前缀和
前缀和是一种重要的预处理,能大大降低查询的时间复杂度。可以简单理解为“数列的前 n n n
C++ 标准库中实现了前缀和函数 std::partial_sum<numeric> 中。
例题
有 N N N A A A B B B i i i B [ i ] B[i] B [ i ] A A A 0 0 0 i i i
输入
输出 :
解题思路
递推:B[0] = A[0],对于 i ≥ 1 i \ge 1 i ≥ 1 B[i] = B[i-1] + A[i]。
参考代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> using namespace std;int N, A[10000 ], B[10000 ];int main () cin >> N; for (int i = 0 ; i < N; i++) { cin >> A[i]; } B[0 ] = A[0 ]; for (int i = 1 ; i < N; i++) { B[i] = B[i - 1 ] + A[i]; } for (int i = 0 ; i < N; i++) { cout << B[i] << " " ; } return 0 ; }
二维/多维前缀和
多维前缀和的普通求解方法几乎都是基于容斥原理。
示例:一维前缀和扩展到二维前缀和
比如我们有这样一个矩阵 a a a
我们定义一个矩阵 sum \textit{sum} sum sum x , y = ∑ i = 1 x ∑ j = 1 y a i , j \textit{sum}_{x,y} = \sum\limits_{i=1}^x \sum\limits_{j=1}^y a_{i,j} sum x , y = i = 1 ∑ x j = 1 ∑ y a i , j
那么这个矩阵长这样:
1 2 3 1 3 7 10 6 9 15 22 12 18 29 45
第一个问题就是递推求 sum \textit{sum} sum sum i , j = sum i − 1 , j + sum i , j − 1 − sum i − 1 , j − 1 + a i , j \textit{sum}_{i,j} = \textit{sum}_{i - 1,j} + \textit{sum}_{i,j - 1} - \textit{sum}_{i - 1,j - 1} + a_{i,j} sum i , j = sum i − 1 , j + sum i , j − 1 − sum i − 1 , j − 1 + a i , j
因为同时加了 sum i − 1 , j \textit{sum}_{i - 1,j} sum i − 1 , j sum i , j − 1 \textit{sum}_{i,j - 1} sum i , j − 1 sum i − 1 , j − 1 \textit{sum}_{i - 1,j - 1} sum i − 1 , j − 1
第二个问题就是如何应用,譬如求 ( x 1 , y 1 ) − ( x 2 , y 2 ) (x_1,y_1) - (x_2,y_2) ( x 1 , y 1 ) − ( x 2 , y 2 )
那么,根据类似的思考过程,易得答案为 sum x 2 , y 2 − sum x 1 − 1 , y 2 − s u m x 2 , y 1 − 1 + s u m x 1 − 1 , y 1 − 1 \textit{sum}_{x_2,y_2} - \textit{sum}_{x_1 - 1,y_2} - sum_{x_2,y_1 - 1} + sum_{x_1 - 1,y_1 - 1} sum x 2 , y 2 − sum x 1 − 1 , y 2 − s u m x 2 , y 1 − 1 + s u m x 1 − 1 , y 1 − 1
在一个 n × m n\times m n × m 0 0 0 1 1 1 0 0 0
参考代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <algorithm> #include <iostream> using namespace std;int a[103 ][103 ];int b[103 ][103 ]; int main () int n, m; cin >> n >> m; for (int i = 1 ; i <= n; i++) { for (int j = 1 ; j <= m; j++) { cin >> a[i][j]; b[i][j] = b[i][j - 1 ] + b[i - 1 ][j] - b[i - 1 ][j - 1 ] + a[i][j]; } } int ans = 1 ; int l = 2 ; while (l <= min (n, m)) { for (int i = l; i <= n; i++) { for (int j = l; j <= m; j++) { if (b[i][j] - b[i - l][j] - b[i][j - l] + b[i - l][j - l] == l * l) { ans = max (ans, l); } } } l++; } cout << ans << endl; return 0 ; }
