i >> j & 1 ) for (int k = 0 ; k < n; k++) if (i >> k & 1 ) f[i][j] = min (f[i][j], f[i ^ 1 << j][k] + weight[k][j]); return f[(1 << n) - 1 ][n - 1 ]; }
提醒: 一些运算符优先级从高到低的顺序如下页表所示。最需要注意的地方是: 大 小关系比较的符号优先于 “位与” “异或” “位或” 运算。在程序实现时, 如果不确定优 先级, 建议加括号保证运算顺序的正确性。
加减 移位 比较大小 位与 异或 位或 + , − ≪ , ≫ ⩾ , < , = = , ! = & xor ( C + + ∧ ) 1 \begin{array}{c|c|c|c|c|c}
\text { 加减 } & \text { 移位 } & \text { 比较大小 } & \text { 位与 } & \text { 异或 } & \text { 位或 } \\
\hline+,- & \ll, \gg & \geqslant,<,==, != & \& & \text { xor }\left(\mathrm{C}++^{\wedge}\right) & 1
\end{array}
加减 + , − 移位 ≪ , ≫ 比较大小 ⩾ , < , == , ! = 位与 & 异或 xor ( C + + ∧ ) 位或 1
Solution
题目描述
21 21 21
作为一名青春阳光好少年,atm 一直坚持与起床困难综合症作斗争。
通过研究相关文献,他找到了该病的发病原因: 在深邃的太平洋海底中,出现了一条名为 drd 的巨龙,它掌握着睡眠之精髓,能随意延长大家的睡眠时间。
正是由于 drd 的活动,起床困难综合症愈演愈烈, 以惊人的速度在世界上传播。
为了彻底消灭这种病,atm 决定前往海底,消灭这条恶龙。
历经千辛万苦,atm 终于来到了 drd 所在的地方,准备与其展开艰苦卓绝的战斗。
drd 有着十分特殊的技能,他的防御战线能够使用一定的运算来改变他受到的伤害。
具体说来,drd 的防御战线由 n n n
每扇防御门包括一个运算 o p op o p t t t O R , X O R , A N D OR,XOR,AND OR , XOR , A N D
如果还未通过防御门时攻击力为 x x x x o p t x\ op\ t x o p t
最终 drd 受到的伤害为对方初始攻击力 x x x n n n
由于 atm 水平有限,他的初始攻击力只能为 0 0 0 m m m 0 , 1 , … , m 0, 1, … , m 0 , 1 , … , m m m m
为了节省体力,他希望通过选择合适的初始攻击力使得他的攻击能让 drd 受到最大的伤害,请你帮他计算一下,他的一次攻击最多能使 drd 受到多少伤害。
输入格式
第 1 1 1 2 2 2 n , m n, m n , m n n n 0 0 0 m m m
接下来 n n n o p op o p t t t o p op o p t t t o p op o p t t t
输出格式
输出一个整数,表示 atm 的一次攻击最多使 drd 受到多少伤害。
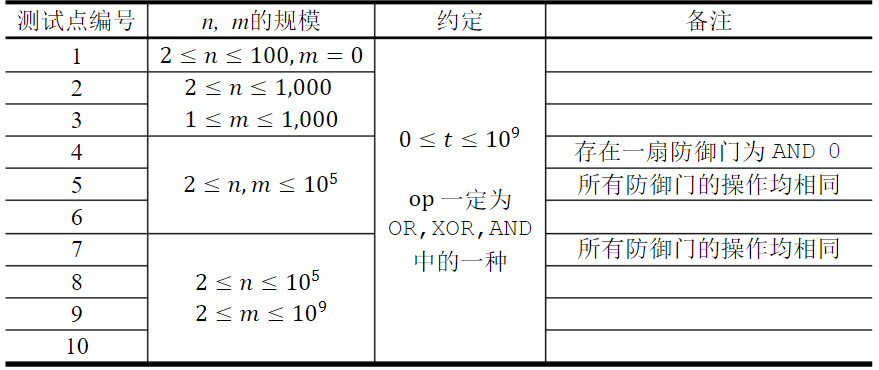
数据范围
输入样例:
输出样例:
样例解释
atm可以选择的初始攻击力为 0 , 1 , … , 10 0,1, … ,10 0 , 1 , … , 10
假设初始攻击力为 4 4 4
1 2 3 4 5 4 AND 5 = 4 4 OR 6 = 6 6 XOR 7 = 1
类似的,我们可以计算出初始攻击力为 1 , 3 , 5 , 7 , 9 1,3,5,7,9 1 , 3 , 5 , 7 , 9 0 0 0 0 , 2 , 4 , 6 , 8 , 10 0,2,4,6,8,10 0 , 2 , 4 , 6 , 8 , 10 1 1 1 1 1 1
运算解释
在本题中,选手需要先将数字变换为二进制后再进行计算。如果操作的两个数二进制长度不同,则在前补 0 0 0
OR 为按位或运算,处理两个长度相同的二进制数,两个相应的二进制位中只要有一个为 1 1 1 1 1 1 0 0 0
XOR 为按位异或运算,对等长二进制模式或二进制数的每一位执行逻辑异或操作。如果两个相应的二进制位不同(相异),则该位的结果值为 1 1 1 0 0 0
AND 为按位与运算,处理两个长度相同的二进制数,两个相应的二进制位都为 1 1 1 1 1 1 0 0 0
例如,我们将十进制数 5 5 5 3 3 3 O R 、 X O R OR、XOR OR 、 XOR A N D AND A N D
1 2 3 0101 (十进制 5) 0101 (十进制 5) 0101 (十进制 5) OR 0011 (十进制 3) XOR 0011 (十进制 3) AND 0011 (十进制 3) = 0111 (十进制 7) = 0110 (十进制 6) = 0001 (十进制 1)
算法分析
本题是让我们选择 [ 0 , m ] [0, m] [ 0 , m ] x 0 x_{0} x 0 n n n
