
计算机网络知识点笔记
计算机网络97问
1. TCP报文格式及首部含义?
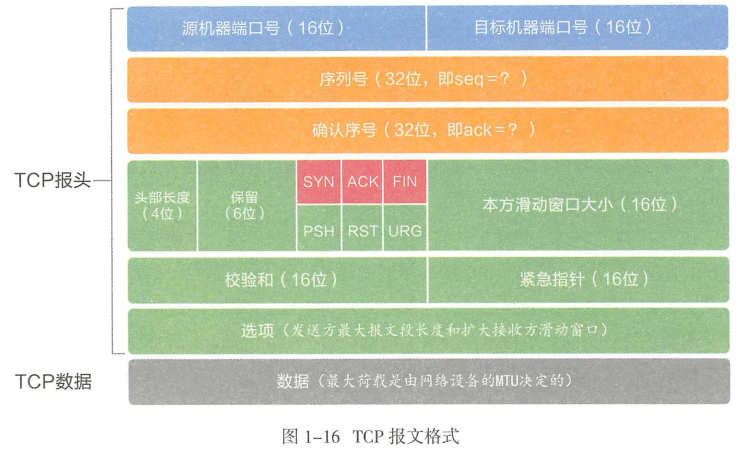
-
头部长度:通常为20字节,有选项时更长
- 这里头部长度的1指代的是32位,即4个字节长度
- 因此4位的首部长度能够表示60字节
-
报文序号
- 标识报文中的第一个数据字节的序号
- 到达2^32-1后,重新回到0开始计数
- 初始连接请求报文中,SYN标志位也占1,因此第一字节序号为ISN+1
-
确认序号
- 接收方期望接收的下一个数据字节的序号
- ACK为1时有效
-
校验和
- 由首部和数据一起运算得到,用来校验报文数据是否丢失
-
紧急指针
- 紧急数据字节号(urgSeq)=TCP报文序号(seq)+紧急指针(urgpoint)−1
- 正偏移量
-
选项
- 常见的是MSS(最大报文大小),指明本端能够接收的最大长度的报文段
-
窗口大小
- 16位的窗口大小最多能放65536字节
- 如果想要使用更大的窗口,可以在选项中添加窗口的缩放比例因子来进行扩大,比例为0-14
2. IP报文格式及首部含义?
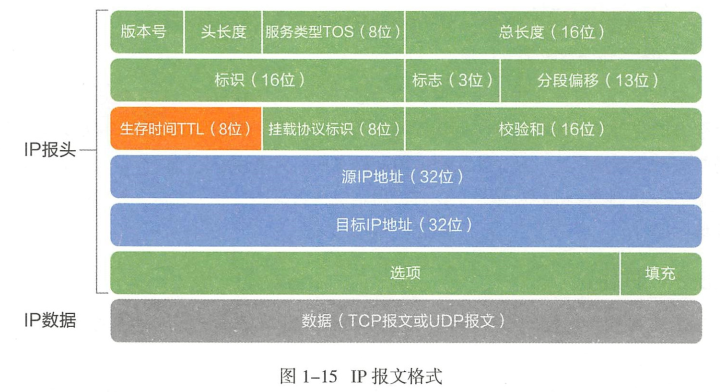
- 头部长度:通常20字节,有选项时更长,总共不超过60字节
- 校验和
- 仅对IP首部计算校验和
- TCP、UDP、ICMP等协议均在各自的首部中包含覆盖首部和数据的校验和
- 挂载协议标识
- 用来表示上层的传输层协议使用的是什么协议
- 分段偏移
- 当原始报文过大,以以太网帧为例,当大于1500字节的时候,会对原始报文进行分割,此时该字段就用来表示该分段在原始报文的位置
3. UDP报文格式及首部含义?
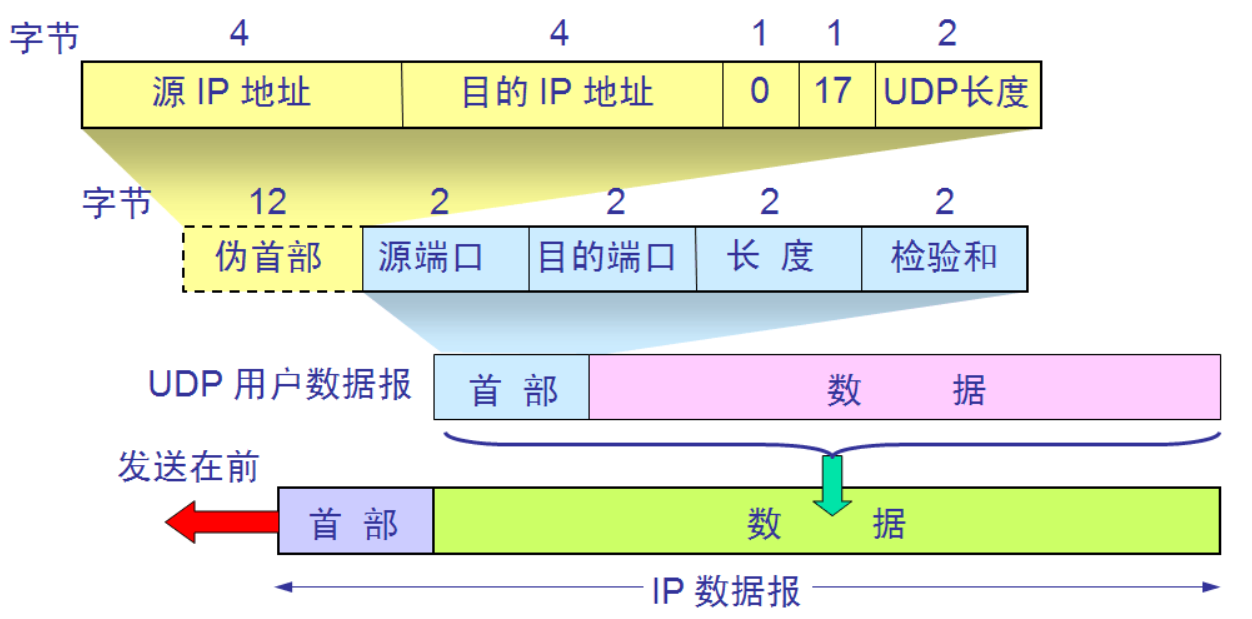
- 主要组成:源端口号、目标端口号、报文长度、检验和,一共8字节
- 报文长度
- 指首部和数据的总字节长度
3.1 UDP伪首部作用?
- 伪首部的出现:发送方或接收方根据IP报文首部获得8字节的源地址+目的地址、2字节的0字段+UDP协议字段、2字节的数据长度,得到12字节伪首部,临时添加在首部前面
- 伪首部的消失:发送方将计算完毕的校验和填入首部的校验和字段后,去除伪首部发送UDP报文
- 作用:仅仅是为了计算校验和
4. TCP三次握手的流程?
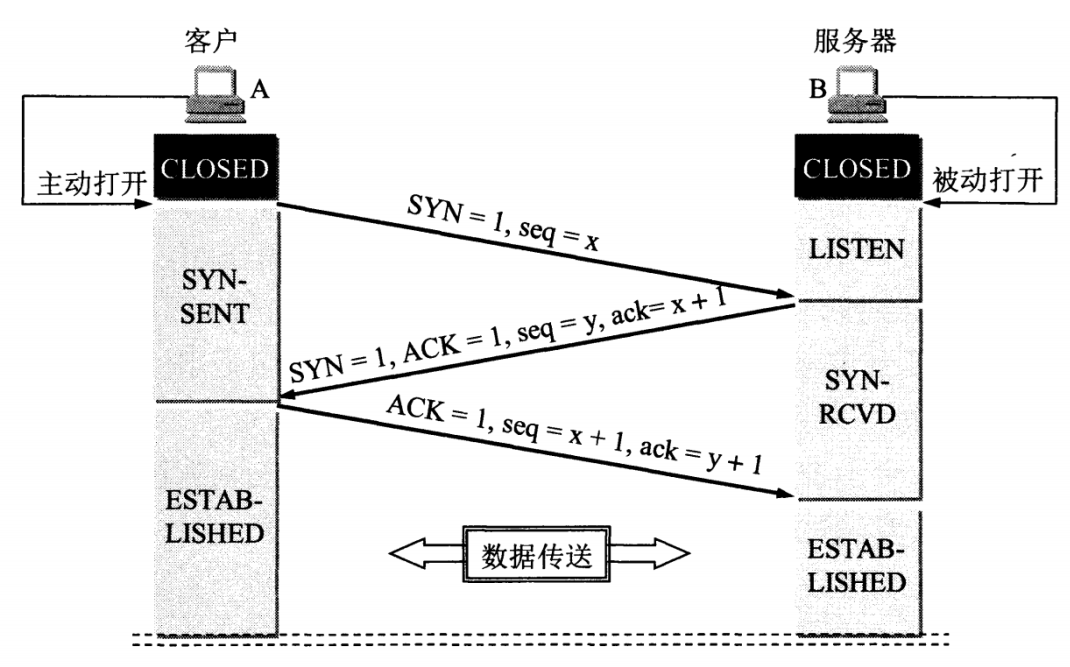
- 假设 A 为客户端,B 为服务器端。
- 首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
- A 向 B 发送连接请求报文,SYN=1,ACK=0,选择一个初始的序号 x。
- 在SYN建立连接的阶段会携带MSS选项字段来决定MSS报文的大小