基于 DP 计算高维前缀和
基于容斥原理来计算高维前缀和的方法,其优点在于形式较为简单,无需特别记忆,但当维数升高时,其复杂度较高。这里介绍一种基于 DP 计算高维前缀和的方法。该方法即通常语境中所称的 高维前缀和 。
设高维空间 U U U D D D f [ ⋅ ] f[\cdot] f [ ⋅ ] sum [ ⋅ ] \text{sum}[\cdot] sum [ ⋅ ] sum [ i ] [ state ] \text{sum}[i][\text{state}] sum [ i ] [ state ] state \text{state} state D − i D - i D − i state \text{state} state sum [ 0 ] [ state ] = f [ state ] \text{sum}[0][\text{state}] = f[\text{state}] sum [ 0 ] [ state ] = f [ state ] sum [ state ] = sum [ D ] [ state ] \text{sum}[\text{state}] = \text{sum}[D][\text{state}] sum [ state ] = sum [ D ] [ state ]
其递推关系为 sum [ i ] [ state ] = sum [ i − 1 ] [ state ] + sum [ i ] [ state ′ ] \text{sum}[i][\text{state}] = \text{sum}[i - 1][\text{state}] + \text{sum}[i][\text{state}'] sum [ i ] [ state ] = sum [ i − 1 ] [ state ] + sum [ i ] [ state ′ ] state ′ \text{state}' state ′ i i i state \text{state} state 1 1 1 O ( D × ∣ U ∣ ) O(D \times |U|) O ( D × ∣ U ∣ ) ∣ U ∣ |U| ∣ U ∣ U U U
一种实现的伪代码如下:
for state
sum[state] = f[state];
for(i = 0;i <= D;i += 1)
for 以字典序从小到大枚举 state
sum[state] += sum[state'];
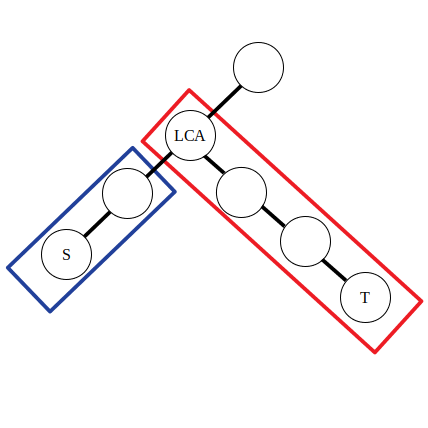
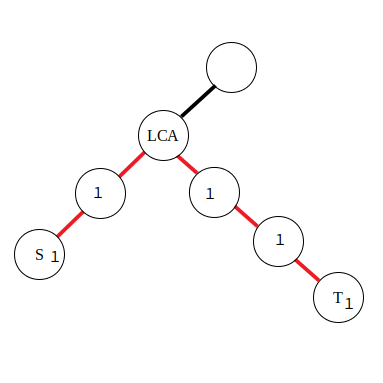
树上前缀和
设 sum i \textit{sum}_i sum i i i i
若是点权,x , y x,y x , y sum x + sum y − sum lca − sum fa lca \textit{sum}_x + \textit{sum}_y - \textit{sum}_\textit{lca} - \textit{sum}_{\textit{fa}_\textit{lca}} sum x + sum y − sum lca − sum fa lca
若是边权,x , y x,y x , y sum x + sum y − 2 ⋅ sum l c a \textit{sum}_x + \textit{sum}_y - 2\cdot\textit{sum}_{lca} sum x + sum y − 2 ⋅ sum l c a
LCA 的求法参见 最近公共祖先 。
差分
普通差分
差分是一种和前缀和相对的策略,可以当做是求和的逆运算。
这种策略的定义是令 b i = { a i − a i − 1 i ∈ [ 2 , n ] a 1 i = 1 b_i=\begin{cases}a_i-a_{i-1}\,&i \in[2,n] \\ a_1\,&i=1\end{cases} b i = { a i − a i − 1 a 1 i ∈ [ 2 , n ] i = 1
简单性质:
a i a_i a i b i b_i b i a n = ∑ i = 1 n b i a_n=\sum\limits_{i=1}^nb_i a n = i = 1 ∑ n b i 计算 a i a_i a i s u m = ∑ i = 1 n a i = ∑ i = 1 n ∑ j = 1 i b j = ∑ i n ( n − i + 1 ) b i = ( n + 1 ) ∑ i n b i − ∑ i n i b i sum=\sum\limits_{i=1}^na_i=\sum\limits_{i=1}^n\sum\limits_{j=1}^{i}b_j=\sum\limits_{i}^n(n-i+1)b_i=(n+1)\sum\limits_{i}^{n}b_i-\sum\limits_{i}^nib_i s u m = i = 1 ∑ n a i = i = 1 ∑ n j = 1 ∑ i b j = i ∑ n ( n − i + 1 ) b i = ( n + 1 ) i ∑ n b i − i ∑ n i b i
