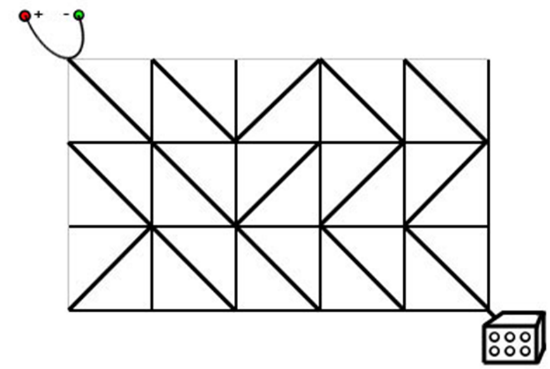
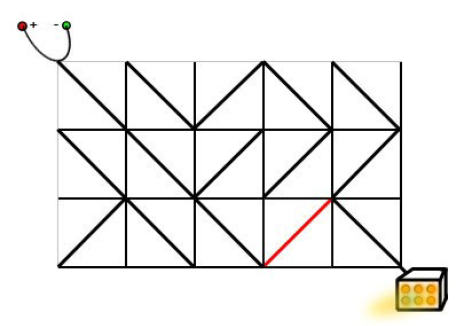
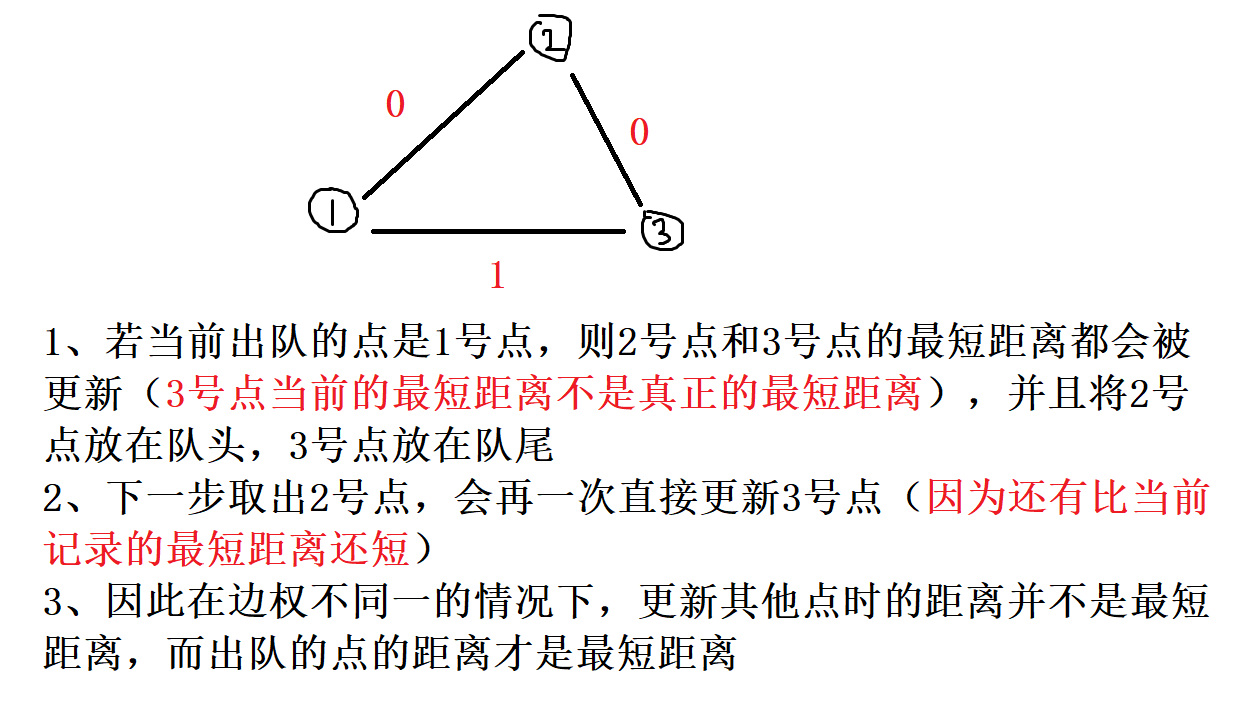
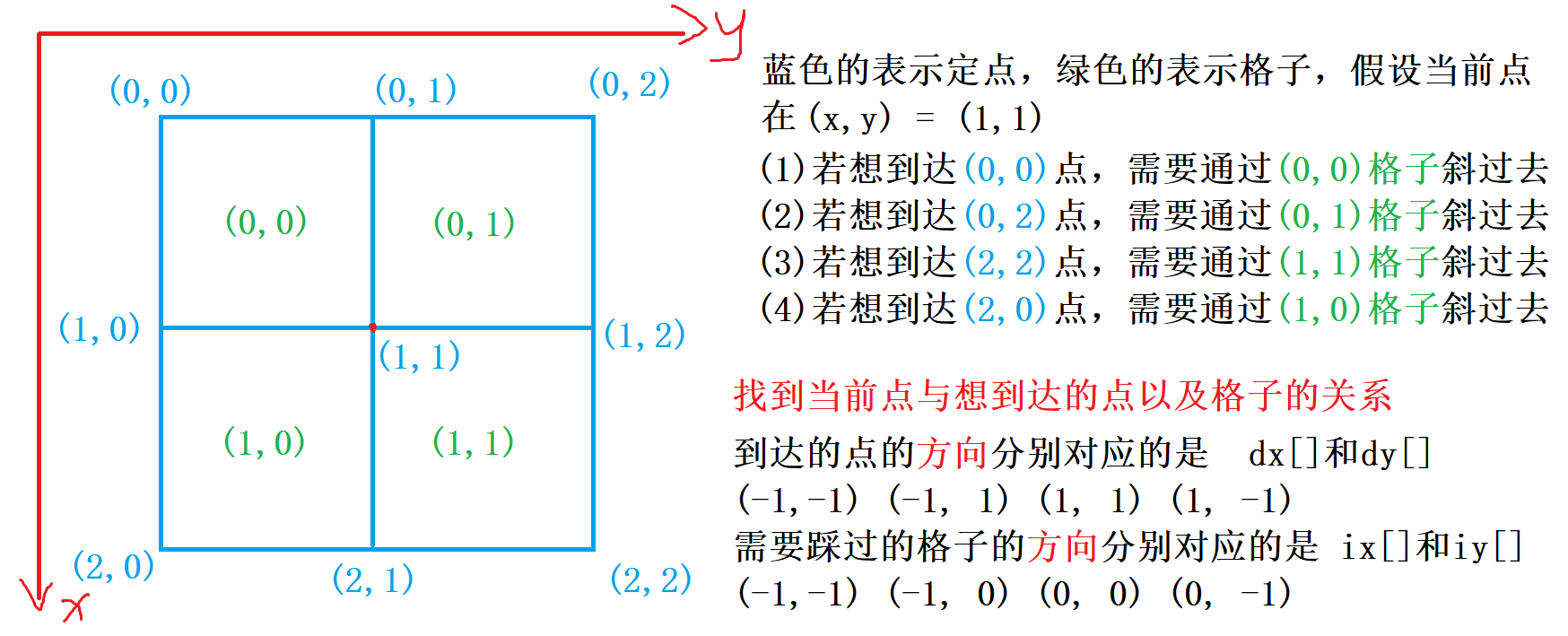
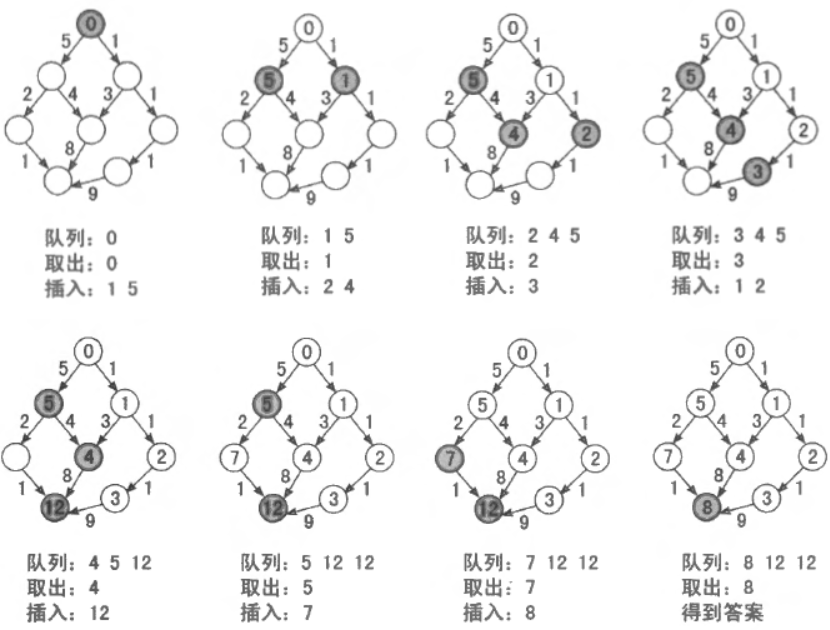
我们可以把电路板上的每个格点 (横线与坚线的交叉点) 看作无向图中的节点。若两个节点 x 和 y 是某个小方格的两个对角, 则在 x 与 y 之间连边。若该方格中的标准件 (对角线) 与 x 到 y 的线段重合, 则边权为 0 ; 若垂直相交, 则边权为 1 (说明需要旋转 1 次才能连上)。然后, 我们在这个无向图中求出左上角到右下角的最短距离, 就得到了答案。
#include<queue> #include<cstdio> #include<vector> #include<cstring> #include<iostream> #include<algorithm> usingnamespace std; constint N = 1006, C = 106; int n, m, p[N], d[N][C]; bool v[N][C]; vector<pair<int, int> > e[N]; priority_queue<pair<int, pair<int, int> > > q;
voidFull_Tank(){ int c, st, ed; scanf("%d %d %d", &c, &st, &ed); priority_queue<pair<int, pair<int, int> > > empty; swap(q, empty); memset(d, 0x3f, sizeof(d)); q.push(make_pair(0, make_pair(st, 0))); d[st][0] = 0; memset(v, 0, sizeof(v)); while (q.size()) { int city = q.top().second.first; int fuel = q.top().second.second; q.pop(); if (city == ed) { cout << d[city][fuel] << endl; return; } if (v[city][fuel]) continue; v[city][fuel] = 1; if (fuel < c && d[city][fuel+1] > d[city][fuel] + p[city]) { d[city][fuel+1] = d[city][fuel] + p[city]; q.push(make_pair(-d[city][fuel] - p[city], make_pair(city, fuel + 1))); } for (unsignedint i = 0; i < e[city].size(); i++) { int y = e[city][i].first, z = e[city][i].second; if (z <= fuel && d[y][fuel-z] > d[city][fuel]) { d[y][fuel-z] = d[city][fuel]; q.push(make_pair(-d[city][fuel], make_pair(y, fuel - z))); } } } cout << "impossible" << endl; }