- 默认是536字节,如果双方协商不成功
- B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
- 与此同时,B会将该连接放进半连接队列(SYN队列)
- A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
- 此时A已经可以携带数据
- B 收到 A 的确认后,连接建立。
- 此时,B的内核会将该连接从半连接队列中移除,然后创建新的完全连接,并添加到accept队列(全连接队列),等待应用程序调用accept函数取出来
5. 为什么需要三次握手?
- 防止历史连接请求初始化了连接
- 第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
- 客户端发送的连接请求如果在网络中滞留,那么就会隔很长一段时间才能收到服务器端发回的连接确认。客户端等待一个超时重传时间之后,就会重新请求连接。但是这个滞留的连接请求最后还是会到达服务器,如果不进行三次握手,那么服务器就会打开两个连接。如果有第三次握手,客户端会根据上下文(如确认号)判断服务端发来的确认连接是否是历史连接(此时客户端不处于SYN-SENT状态),如果是,客户端则发送RST报文,终止历史连接,避免错误打开连接。
- 同步双方初始序列号
- 在TCP协议中,报文的序列号和确认号是确保消息可靠送达的重要机制
- 因此,需要正确同步双方的初始序列号。而同步一方的初始序列号,需要一次请求报文和响应报文。因此,确认双方的初始序列号,需要进行三次握手
- 当客户端发送携带「初始序列号」的
SYN报文的时候,需要服务端回一个ACK应答报文,表示客户端的 SYN 报文已被服务端成功接收,那当服务端发送「初始序列号」给客户端的时候,依然也要得到客户端的应答回应,这样一来一回,才能确保双方的初始序列号能被可靠的同步
- 避免资源浪费
- 与第一点相似,主要是为了避免重开连接导致浪费系统资源
6. 三次握手过程中未收到对方回复会怎么样?
- 服务端未收到第一次握手信息
- 服务端本身不会干什么,因为它还没有收到连接请求
- 客户端会不断地重试发送
- 客户端没有收到第二次握手信息
- 服务端的响应由于网络原因一直没有抵达客户端,此时服务端会不断重试
- 服务端没有收到第三次握手信息
- 服务端没有收到客户端的确认信息,这时候服务端会重传报文,如果重传次数达到上限时仍然没有收到确认报文,那么accept会返回-1,此时服务端这边的连接建立失败
- 此时客户端已经进入连接状态,可以发送消息了,但是服务端的连接失败了(accept返回-1),此时客户端再向服务端发送数据,服务端在收到后会发送RST报文给客户端
7. 如何绕过三次握手?
