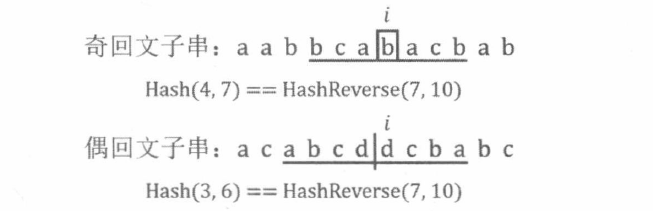参考《算法竞赛进阶指南》 、AcWing题库
1 2 3 4 5 6 7 8 9 10 struct PairHash { template <typename T, typename U> size_t operator () (const pair<T, U> &v) const { size_t seed = 0 ; seed ^= hash<T>()(v.first) + 0x9e3779b9 + (seed << 6 ) + (seed >> 2 ); seed ^= hash<U>()(v.second) + 0x9e3779b9 + (seed << 6 ) + (seed >> 2 ); return seed; } };
1 2 3 4 5 6 7 8 9 10 11 12 struct VectorHash { template <typename T> size_t operator () (const vector<T> &v) const { size_t seed = 0 ; hash<T> hasher; for (auto x : v) { seed ^= hasher (x) + 0x9e3779b9 + (seed << 6 ) + (seed >> 2 ); } return seed; } };
Hash
Hash 表又称为散列表, 一般由 Hash 函数 (散列函数) 与链表结构共同实现。与离散化思想类似, 当我们要对若干复杂信息进行统计时, 可以用 Hash 函数把这些复杂信息映射到一个容易维护的值域内。因为值域变简单、范围变小, 有可能造成两个不同的原始信息被 Hash 函数映射相同的值, 所以我们需要处理这种冲突情况。有一种称为 “开散列” 的解决方案是, 建立一个邻接表结构, 以 Hash 函数的值域作为表头数组 head, 映射后的值相同的原始信息被分到同一类, 构成一个链表接在对应的表头之后, 链表的节点上可以保存原始信息和一些统计数据。
Hash 表主要包括两个基本操作:
计算 Hash 函数的值。
定位到对应链表中依次遍历、比较。
无论是检查任意一个给定的原始信息在 Hash 表中是否存在, 还是更新它在 Hash 表中的统计数据, 都需要基于这两个基本操作进行。
当 Hash 函数设计较好时, 原始信息会被比较均匀地分配到各个表头之后, 从而使每次查找、统计的时间降低到 “原始信息总数除以表头数组长度”。若原始信息总数与表头数组长度都是 O ( N ) \mathrm{O}(N) O ( N ) O ( 1 ) O(1) O ( 1 )
例如, 我们要在一个长度为 N N N A A A A A A 建立一个大小等于值域的数组进行统计和映射, 其实就是最简单的 Hash 思想 )。当数列 A A A A A A
设计 Hash 函数为 H ( x ) = ( x m o d P ) + 1 H(x)=(x \bmod P)+1 H ( x ) = ( x mod P ) + 1 P P P N N N A A A P P P A [ i ] A[i] A [ i ] h e a d [ H ( A [ i ] ) ] head[H(A[i])] h e a d [ H ( A [ i ])] A [ i ] A[i] A [ i ] A [ i ] A[i] A [ i ] A [ i ] A[i] A [ i ] A [ i ] A[i] A [ i ] A A A A [ i ] A[i] A [ i ] O ( N ) O(N) O ( N )
上面的例子是一个非常简单的 Hash 表的直观应用。对于非随机的数列, 我们可以 设计更好的 Hash 函数来保证其时间复杂度。同样地, 如果我们需要维护的是比大整数复杂得多的信息的某些性质 (如是否存在、出现次数等), 也可以用 Hash 表来解决。 字符串就是一种比较一般化的信息, 在本节的后半部分, 我们将会介绍一个程序设计竞赛中极其常用的字符串 Hash 算法。
例题
有 N N N
第 i i i a i , 1 , a i , 2 , … , a i , 6 a_{i,1},a_{i,2},…,a_{i,6} a i , 1 , a i , 2 , … , a i , 6
因为雪花的形状是封闭的环形,所以从任何一个角开始顺时针或逆时针往后记录长度,得到的六元组都代表形状相同的雪花。