它可以维护多次对序列的一个区间加上一个数,并在最后询问某一位的数或是多次询问某一位的数。注意修改操作一定要在查询操作之前。
示例
譬如使 [ l , r ] [l,r] [ l , r ] k k k
b l ← b l + k b r + 1 ← b r + 1 − k \begin{align*}
b_l &\leftarrow b_l + k\\
b_{r + 1} &\leftarrow b_{r + 1} - k
\end{align*}
b l b r + 1 ← b l + k ← b r + 1 − k
其中
b l + k = a l + k − a l − 1 b r + 1 − k = a r + 1 − ( a r + k ) \begin{align*}
b_l+k&=a_l+k-a_{l-1}\\
b_{r+1}-k&=a_{r+1}-(a_r+k)
\end{align*}
b l + k b r + 1 − k = a l + k − a l − 1 = a r + 1 − ( a r + k )
最后做一遍前缀和就好了。
C++ 标准库中实现了差分函数 std::adjacent_difference<numeric> 中。
一维差分代码
1 2 3 4 5 6 7 8 9 10 11 void insert (int l, int r, int c) B[l] += c; B[r + 1 ] -= c; } for (int i = 1 ; i <= n; ++i) { cin >> a[i]; add (i, i, a[i]); }
二维差分代码
1 2 3 4 5 6 7 void insert (int x1, int y1, int x2, int y2, int c) b[x1][y1] += c; b[x1][y2 + 1 ] -= c; b[x2 + 1 ][y1] -= c; b[x2 + 1 ][y2 + 1 ] += c; }
树上差分
树上差分可以理解为对树上的某一段路径进行差分操作,这里的路径可以类比一维数组的区间进行理解。例如在对树上的一些路径进行频繁操作,并且询问某条边或者某个点在经过操作后的值的时候,就可以运用树上差分思想了。
树上差分通常会结合 树基础 和 最近公共祖先 来进行考察。树上差分又分为 点差分 与 边差分 ,在实现上会稍有不同。
点差分
举例:对域树上的一些路径 δ ( s 1 , t 1 ) , δ ( s 2 , t 2 ) , δ ( s 3 , t 3 ) … \delta(s_1,t_1), \delta(s_2,t_2), \delta(s_3,t_3)\dots δ ( s 1 , t 1 ) , δ ( s 2 , t 2 ) , δ ( s 3 , t 3 ) … δ ( s , t ) \delta(s,t) δ ( s , t )
对于一次 δ ( s , t ) \delta(s,t) δ ( s , t ) s s s t t t
d s ← d s + 1 d l c a ← d lca − 1 d t ← d t + 1 d f ( lca ) ← d f ( lca ) − 1 \begin{aligned}
&d_s\leftarrow d_s+1\\
&d_{lca}\leftarrow d_{\textit{lca}}-1\\
&d_t\leftarrow d_t+1\\
&d_{f(\textit{lca})}\leftarrow d_{f(\textit{lca})}-1\\
\end{aligned}
d s ← d s + 1 d l c a ← d lca − 1 d t ← d t + 1 d f ( lca ) ← d f ( lca ) − 1
其中 f ( x ) f(x) f ( x ) x x x d i d_i d i a i a_i a i
可以认为公式中的前两条是对蓝色方框内的路径进行操作,后两条是对红色方框内的路径进行操作。不妨令 lca \textit{lca} lca left \textit{left} left d lca − 1 = a lca − ( a left + 1 ) d_{\textit{lca}}-1=a_{\textit{lca}}-(a_{\textit{left}}+1) d lca − 1 = a lca − ( a left + 1 ) d f ( lca ) − 1 = a f ( lca ) − ( a lca + 1 ) d_{f(\textit{lca})}-1=a_{f(\textit{lca})}-(a_{\textit{lca}}+1) d f ( lca ) − 1 = a f ( lca ) − ( a lca + 1 )