- 在普通的三次握手的流程中,头两次握手的期间是不能携带数据的
- 也就是必须等到一个RTT时间后才能发送数据
- 使用TCP Fast Open,可以减少TCP建立连接发送数据的延迟
在客户端首次建立连接时的过程:
- 客户端发送 SYN 报文,该报文包含 Fast Open 选项,且该选项的 Cookie 为空,这表明客户端请求 Fast Open Cookie;
- 支持 TCP Fast Open 的服务器生成 Cookie,并将其置于 SYN-ACK 数据包中的 Fast Open 选项以发回客户端;
- 客户端收到 SYN-ACK 后,本地缓存 Fast Open 选项中的 Cookie。
所以,第一次发起 HTTP GET 请求的时候,还是需要正常的三次握手流程。
之后,如果客户端再次向服务器建立连接时的过程:
- 客户端发送 SYN 报文,该报文包含「数据」(对于非 TFO 的普通 TCP 握手过程,SYN 报文中不包含「数据」)以及此前记录的 Cookie;
- 支持 TCP Fast Open 的服务器会对收到 Cookie 进行校验:如果 Cookie 有效,服务器将在 SYN-ACK 报文中对 SYN 和「数据」进行确认,服务器随后将「数据」递送至相应的应用程序;如果 Cookie 无效,服务器将丢弃 SYN 报文中包含的「数据」,且其随后发出的 SYN-ACK 报文将只确认 SYN 的对应序列号;
- 如果服务器接受了 SYN 报文中的「数据」,服务器可在握手完成之前发送「数据」,这就减少了握手带来的 1 个 RTT 的时间消耗;
- 客户端将发送 ACK 确认服务器发回的 SYN 以及「数据」,但如果客户端在初始的 SYN 报文中发送的「数据」没有被确认,则客户端将重新发送「数据」;
- 此后的 TCP 连接的数据传输过程和非 TFO 的正常情况一致。
所以,之后发起 HTTP GET 请求的时候,可以绕过三次握手,这就减少了握手带来的 1 个 RTT 的时间消耗。
8. 初始序列号 ISN 是如何随机产生的?
起始 ISN 是基于时钟的,每 4 毫秒 + 1,转一圈要 4.55 个小时。
RFC1948 中提出了一个较好的初始化序列号 ISN 随机生成算法。
ISN = M + F (localhost, localport, remotehost, remoteport)
M是一个计时器,这个计时器每隔 4 毫秒加 1。F是一个 Hash 算法,根据源 IP、目的 IP、源端口、目的端口生成一个随机数值。要保证 Hash 算法不能被外部轻易推算得出,用 MD5 算法是一个比较好的选择
9. 既然 IP 层会分片,为什么 TCP 层还需要 MSS 呢?
- MTU 和 MSS
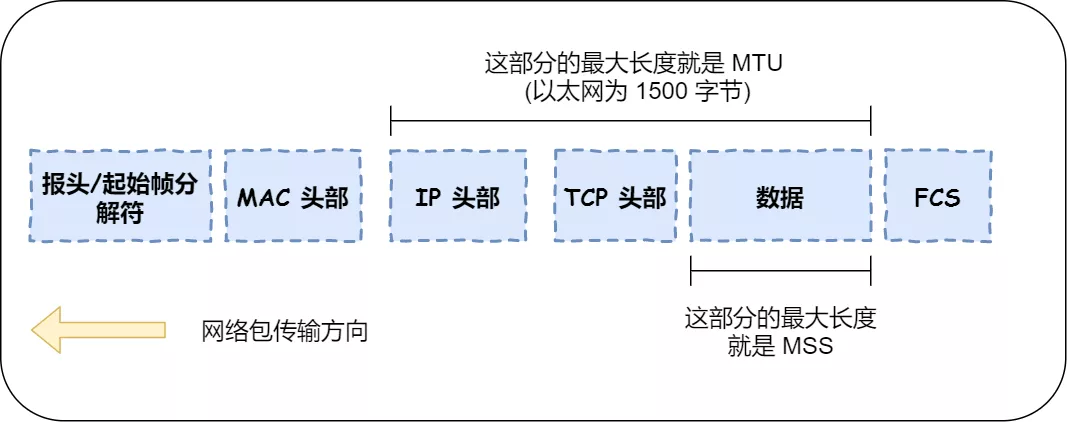
-
MTU:一个网络包的最大长度,以太网中一般为1500字节; -
MSS:除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度; -
假设TCP的报文均由IP层进行分片;
-
当TCP的报文长度大于MTU时,报文会进行分片,然后发送给目标主机,再由目标主机进行组装,上传到传输层
-
然而,如果有一个IP分片丢失了,那么整个IP报文需要重传
-
因为IP层本身无超时重传机制,超时重传机制是靠传输层的TCP来保证的;
-
当接收方发现TCP报文中的一片丢失后,不会响应对应报文的ACK给对方,发送方在超时后就会重发TCP报文
-
到达IP层后则需再次分片发送,效率低下
-
针对上述情况,为了达到最佳的传输性能,TCP 协议在建立连接的时候通常要协商双方的 MSS 值,当 TCP 层发现数据超过 MSS 时,则就先会进行分片,当然由它形成的 IP 包的长度也就不会大于 MTU ,自然也就不用 IP 分片了