位运算的主要特点之一是在二进制表示下不进位 。正因如此, 在 x 0 x_{0} x 0 k ( 0 ≤ k < 30 k(0 \leq k<30 k ( 0 ≤ k < 30 k k k x 0 x_{0} x 0 k k k x 0 x_{0} x 0
x 0 x_{0} x 0 k k k
已经填好的更高位构成的数值加上 1 ≪ k 1 \ll k 1 ≪ k m m m
用每个参数的第 k k k n n n n n n
如果不满足上述条件, 要么填 1 会超过 m m m x 0 x_{0} x 0 k k k x 0 x_{0} x 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <string> using namespace std;int n, m;pair<string, int > a[100005 ]; int calc (int bit, int now) for (int i = 1 ; i <= n; i++) { int x = a[i].second >> bit & 1 ; if (a[i].first == "AND" ) now &= x; else if (a[i].first == "OR" ) now |= x; else now ^= x; } return now; } int main () cin >> n >> m; for (int i = 1 ; i <= n; i++) { char str[5 ]; int x; scanf ("%s%d" , str, &x); a[i] = make_pair (str, x); } int val = 0 , ans = 0 ; for (int bit = 29 ; bit >= 0 ; bit--) { int res0 = calc (bit, 0 ); int res1 = calc (bit, 1 ); if (val + (1 << bit) <= m && res0 < res1) val += 1 << bit, ans += res1 << bit; else ans += res0 << bit; } cout << ans << endl; }
Solution
成对变换
通过计算可以发现, 对于非负整数 n : n: n :
当 n n n n n n n + 1 n+1 n + 1 n n n n n n n − 1 n-1 n − 1
因此, “ 0 与 1 ” “ 2 与 3 ” “ 4 与 5 ” ⋯ \cdots ⋯
这一性质经常用于图论邻接表中边集的存储。在具有无向边 (双向边) 的图中把一对正反方向的边分别存储在邻接表数组的第 n n n n + 1 n+1 n + 1 其中 n n n ), 就可以通过 xor 1 的运算获得与当前边 ( x , y ) (x, y) ( x , y ) ( y , x ) (y, x) ( y , x )
lowbit 运算
lowbit ( n ) \operatorname{lowbit}(n) lowbit ( n ) n n n 最低位的 1 及其后边所有的 0 ”构成的数值。例如 n = 10 n=10 n = 10 ( 1010 ) 2 (1010)_{2} ( 1010 ) 2 lowbit ( n ) = 2 = ( 10 ) 2 \operatorname{lowbit}(n)=2=(10)_{2} lowbit ( n ) = 2 = ( 10 ) 2 lowbit ( n ) \operatorname{lowbit}(n) lowbit ( n )
n = x x x x x ⋯ x x 10000 ⋯ 0000 ∼ n = x ~ x ~ x ~ x ~ x ~ ⋯ x ~ x ~ 01111 ⋯ 1111 − n = ∼ n + 1 = x ~ x ~ x ~ x ~ x ~ ⋯ x ~ x ~ 10000 ⋯ 0000 n & ( − n ) = n & ( ∼ n + 1 ) = 00000 ⋯ 00 10000 ⋯ 0000
\begin{align}
n &= &xxxxx &\cdots xx&10000 \cdots 0000\\
\sim n &= &\tilde{x}\tilde{x}\tilde{x}\tilde{x}\tilde{x} &\cdots \tilde{x}\tilde{x} &01111\cdots1111\\
-n = \;\sim n + 1 &= &\tilde{x}\tilde{x}\tilde{x}\tilde{x}\tilde{x} &\cdots \tilde{x}\tilde{x} &10000\cdots0000\\
n \;\&\; (-n) = n \;\&\; (\sim n + 1)&= &00000 &\cdots00 &10000\cdots0000
\end{align}
n ∼ n − n = ∼ n + 1 n & ( − n ) = n & ( ∼ n + 1 ) = = = = xxxxx x ~ x ~ x ~ x ~ x ~ x ~ x ~ x ~ x ~ x ~ 00000 ⋯ xx ⋯ x ~ x ~ ⋯ x ~ x ~ ⋯ 00 10000 ⋯ 0000 01111 ⋯ 1111 10000 ⋯ 0000 10000 ⋯ 0000