例如 a i , 1 , a i , 2 , … , a i , 6 a_{i,1},a_{i,2},…,a_{i,6} a i , 1 , a i , 2 , … , a i , 6 a i , 2 , a i , 3 , … , a i , 6 , a i , 1 a_{i,2},a_{i,3},…,a_{i,6},a_{i,1} a i , 2 , a i , 3 , … , a i , 6 , a i , 1
a i , 1 , a i , 2 , … , a i , 6 a_{i,1},a_{i,2},…,a_{i,6} a i , 1 , a i , 2 , … , a i , 6 a i , 6 , a i , 5 , … , a i , 1 a_{i,6},a_{i,5},…,a_{i,1} a i , 6 , a i , 5 , … , a i , 1
我们称两片雪花形状相同,当且仅当它们各自从某一角开始顺时针或逆时针记录长度,能得到两个相同的六元组。
求这 N N N
输入格式
第一行输入一个整数 N N N
接下来 N N N
每行包含 6 6 6
同行数值之间,用空格隔开。
输出格式
如果不存在两片形状相同的雪花,则输出:
No two snowflakes are alike.
如果存在两片形状相同的雪花,则输出:
Twin snowflakes found.
数据范围
1 ≤ N ≤ 100000 1 \le N \le 100000 1 ≤ N ≤ 100000 0 ≤ a i , j < 10000000 0 \le a_{i,j} <10000000 0 ≤ a i , j < 10000000
输入样例:
1 2 3 2 1 2 3 4 5 6 4 3 2 1 6 5
输出样例:
算法分析
定义 Hash 函数 H ( a i , 1 , a i , 2 , ⋯ , a i , 6 ) = ( ∑ j = 1 6 a i , j + ∏ j = 1 6 a i , j ) m o d P H\left(a_{i, 1}, a_{i, 2}, \cdots, a_{i, 6}\right)=\left(\sum_{j=1}^{6} a_{i, j}+\prod_{j=1}^{6} a_{i, j}\right) \bmod P H ( a i , 1 , a i , 2 , ⋯ , a i , 6 ) = ( ∑ j = 1 6 a i , j + ∏ j = 1 6 a i , j ) mod P P P P
建立一个 Hash 表, 把 N N N a i , 1 , a i , 2 , ⋯ , a i , 6 a_{i, 1}, a_{i, 2}, \cdots, a_{i, 6} a i , 1 , a i , 2 , ⋯ , a i , 6 H ( a i , 1 , a i , 2 , ⋯ , a i , 6 ) H\left(a_{i, 1}, a_{i, 2}, \cdots, a_{i, 6}\right) H ( a i , 1 , a i , 2 , ⋯ , a i , 6 ) a i , 1 , a i , 2 , ⋯ , a i , 6 a_{i, 1}, a_{i, 2}, \cdots, a_{i, 6} a i , 1 , a i , 2 , ⋯ , a i , 6 O ( N 2 / P ) O\left(N^{2} / P\right) O ( N 2 / P ) P P P N N N O ( N ) O(N) O ( N )
Solution
字符串哈希
下面介绍的字符串 Hash 函数把一个任意长度的字符串映射成一个非负整数, 并且其冲突概率几乎为零。
取一固定值 P P P P P P 。一般来说, 我们分配的数值都远小于 P P P a = 1 , b = 2 , ⋯ , z = 26 a=1, b=2, \cdots, z=26 a = 1 , b = 2 , ⋯ , z = 26 取一固定值 M M M P P P M M M 。
一般来说, 我们取 P = 131 P=131 P = 131 P = 13331 P=13331 P = 13331 M = 2 64 M=2^{64} M = 2 64 直接使用 unsigned long long 类型 存储这个 Hash 值, 在计算时不处理算术溢出问题, 产生溢出时相当于自动对 2 64 2^{64} 2 64
除了在极特殊构造的数据上, 上述 Hash 算法很难产生冲突, 一般情况下上述 Hash 算法完全可以出现在题目的标准解答中。我们还可以多取一些恰当的 P P P M M M