- 经过 TCP 层分片后,如果一个 TCP 分片丢失后,进行重发时也是以 MSS 为单位,而不用重传所有的分片,大大增加了重传的效率。
10. SYN攻击是什么?
- TCP 连接建立是需要三次握手,假设攻击者短时间伪造不同 IP 地址的
SYN报文,服务端每接收到一个SYN报文,就进入SYN_RCVD状态,但服务端发送出去的ACK + SYN报文,无法得到未知 IP 主机的ACK应答,久而久之就会占满服务端的 SYN 接收队列(未连接队列),使得服务器不能为正常用户服务 - 一旦服务端接收到SYN后,会为该连接分配一个TCB(Transmission Control Block),通常一个TCB至少需要280个字节,在某些操作系统中TCB甚至需要1300个字节
- 半连接队列的个数一般是有限的,在SYN攻击下,服务器会打开大量的半连接,分配TCB,从而耗尽服务器的资源,使得正常的连接请求无法得到响应
10.1 SYN攻击的分类有哪些?
- Direct Attack 直接攻击
- 攻击方使用固定的源地址发起攻击
- 这种比较容易预防,只要将特定的IP列入黑名单即可
- Spoofing Attack 攻击方使用变化的源地址发起攻击
- Distributed Direct Attack 这种攻击主要是使用僵尸网络进行固定源地址的攻击
10.2 SYN攻击的解决方法有什么?
攻击者是不会回复ACK的,而正常客户端是会回复的。
-
主要针对后两种攻击
-
修改Linux 内核参数,控制队列大小和当队列满时应做什么处理
- 当网卡接收数据包的速度大于内核处理的速度时,会有一个队列保存这些数据包。控制该队列的最大值如下参数:
net.core.netdev_max_backlog - SYN_RCVD 状态连接的最大个数:
net.ipv4.tcp_max_syn_backlog - 超出处理能时,对新的 SYN 直接回 RST,丢弃连接:
net.ipv4.tcp_abort_on_overflow
- 当网卡接收数据包的速度大于内核处理的速度时,会有一个队列保存这些数据包。控制该队列的最大值如下参数:
-
开启 tcp_syncookies 功能
-
sysctl -w net.ipv4.tcp_syncookies=11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 本质上属于延缓TCB分配方法
- 收到SYN攻击,会导致SYN队列被占满,对于后续来到的SYN请求,不再放在队列中,而是直接回应一个带SYN cookie的SYN-ACK包给客户端
- 服务器根据当前状态计算出一个值,放在己方发出的 SYN+ACK 报文中发出,当客户端返回 ACK 报文时,取出该值验证,如果合法,就认为连接建立成功,然后放到accept队列
- 后续应用程序调用accept()从accept队列中取出连接
- 增大半连接队列
- **增大半连接队列,我们得知不能只单纯增大 tcp_max_syn_backlog 的值,还需一同增大 somaxconn 和 backlog,也就是增大全连接队列**
- ```bash
sysctl -w net.ipv4.tcp_max_syn_backlog=2048
-
-
减少 SYN+ACK 重传次数
-
减少 SYN+ACK 的重传次数,以加快处于 SYN_REVC 状态的 TCP 连接断开
-
sysctl -w net.ipv4.tcp_synack_retries=3 sysctl -w net.ipv4.tcp_syn_retries=3- addrlen:地址长度。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
- 全连接队列和半连接队列一起构成未决连接队列,这个队列的大小为backlog,是listen的参数
#### 10.3 SYN cookie是什么?
- 服务器端根据本次连接的信息、时间生成一个SYN cookie做为报文初始序号
- 当客户端收到后,会向服务端发送响应报文
- 服务端根据响应报文的确认号-1就可以得到之前的SYN cookie
- 对SYN cookie按照规则进行解析就可以判断响应是否超时,以及连接信息是否有伪装等,避免浪费服务器的资源
### 11. TCP控制位有哪些?分别有什么用?
1. SYN(synchronous建立联机)
- 用于建立连接,该报文的序列号用于初始序号的确定
2. ACK(acknowledgement 确认)
- 表示当前报文的应答字段有效
- 除了最初的SYN报文外,其它报文必须将该位设置为1
3. PSH(push传送)
- 接收方应该尽快将报文提交给应用层
- 为0则可以先进行缓存
4. FIN(finish结束)
- 表示今后不会再有数据发送,希望断开连接
- 通信结束后,双方交换fin报文结束通信
5. RST(reset重置)
- TCP连接出现异常,必须强制断开连接
- 常见情况:连接请求到达时,目标端口没有进程在监听
6. URG(urgent紧急)
- 表示包中有需要紧急处理的数据,结合紧急指针一起使用
7. Sequence number(顺序号码)
- 对字节流进行标号,表示第一个字节的编号
8. Acknowledge number(确认号码)
- 期望收到的下一个报文的序号
### 12. TCP首部格式以及字段含义?
<img src="https://cdn.jsdelivr.net/gh/zgzhengSEU/imagebed/Image/202203051711326.webp" alt="img" style="zoom:33%;" />
- **序号:**
- 用于对字节流进行编号。例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100字节,那么下一个报文段的序号应为 401。
- **确认号 :**
- 期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
- **数据偏移 :**
- 指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
- **确认 ACK :**
- 当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把ACK 置 1
- **同步 SYN :**
- 在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
- **终止 FIN :**
- 用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
- **窗口 :**
- 窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
### 13. 四次挥手的流程?
<img src="https://cdn.jsdelivr.net/gh/zgzhengSEU/imagebed/Image/202203051711391.png" alt="1584351152420" style="zoom: 33%;" />
以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。
- A 发送连接释放报文,FIN=1。
- B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。
- 当 B 不再需要连接时,发送连接释放报文,FIN=1。
- A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)(Linux 系统里 `2MSL` 默认是 `60` 秒)后释放连接。
- B 收到 A 的确认后释放连接。
### 14. 为什么需要4次挥手?
客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态。**这个状态是为了让服务器端发送还未传送完毕的数据**,传送完毕之后,服务器会发送 FIN 连接释放报文。