设 n > 0 , n n>0, n n > 0 , n k k k 0 ∼ k − 1 0 \sim k-1 0 ∼ k − 1
为了实现 lowbit 运算, 先把 n n n k k k 0 ∼ k − 1 0 \sim k-1 0 ∼ k − 1 n = n + 1 n=n+1 n = n + 1 k k k 0 ∼ k − 1 0 \sim k-1 0 ∼ k − 1
在上面的取反加 1 操作后, n n n k + 1 k+1 k + 1 n & ( ∼ n + 1 ) n \;\&\;(\sim n+1) n & ( ∼ n + 1 ) k k k ∼ n = − 1 − n \sim n=-1-n ∼ n = − 1 − n
lowbit ( n ) = n & ( ∼ n + 1 ) = n & ( − n ) \operatorname{lowbit}(n)=n \; \& \; (\sim n+1)=n \;\&\;(-n)
lowbit ( n ) = n & ( ∼ n + 1 ) = n & ( − n )
lowbit 运算配合 Hash 可以找出整数二进制表示下所有是 1 的位 , 所花费的时间与 1 的个数同级。为了达到这一目的, 我们只需不断把 n n n n − lowbit ( n ) n- \operatorname{lowbit}(n) n − lowbit ( n ) n = 0 n=0 n = 0 n = 9 = ( 1001 ) 2 n=9=(1001)_{2} n = 9 = ( 1001 ) 2 lowbit ( 9 ) = 1 \operatorname{lowbit}(9)=1 lowbit ( 9 ) = 1 n n n 9 − lowbit ( 9 ) = 8 = ( 1000 ) 2 9- \operatorname{lowbit}(9)=8=(1000)_{2} 9 − lowbit ( 9 ) = 8 = ( 1000 ) 2 lowbit ( 8 ) = 8 = ( 1000 ) 2 \operatorname{lowbit}(8)=8=(1000)_{2} lowbit ( 8 ) = 8 = ( 1000 ) 2 8 − lowbit ( 8 ) = 0 8-\operatorname{lowbit}(8)=0 8 − lowbit ( 8 ) = 0 8 = ( 1000 ) 2 8=(1000)_{2} 8 = ( 1000 ) 2 n n n log 2 1 \log _{2} 1 log 2 1 log 2 8 \log _{2} 8 log 2 8 n n n log \log log e \mathrm{e} e log \log log n n n H H H H [ 2 k ] = k H\left[2^{k}\right]=k H [ 2 k ] = k
1 2 3 4 5 6 7 8 9 10 11 12 const MAX_N = 1 << 20 ;int H[MAX_N + 1 ];for (int i = 0 ; i <= 20 ; ++i) H[1 << i] = i; while (cin >> n) { while (n > 0 ) { cout << H[n & -n] << ' ' ; n -= n & -n; } cout << endl; }
稍微复杂但效率更高的方法是建立一个长度为 37 的数组 H H H H [ 2 k m o d 37 ] = H\left[2^{k} \bmod 37\right]= H [ 2 k mod 37 ] = k k k ∀ k ∈ [ 0 , 35 ] , 2 k m o d 37 \forall k \in[0,35], 2^{k} \bmod 37 ∀ k ∈ [ 0 , 35 ] , 2 k mod 37
1 2 3 4 5 6 7 8 9 10 11 12 int H[37 ];for (int i = 0 ; i < 36 ; i++) H[(1ll << i) % 37 ] = i;while (cin >> n) { while (n > 0 ) { cout << H[(n & -n) % 37 ] << ' ' ; n -= n & -n; } cout << endl; }
值得指出的是, lowbit 运算也是树状数组中的一个基本运算。
GCC 编译器还提供了一些内置函数, 可以高效计算 lowbit 以及二进制数中 1 的个数。不过, 这些函数并非 C 语言标准, 有的函数更是与机器或编译器版本相关的。另外, 部分竞赛禁止使用下划线开头的库函数, 故这些内置函数尽量不要随便使用。
1 2 3 int __builtin_ctz(unsigned int x)int __builtin_ctzll(unsigned long long x)
1 2 3 int __builtin_popcount(unsigned int x)int __builtin_popcountll(unsigned long long x)