对字符串的各种操作, 都可以直接对 P P P S S S H ( S ) H(S) H ( S ) S S S c c c S + c S+c S + c H ( S + c ) = ( H ( S ) ∗ P + v a l u e [ c ] ) m o d M H(S+c)=(H(S) * P+ value [c]) \bmod M H ( S + c ) = ( H ( S ) ∗ P + v a l u e [ c ]) mod M P P P P P P v a l u e [ c ] value [c] v a l u e [ c ] c c c
如果我们已知字符串 S S S H ( S ) H(S) H ( S ) S + T S+T S + T H ( S + H(S+ H ( S + T T T T T T H ( T ) = ( H ( S + T ) − H ( S ) ∗ P length ( T ) ) m o d M H(T)=\left(H(S+T)-H(S) * P^{\text {length }(T)}\right) \bmod M H ( T ) = ( H ( S + T ) − H ( S ) ∗ P length ( T ) ) mod M P P P S S S S S S S + T S+T S + T H ( T ) H(T) H ( T )
例如, S = “abc" S=\text{``abc"} S = “abc" c = “d" c=\text{``d"} c = “d" T = “xyz" T=\text{``xyz"} T = “xyz"
S S S P P P
H ( S ) = 1 ∗ P 2 + 2 ∗ P + 3 H(S)=1 * P^{2}+2 * P+3 H ( S ) = 1 ∗ P 2 + 2 ∗ P + 3
H ( S + c ) = 1 ∗ P 3 + 2 ∗ P 2 + 3 ∗ P + 4 = H ( S ) ∗ P + 4 H(S+c)=1 * P^{3}+2 * P^{2}+3 * P+4=H(S) * P+4 H ( S + c ) = 1 ∗ P 3 + 2 ∗ P 2 + 3 ∗ P + 4 = H ( S ) ∗ P + 4
S + T S+T S + T P P P
H ( S + T ) = 1 ∗ P 5 + 2 ∗ P 4 + 3 ∗ P 3 + 24 ∗ P 2 + 25 ∗ P + 26 H(S+T)=1 * P^{5}+2 * P^{4}+3 * P^{3}+24 * P^{2}+25 * P+26 H ( S + T ) = 1 ∗ P 5 + 2 ∗ P 4 + 3 ∗ P 3 + 24 ∗ P 2 + 25 ∗ P + 26
S S S P P P l e n g t h ( T ) length(T) l e n g t h ( T )
二者相减就是 T T T P P P
H ( T ) = ( H ( S + T ) − H ( S ) ∗ P length ( T ) ) = H ( S + T ) − ( 1 ∗ P 2 + 2 ∗ P + 3 ) ∗ P 3 = 24 ∗ P 2 + 25 ∗ P + 26 H(T)=\left(H(S+T)-H(S) * P^{\text {length }(T)}\right)=H(S+T)-\left(1 * P^{2}+2 * P+3\right) * P^{3}=24 * P^{2}+25 * P+26 H ( T ) = ( H ( S + T ) − H ( S ) ∗ P length ( T ) ) = H ( S + T ) − ( 1 ∗ P 2 + 2 ∗ P + 3 ) ∗ P 3 = 24 ∗ P 2 + 25 ∗ P + 26
根据上面两种操作, 我们可以通过 O ( N ) O(N) O ( N ) O ( 1 ) O(1) O ( 1 ) 。
字符串哈希例题
很久很久以前,森林里住着一群兔子。
有一天,兔子们想要研究自己的 DNA 序列。
我们首先选取一个好长好长的 DNA 序列(小兔子是外星生物,DNA 序列可能包含 26 26 26
然后我们每次选择两个区间,询问如果用两个区间里的 DNA 序列分别生产出来两只兔子,这两个兔子是否一模一样。
注意两个兔子一模一样只可能是他们的 DNA 序列一模一样。
输入格式
第一行输入一个 DNA 字符串 S S S
第二行一个数字 m m m m m m
接下来 m m m l 1 , r 1 , l 2 , r 2 l_1, r_1, l_2, r_2 l 1 , r 1 , l 2 , r 2 1 1 1
输出格式
对于每次询问,输出一行表示结果。
如果两只兔子完全相同输出 Yes,否则输出 No(注意大小写)。
数据范围