**TIME_WAIT**:客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
- **确保最后一个确认报文能够到达**。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
- **至少允许报文丢失一次**
- 等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
### 15. 四次挥手可以变为三次吗?
- 一种情况是延迟确认,将第二步的ack与第三步的fin包一起发送给对端
- 另外一种是服务端已经没有什么数据要发送了,就可以将fin和ack合并一个包发送给对端
### 16. FIN-WAIT2等待时间是多少?
- 主动关闭的一端调用完close以后(即发FIN给被动关闭的一端, 并且收到其对FIN的确认ACK)则进入FIN_WAIT_2状态。**如果这个时候因为网络突然断掉、被动关闭的一段宕机等原因,导致主动关闭的一端不能收到被动关闭的一端发来的FIN(防止对端不发送关闭连接的FIN包给本端)**,这个时候就需要FIN_WAIT_2定时器, 如果在该定时器超时的时候,还是没收到被动关闭一端发来的FIN,那么直接释放这个链接,进入CLOSE状态
### 17. 针对 TCP 应该如何 Socket 编程?
<img src="https://cdn.jsdelivr.net/gh/zgzhengSEU/imagebed/Image/202203051711304.webp" alt="img" style="zoom:50%;" />
- 流程:
- 服务端和客户端初始化 `socket`,得到文件描述符;
- 服务端调用 `bind`,将监听socket绑定在 IP 地址和端口;
- 服务端调用 `listen`,进行监听;
- 服务端调用 `accept`,等待客户端连接;
- 客户端调用 `connect`,向服务器端的地址和端口发起连接请求;
- 服务端 `accept` 返回用于传输的 `socket` 的文件描述符;
- 客户端调用 `write` 写入数据;服务端调用 `read` 读取数据;
- 客户端断开连接时,会调用 `close`,那么服务端 `read` 读取数据的时候,就会读取到了 `EOF`,待处理完数据后,服务端调用 `close`,表示连接关闭。
- **注意点:**
- 服务端调用 `accept` 时,连接成功了会返回一个已完成连接的 socket,后续用来传输数据
- 所以,监听的 socket 和真正用来传送数据的 socket,是「两个」 socket,一个叫作**监听 socket**,一个叫作**已完成连接 socket**
- **服务器:**
- 创建socket -> int socket(int domain, int type, int protocol);
- domain:协议域,决定了socket的地址类型,IPv4为AF_INET。
- type:指定socket类型,SOCK_STREAM为TCP连接。
- protocol:指定协议。IPPROTO_TCP表示TCP协议,为0时自动选择type默认协议。
- 绑定socket和端口号 -> int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- sockfd:socket返回的套接字描述符,类似于文件描述符fd。
- addr:有个sockaddr类型数据的指针,指向的是被绑定结构变量。
```C++
// IPv4的sockaddr地址结构
struct sockaddr_in {
sa_family_t sin_family; // 协议类型,AF_INET
in_port_t sin_port; // 端口号
struct in_addr sin_addr; // IP地址
};
struct in_addr {
uint32_t s_addr;
} -
监听端口号 -> int listen(int sockfd, int backlog);
-
sockfd:要监听的sock描述字。
-
backlog:socket可以排队的最大连接数。
-
-
接收用户请求 -> int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
-
sockfd:服务器socket描述字。
-
addr:指向地址结构指针。
-
addrlen:协议地址长度。
-
注:一旦accept某个客户机请求成功将返回一个全新的描述符用于标识具体客户的TCP连接。
-
-
从socket中读取字符 -> ssize_t read(int fd, void *buf, size_t count);
-
fd:连接描述字。
-
buf:缓冲区buf。
-
count:缓冲区长度。
-
注:大于0表示读取的字节数,返回0表示文件读取结束,小于0表示发生错误。
-
-
关闭socket -> int close(int fd);
-
fd:accept返回的连接描述字,每个连接有一个,生命周期为连接周期。
-
注:sockfd是监听描述字,一个服务器只有一个,用于监听是否有连接;fd是连接描述字,用于每个连接的操作。
-
-
-
客户机:
-
创建socket -> int socket(int domain, int type, int protocol);
-
连接指定计算机 -> int connect(int sockfd, struct sockaddr* addr, socklen_t addrlen);
-
sockfd客户端的sock描述字。
-
addr:服务器的地址。
-
addrlen:socket地址长度。
-
-
向socket写入信息 -> ssize_t write(int fd, const void *buf, size_t count);
-
fd、buf、count:同read中意义。
-
大于0表示写了部分或全部数据,小于0表示出错。
-
-
关闭oscket -> int close(int fd);
- fd:同服务器端fd。
-
18. HTTP协议和HTTPS协议的默认端口号?
-
http:80
-
https:443
19. http协议的流程?
- 首先进行域名解析。
- 浏览器发起HTTP请求。
- 接下来到了传输层,选择传输协议。TCP或者UDP,TCP是可靠的传输控制协议,对HTTP请求进行封装,加入了端口号等信息。
- 然后到了网络层,通过IP协议将IP地址封装为IP数据报;然后此时会用到ARP协议,主机发送信息时将包含目标IP地址的ARP请求广播到网络上的所有主机,并接收返回消息,以此确定目标的物理地址,找到目的MAC地址;
- 接下来到了数据链路层,把网络层交下来的IP数据报添加首部和尾部,封装为MAC帧,现在根据目的mac开始建立TCP连接,三次握手,接收端在收到物理层上交的比特流后,根据首尾的标记,识别帧的开始和结束,将中间的数据部分上交给网络层,然后层层向上传递到应用层;
- 服务器响应请求并返回客户端要的资源,传回给客户端;
- 断开TCP连接,浏览器对页面进行渲染呈现给客户端。
20. cookies和session的含义与区别?