intmain(){ cin >> n >> m; for (int i = 0; i < n; i++) scanf("%d", &p[i]); for (int i = 1; i <= m; i++) { int u, v, d; scanf("%d %d %d", &u, &v, &d); e[u].push_back(make_pair(v, d)); e[v].push_back(make_pair(u, d)); } int q; cin >> q; while (q--) Full_Tank(); return0; }
#include<queue> #include<cmath> #include<cstring> #include<iostream> usingnamespace std; constint N = 806; char s[N][N]; bool v1[N][N], v2[N][N]; int n, m, bx, by, gx, gy, px, py, qx, qy, s1, s2; int dx[4] = {0,0,-1,1}; int dy[4] = {-1,1,0,0};
boolpd(int x, int y, int k){ if (x <= 0 || x > n || y <= 0 || y > m) return0; if (abs(x - px) + abs(y - py) <= 2 * k) return0; if (abs(x - qx) + abs(y - qy) <= 2 * k) return0; if (s[x][y] == 'X') return0; return1; }
intbfs(){ queue<pair<int, int> > q1, q2; px = 0; for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j++) if (s[i][j] == 'M') { bx = i; by = j; } elseif (s[i][j] == 'G') { gx = i; gy = j; } elseif (s[i][j] == 'Z') { if (!px) { px = i; py = j; } else { qx = i; qy = j; } } int ans = 0; memset(v1, 0, sizeof(v1)); memset(v2, 0, sizeof(v2)); v1[bx][by] = 1; v2[gx][gy] = 1; q1.push(make_pair(bx, by)); q2.push(make_pair(gx, gy)); while (q1.size() || q2.size()) { ans++; s1 = q1.size(); for (int i = 