1 ≤ l e n g t h ( S ) , m ≤ 1000000 1 \le length(S),m \le 1000000 1 ≤ l e n g t h ( S ) , m ≤ 1000000
输入样例:
1 2 3 4 5 aabbaabb 3 1 3 5 7 1 3 6 8 1 2 1 2
输出样例:
算法分析
记我们选取的 DNA 序列为 S S S F [ i ] F[i] F [ i ] S [ 1 ∼ i ] S[1 \sim i] S [ 1 ∼ i ] F [ i ] = F [ i − 1 ] ∗ 131 + ( S [ i ] − ‘a’ + 1 ) F[i]=F[i-1] * 131+\left(S[i]- \text{`a'} +1\right) F [ i ] = F [ i − 1 ] ∗ 131 + ( S [ i ] − ‘a’ + 1 )
于是可以得到任一区间 [ l , r ] [l, r] [ l , r ] F [ r ] − F [ l − 1 ] ∗ 13 1 r − l + 1 F[r]-F[l-1] * 131^{r-l+1} F [ r ] − F [ l − 1 ] ∗ 13 1 r − l + 1 O ( ∣ S ∣ + Q ) \mathrm{O}(|S|+Q) O ( ∣ S ∣ + Q )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> using namespace std;char s[1000010 ]; unsigned long long f[1000010 ], p[1000010 ];int main () scanf ("%s" , s + 1 ); int n, q; n = strlen (s + 1 ); cin >> q; p[0 ] = 1 ; for (int i = 1 ; i <= n; i++) { f[i] = f[i-1 ] * 131 + (s[i]-'a' +1 ); p[i] = p[i-1 ] * 131 ; } for (int i = 1 ; i <= q; i++) { int l1, r1, l2, r2; scanf ("%d%d%d%d" , &l1, &r1, &l2, &r2); if (f[r1] - f[l1-1 ] * p[r1-l1+1 ] == f[r2] - f[l2-1 ] * p[r2-l2+1 ]) { puts ("Yes" ); } else { puts ("No" ); } } }
Solution
如果一个字符串正着读和倒着读是一样的,则称它是回文的。
给定一个长度为 N N N S S S
输入格式
输入将包含最多 30 30 30 1000000 1000000 1000000
输入以一个以字符串 END 开头的行表示输入终止。
输出格式
对于输入中的每个测试用例,输出测试用例编号和最大回文子串的长度(参考样例格式)。
每个输出占一行。
输入样例:
1 2 3 abcbabcbabcba abacacbaaaab END
输出样例:
算法分析
写几个回文串观察它们的性质, 我们可以发现回文串分为两类:
奇回文串 A [ 1 ∼ M ] A[1 \sim M] A [ 1 ∼ M ] M M M A [ 1 ∼ M / 2 + 1 ] = reverse ( A [ M / 2 + 1 ∼ M ] ) A[1 \sim M / 2+1]=\operatorname{reverse}(A[M / 2+1 \sim M]) A [ 1 ∼ M /2 + 1 ] = reverse ( A [ M /2 + 1 ∼ M ]) reverse ( A ) \operatorname{reverse}(A) reverse ( A ) A \mathrm{A} A
偶回文串 B [ 1 ∼ M ] B[1 \sim M] B [ 1 ∼ M ] M M M B [ 1 ∼ M / 2 ] = reverse ( B [ M / 2 + 1 ∼ M ] ) B[1 \sim M / 2]=\operatorname{reverse}(B[M / 2+1 \sim M]) B [ 1 ∼ M /2 ] = reverse ( B [ M /2 + 1 ∼ M ])
于是在本题中, 我们可以枚举 S S S i = 1 ∼ N i=1 \sim N i = 1 ∼ N
求出一个最大的整数 p p p S [ i − p ∼ i ] = reverse ( S [ i ∼ i + p ] ) S[i-p \sim i]=\operatorname{reverse}(S[i \sim i+p]) S [ i − p ∼ i ] = reverse ( S [ i ∼ i + p ]) i i i 2 ∗ p + 1 2 * p+1 2 ∗ p + 1