- Cookie :
- Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
- 用途:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
- Session :
- Session 是存储在 web 服务器端的一块信息。 session 对象存储特定用户会话所需的属性及配置信息。当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。
- 不同:
- **存取方式的不同:**Cookie 只能存储 ASCII 码字符串,而 Session 则可以存储任何类型的数据,因此在考虑数据复杂性时首选Session;
- **隐私策略的不同:**Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie 中,可以将 Cookie 值进行加密,然后在服务器进行解密。而Session存储在服务器上,不存在敏感信息泄露的风险。
- **服务器压力的不同:**对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。 而Cookie保管在客户端,不占用服务器资源。假如并发阅读的用户十分多,Cookie是很好的选择。关于Google、Baidu、Sina来说,Cookie或许是唯一的选择。
- **浏览器支持的不同:**无论客户端做怎样的设置, session 都能够正常工作。当客户端禁用 cookie 时将无法使用 cookie。 假如客户端浏览器不支持Cookie,需要运用Session以及URL地址重写。需要注意的是一切的用到Session程序的URL都要进行URL地址重写,否则Session会话跟踪还会失效。关于WAP应用来说,Session+URL地址重写或许是它唯一的选择
- **跨域支持上的不同:**Cookie支持跨域名访问,例如将domain属性设置为“.biaodianfu.com”,则以“.biaodianfu.com”为后缀的一切域名均能够访问该Cookie。跨域名Cookie如今被普遍用在网络中,例如Google、Baidu、Sina等。而Session则不会支持跨域名访问。Session仅在他所在的域名内有效。
- 参考:
21. Http协议如何保证安全性?
- 重要的数据,要加密:
- 比如用户名密码,我们需要加密,这样即使被抓包监听,他们也不知道原始数据是什么。
- 非重要数据,要签名:
- 签名的目的是为了防止篡改,比如http://www.baidu.com/getnews?id=1,获取id为1的新闻,如果不签名那么通过id=2,就可以获取2的内容等等。怎样签名呢?通常使用sign,比如原链接请求的时候加一个sign参数,sign=md5(id=1),服务器接受到请求,验证sign是否等于md5(id=1),如果等于说明正常请求。这会有个弊端,假如规则被发现,那么就会被伪造,所以适当复杂一些,还是能够提高安全性的。
22. 阻塞式io和非阻塞式io有什么区别?
- 读:
- 在阻塞条件下,如果没有发现数据在网络缓冲中会一直等待,当发现有数据的时候会把数据读到用户指定的缓冲区。但是如果这个时候读到的数据量比较少,比参数中指定的长度要小,read并不会一直等待下去,而是立刻返回。read的原则是数据在不超过指定的长度的时候有多少读多少,没有数据就会一直等待。所以一般情况下我们读取数据都需要采用循环读的方式读取数据,一次read完毕不能保证读到我们需要长度的数据,read完一次需要判断读到的数据长度再决定是否还需要再次读取。
- **在非阻塞的情况下,**read的行为是如果发现没有数据就直接返回,如果发现有数据那么也是采用有多少读多少的进行处理.对于读而言,阻塞和非阻塞的区别在于没有数据到达的时候是否立刻返回。
- 写:
- **在阻塞的情况,**是会一直等待直到write完全部的数据再返回。
- 非阻塞写的情况,是采用可以写多少就写多少的策略。与读不一样的地方在于,有多少读多少是由网络发送端是否有数据传输到本地内核缓存为准。但是对于可以写多少是由本地的网络堵塞情况为标准的,在网络阻塞严重的时候,网络层没有足够的内存来进行写操作,这时候就会出现写不成功的情况,阻塞情况下会尽可能(有可能被中断)等待到数据全部发送完毕,对于非阻塞的情况就是一次写多少算多少,没有中断的情况下也还是会出现write到一部分的情况。
23. 网络协议有哪7层?
- 应用层
- 用户接口、应用程序;
- Application典型设备:网关;
- 典型协议、标准和应用:TELNET、FTP、HTTP
- 表示层
- 数据表示、压缩和加密presentation
- 典型设备:网关
- 典型协议、标准和应用:ASCLL、PICT、TIFF、JPEG|MPEG
- 表示层相当于一个东西的表示,表示的一些协议,比如图片、声音和视频MPEG。
- 会话层
- 会话的建立和结束;
- 典型设备:网关;
- 典型协议、标准和应用:RPC、SQL、NFS、X WINDOWS、ASP
- 传输层
- 主要功能:端到端控制Transport;
- 典型设备:网关;
- 典型协议、标准和应用:TCP、UDP、SPX
- 网络层
- 主要功能:路由、寻址Network;
- 典型设备:路由器;
- 典型协议、标准和应用:IP、IPX、APPLETALK、ICMP;
- 数据链路层
- 主要功能:保证无差错的疏忽链路的data link;
- 典型设备:交换机、网桥、网卡;
- 典型协议、标准和应用:802.2、802.3ATM、HDLC、FRAME RELAY;
- 物理层
- 主要功能:传输比特流Physical;
- 典型设备:集线器、中继器
- 典型协议、标准和应用:V.35、EIA/TIA-232.