边差分
若是对路径中的边进行访问,就需要采用边差分策略了,使用以下公式:
d s ← d s + 1 d t ← d t + 1 d lca ← d lca − 2 \begin{aligned}
&d_s\leftarrow d_s+1\\
&d_t\leftarrow d_t+1\\
&d_{\textit{lca}}\leftarrow d_{\textit{lca}}-2\\
\end{aligned}
d s ← d s + 1 d t ← d t + 1 d lca ← d lca − 2
由于在边上直接进行差分比较困难,所以将本来应当累加到红色边上的值向下移动到附近的点里,那么操作起来也就方便了。对于公式,有了点差分的理解基础后也不难推导,同样是对两段区间进行差分。
FJ 给他的牛棚的 N ( 2 ≤ N ≤ 50 , 000 ) N(2 \le N \le 50,000) N ( 2 ≤ N ≤ 50 , 000 ) N − 1 N-1 N − 1 1 1 1 N N N K ( 1 ≤ K ≤ 100 , 000 ) K(1 \le K \le 100,000) K ( 1 ≤ K ≤ 100 , 000 ) i i i s i s_i s i t i t_i t i
解题思路
参考代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <bits/stdc++.h> using namespace std;#define maxn 50010 struct node { int to, next; } edge[maxn << 1 ]; int fa[maxn][30 ], head[maxn << 1 ];int power[maxn];int depth[maxn], lg[maxn];int n, k, ans = 0 , tot = 0 ;void add (int x, int y) edge[++tot].to = y; edge[tot].next = head[x]; head[x] = tot; } void dfs (int now, int father) fa[now][0 ] = father; depth[now] = depth[father] + 1 ; for (int i = 1 ; i <= lg[depth[now]]; ++i) fa[now][i] = fa[fa[now][i - 1 ]][i - 1 ]; for (int i = head[now]; i; i = edge[i].next) if (edge[i].to != father) dfs (edge[i].to, now); } int lca (int x, int y) if (depth[x] < depth[y]) swap (x, y); while (depth[x] > depth[y]) x = fa[x][lg[depth[x] - depth[y]] - 1 ]; if (x == y) return x; for (int k = lg[depth[x]] - 1 ; k >= 0 ; k--) { if (fa[x][k] != fa[y][k]) x = fa[x][k], y = fa[y][k]; } return fa[x][0 ]; } void get_ans (int u, int father) for (int i = head[u]; i; i = edge[i].next) { int to = edge[i].to; if (to == father) continue ; get_ans (to, u); power[u] += power[to]; } ans = max (ans, power[u]); } int main () scanf ("%d %d" , &n, &k); int x, y; for (int i = 1 ; i <= n; i++) { lg[i] = lg[i - 1 ] + (1 << lg[i - 1 ] == i); } for (int i = 1 ; i <= n - 1 ; i++) { scanf ("%d %d" , &x, &y); add (x, y); add (y, x); } dfs (1 , 0 ); int s, t; for (int i = 1 ; i <= k; i++) { scanf ("%d %d" , &s, &t); int ancestor = lca (s, t); power[s]++; power[t]++; power[ancestor]--; power[fa[ancestor][0 ]]--; } get_ans (1 , 0 ); printf ("%d\n" , ans); return 0 ; }
习题
前缀和
二维/多维前缀和
树上前缀和
差分
树上差分