求出一个最大的整数 q q q S [ i − q ∼ i − 1 ] = reverse ( S [ i ∼ i + q − 1 ] ) S[i-q \sim i-1]=\operatorname{reverse}(S[i \sim i+q-1]) S [ i − q ∼ i − 1 ] = reverse ( S [ i ∼ i + q − 1 ]) i − 1 i-1 i − 1 i i i 2 ∗ q 2 * q 2 ∗ q
根据上一道题目, 我们已经知道在 O ( N ) O(N) O ( N ) O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 ) p p p q q q O ( 1 ) \mathrm{O}(1) O ( 1 ) O ( log N ) \mathrm{O}(\log N) O ( log N ) p p p q q q O ( N log N ) \mathrm{O}(N \log N) O ( N log N )
有一个名为 Manacher 的算法可以 O ( N ) O(N) O ( N )
Solution
后缀数组 (SA,Suffix Array) 是一种重要的数据结构,通常使用倍增或者 DC3 算法实现,这超出了我们的讨论范围。
在本题中,我们希望使用快排、Hash 与二分实现一个简单的 O ( n l o g 2 n ) O(nlog^2n) O ( n l o g 2 n )
详细地说,给定一个长度为 n n n S S S 0 ∼ n − 1 0 \sim n-1 0 ∼ n − 1 k k k 0 ≤ k < n 0 \le k < n 0 ≤ k < n S S S S ( k ∼ n − 1 ) S(k \sim n-1) S ( k ∼ n − 1 )
把字符串 S S S i i i S A [ i ] SA[i] S A [ i ]
额外地,我们考虑排名为 i i i i − 1 i-1 i − 1 H e i g h t [ i ] Height[i] He i g h t [ i ]
我们的任务就是求出 S A SA S A H e i g h t Height He i g h t
输入格式
输入一个字符串,其长度不超过 30 30 30
字符串由小写字母构成。
输出格式
第一行为数组 S A SA S A 1 1 1
第二行为数组 H e i g h t Height He i g h t 1 1 1 H e i g h t [ 1 ] = 0 Height[1]=0 He i g h t [ 1 ] = 0
输入样例:
输出样例:
1 2 9 4 5 6 2 8 3 1 7 0 0 1 2 1 0 0 2 1 0 2
算法分析
S S S O ( n 2 ) O\left(n^{2}\right) O ( n 2 ) n n n O ( n 2 log n ) O\left(n^{2} \log n\right) O ( n 2 log n )
在上一道题目中, 我们已经知道如何求出一个字符串的所有前缀 Hash 值, 并进一步在 O ( 1 ) O(1) O ( 1 ) p p p q q q O ( 1 ) O(1) O ( 1 ) S [ p ∼ p + m i d − 1 ] S[p \sim p+m i d-1] S [ p ∼ p + mi d − 1 ] S [ q ∼ q + m i d − 1 ] S[q \sim q+m i d-1] S [ q ∼ q + mi d − 1 ] S [ p ∼ n ] S[p \sim n] S [ p ∼ n ] S [ q ∼ n ] S[q \sim n] S [ q ∼ n ] l e n len l e n S [ p + l e n ] S[p+l e n] S [ p + l e n ] S [ q + l e n ] S[q+l e n] S [ q + l e n ] S [ p ∼ n ] S[p \sim n] S [ p ∼ n ] S [ q ∼ n ] S[q \sim n] S [ q ∼ n ] O ( log n ) O(\log n) O ( log n ) S A SA S A O ( n log 2 n ) O\left(n \log ^{2} n\right) O ( n log 2 n ) H e i g h t Height He i g h t
Solution