24. TCP和UDP的区别?
- TCP:
- 可靠,稳定 TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。
- 慢,效率低,占用系统资源高,易被攻击。TCP在传递数据之前,要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的CPU、内存等硬件资源。 而且,因为TCP有确认机制、三次握手机制,这些也导致TCP容易被人利用,实现DOS、DDOS、CC等攻击。
- UDP:
- 快,比TCP稍安全 UDP没有TCP的握手、确认、窗口、重传、拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些。但UDP也是无法避免攻击的,比如:UDP Flood攻击……
- 不可靠,不稳定 因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。
- 使用场景:
- 整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。 在日常生活中,常见使用TCP协议的应用如下: 浏览器,用的HTTP FlashFXP,用的FTP Outlook,用的POP、SMTP Putty,用的Telnet、SSH QQ文件传输 …………
- 当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。 比如,日常生活中,常见使用UDP协议的应用如下: QQ语音 QQ视频 TFTP ……
- 区别小结:
- TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
- TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
- TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
- UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
- 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
- TCP首部开销20字节;UDP的首部开销小,只有8个字节(UDP的速度快,开销少)
- TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
- 参考:TCP和UDP的最完整的区别
25. HTTP的常用方法
- GET:
- 获取资源
- 当前网络请求中,绝大部分使用的是 GET 方法。
- HEAD :
- 获取报文首部
- 和 GET 方法类似,但是不返回报文实体主体部分。
- 主要用于确认 URL 的有效性以及资源更新的日期时间等。
- POST :
- 传输实体主体
- POST 主要用来传输数据,而 GET 主要用来获取资源。
- PUT :
- 上传文件
- 由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
- PATCH :
- 对资源进行部分修改
- PUT 也可以用于修改资源,但是只能完全替代原始资源,PATCH 允许部分修改。
- DELETE :
- 删除文件
- 与 PUT 功能相反,并且同样不带验证机制。
- OPTIONS :
- 查询支持的方法
- 查询指定的 URL 能够支持的方法。
- 会返回 Allow: GET, POST, HEAD, OPTIONS 这样的内容。
- CONNECT :
- 要求在与代理服务器通信时建立隧道
- 使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
- TRACE :
- 追踪路径
- 服务器会将通信路径返回给客户端。
- 发送请求时,在 Max-Forwards 首部字段中填入数值,每经过一个服务器就会减 1,当数值为 0 时就停止传输。
- 通常不会使用 TRACE,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪)。
26. Http get 和 post 的区别?
- 根据http规范,get用于信息获取,应该是安全的和幂等的
- 安全意味着该操作用于获取信息而非修改信息。换句话说,GET 请求一般不应产生副作用。
- 幂等的意味着对同一URL的多个请求应该返回同样的结果。
- 根据http规范,POST表示可能修改变服务器上的资源的请求,即post用于提交数据。
- get提交参数追加在url后面,post参数可以通过http body提交。
- get的url会有长度上的限制,则post的数据则可以非常大,post的数据量受限于处理程序的处理能力。
- get提交信息明文显示在url上,不够安全,post提交的信息不会在url上显示
- get提交可以被浏览器缓存,post不会被浏览器缓存。
- 登录页面有可能被浏览器缓存
- 其他人可以看到浏览器的历史记录
- get参数只能使用ascii码,post参数可以使用标准字符集
- get 方法产生一个 TCP 数据包,post 方法产生两个(并不是所有的浏览器中都产生两个)。
- 对于GET方式的请求,浏览器会把 http header 和 data 一并发送出去,服务端响应 200,请求成功。
- 对于POST方式的请求,浏览器会先发送 http header 给服务端,告诉服务端等一下会有数据过来,服务端响应 100 continue,告诉浏览器我已经准备接收数据,浏览器再 post 发送一个 data 给服务端,服务端响应 200,请求成功。
27. URL和URI的区别?
- URI包括URL和URN两个类别,URL是URI的子集,所以URL一定是URI,而URI不一定是URL
- URI:
- Universal Resource Identifier 统一资源标志符
- 用来标识抽象或物理资源的一个紧凑字符串。
- URL :
- Universal Resource Locator 统一资源定位符.
- 一种定位资源的主要访问机制的字符串,一个标准的URL必须包括:protocol、host、port、path、parameter、anchor。
- URN :
- Universal Resource Name 统一资源名称.
- 通过特定命名空间中的唯一名称或ID来标识资源。
28. 从浏览器中输入url之后发生了什么?
-
DNS查询
-
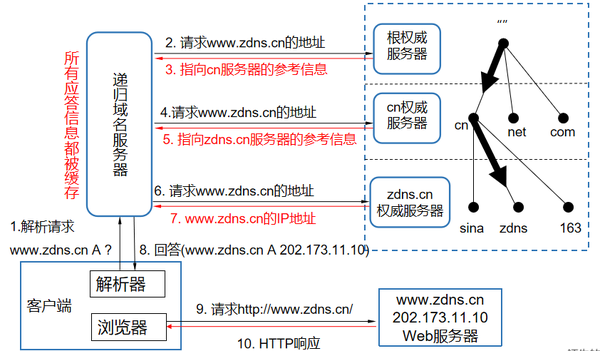
- 先在本地域名服务器中根据域名查询IP
- 向根域名服务器发送请求,查找IP
- 向顶级域名服务器发送请求,查找IP
-
-
TCP连接
-
发送HTTP请求
-
Server处理HTTP请求并返回HTTP报文
-
浏览器解析并渲染页面
-
连接断开
-
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户。
29. 域名解析每次都去访问根域名服务器的话,根域名服务器压力不会很大吗?DNS优化方法?
- 浏览器缓存
- 系统缓存
- 路由器缓存
- IPS服务器缓存
- 根域名服务器缓存
- 顶级域名服务器缓存
- 主域名服务器缓存
30. OSI七层协议模型、TCP/IP四层模型和五层协议体系结构之间的关系?
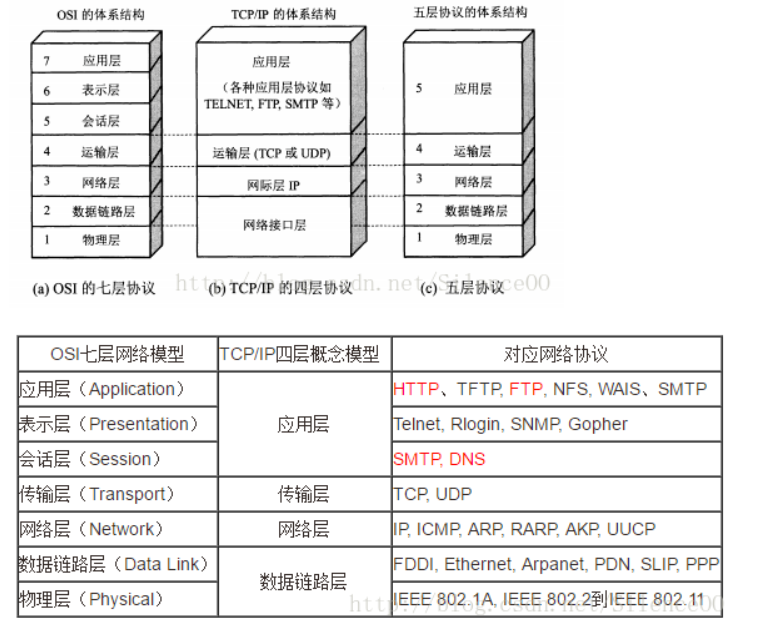
31. osi为什么有了七层还有五层的概念?