1; i <= s1; i++) { pair<int, int> now = q1.front(); q1.pop(); if (!pd(now.first,now.second,ans)) continue; for (int j = 0; j < 4; j++) { int nx = now.first + dx[j]; int ny = now.second + dy[j]; if (pd(nx,ny,ans) && !v1[nx][ny]) { v1[nx][ny] = 1; q1.push(make_pair(nx, ny)); } } } s1 = q1.size(); for (int i = 1; i <= s1; i++) { pair<int, int> now = q1.front(); q1.pop(); if (!pd(now.first,now.second,ans)) continue; for (int j = 0; j < 4; j++) { int nx = now.first + dx[j]; int ny = now.second + dy[j]; if (pd(nx,ny,ans) && !v1[nx][ny]) { v1[nx][ny] = 1; q1.push(make_pair(nx, ny)); } } } s1 = q1.size(); for (int i = 1; i <= s1; i++) { pair<int, int> now = q1.front(); q1.pop(); if (!pd(now.first,now.second,ans)) continue; for (int j = 0; j < 4; j++) { int nx = now.first + dx[j]; int ny = now.second + dy[j]; if (pd(nx,ny,ans) && !v1[nx][ny]) { v1[nx][ny] = 1; q1.push(make_pair(nx, ny)); } } } s2 = q2.size(); for (int i = 1; i <= s2; i++) { pair<int, int> now = q2.front(); q2.pop(); if (!pd(now.first,now.second,ans)) continue; for (int j = 0; j < 4; j++) { int nx = now.first + dx[j]; int ny = now.second + dy[j]; if (pd(nx,ny,ans) && !v2[nx][ny]) { if (v1[nx][ny]) return ans; v2[nx][ny] = 1; q2.push(make_pair(nx, ny)); } } } } return-1; }
intmain(){ int t; cin >> t; while (t--) { cin >> n >> m; for (int i = 1; i <= n; i++) scanf("%s", s[i] + 1); cout << bfs() << endl; } return0; }