- 七层协议的理论虽然完整,但是不太实用而且很复杂
- 四层结构是实现模型,而5层结构则是结合两种模型得出的,目的是为了更好描述网络接口层
32. TCP可靠性机制有哪些?
32.1 TCP如何保证消息顺序?
- TCP协议会给每个数据包分配一个序列号
- 发送方在发送消息后,会等待接收方对该报文进行确认,如果一段时间内没有收到确认,那么会触发超时重传,发送方会重传该报文
- 接收方接收到数据后,会先进行缓存,如果数据的顺序是正确的,那么就上传到应用层使用,否则暂时保存在缓冲区
32.2 TCP的重传机制是怎么实现的?
32.2.1 超时重传机制?
-
在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的
ACK确认应答报文,就会重发该数据 -
数据包丢失或者确认应答丢失就会触发
-
数据包在网络中的往返时间(RTT)
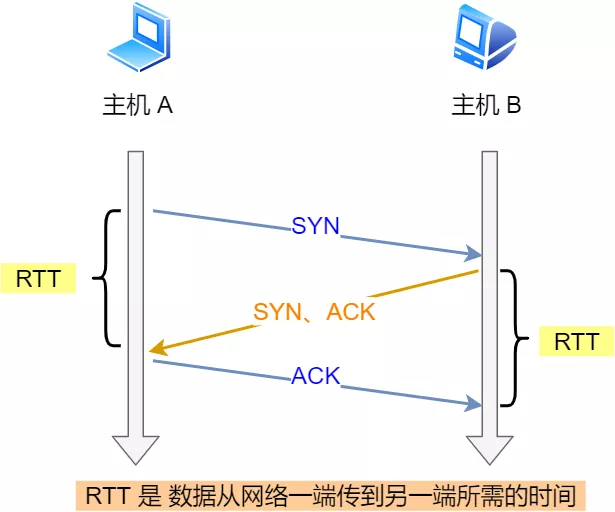
- 超时重传时间(RTO)
- 很显然,RTO应该设置为略大于RTT,以便获得最高的性能
- 但是由于网络情况不断变化,RTT时间是一个动态变化的值
- Linux系统下是采用某种公式来计算对应的RTO时间(公式的参数是通过大量的实验得到的)
- 如果超时重发的数据,再次超时的时候,又需要重传的时候,TCP 的策略是超时间隔加倍
- 也就是每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
32.2.2 快速重传机制?
- 发送方收到了三次同样的 ACK 确认报文,于是就会触发快速重发机制
- 但是在重传的时候无法确认是重传之前一个,还是所有
32.2.3 SACK(选择性确认) 、D-SACK 选项的作用?
SACK:
-
在 TCP 头部「选项」字段里加一个
SACK的东西 -
将缓存的地图发送给发送方
- 告诉发送方我收到了哪些数据
-
只重传丢失的数据
-
Linux 通过
net.ipv4.tcp_sack参数打开这个功能(Linux 2.4 后默认打开) -
注意:启动sack后,接受方接收到带sack的报文也认为收到重复ack
- 开启该功能需要双方支持并协商成功
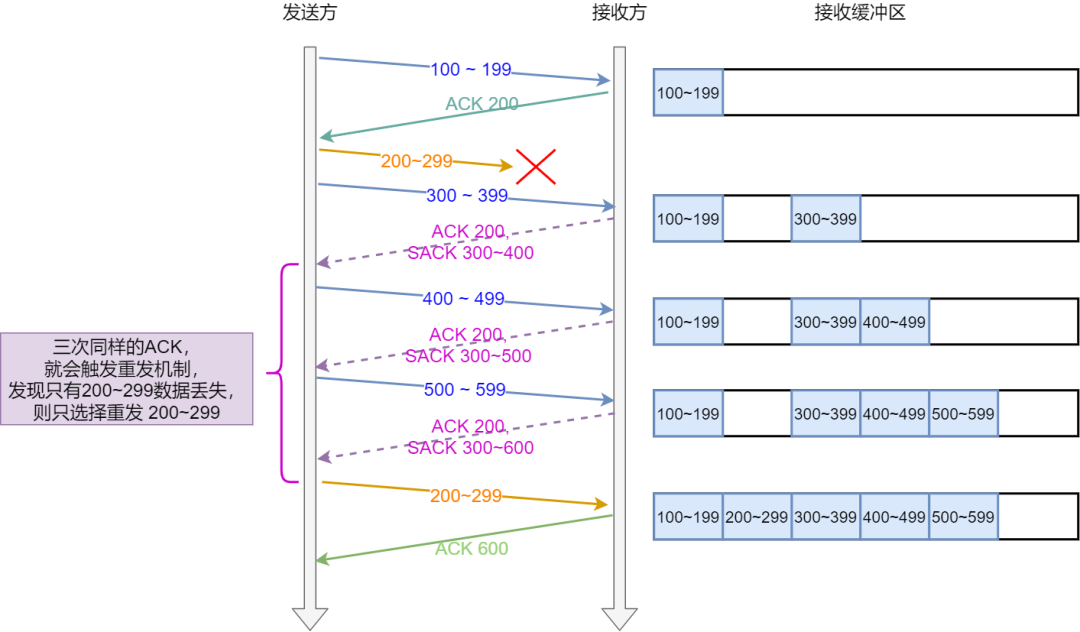
D-SACK:
-
使用了 SACK 来告诉「发送方」有哪些数据被重复接收了
-
使用D-SACK的好处
- 可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
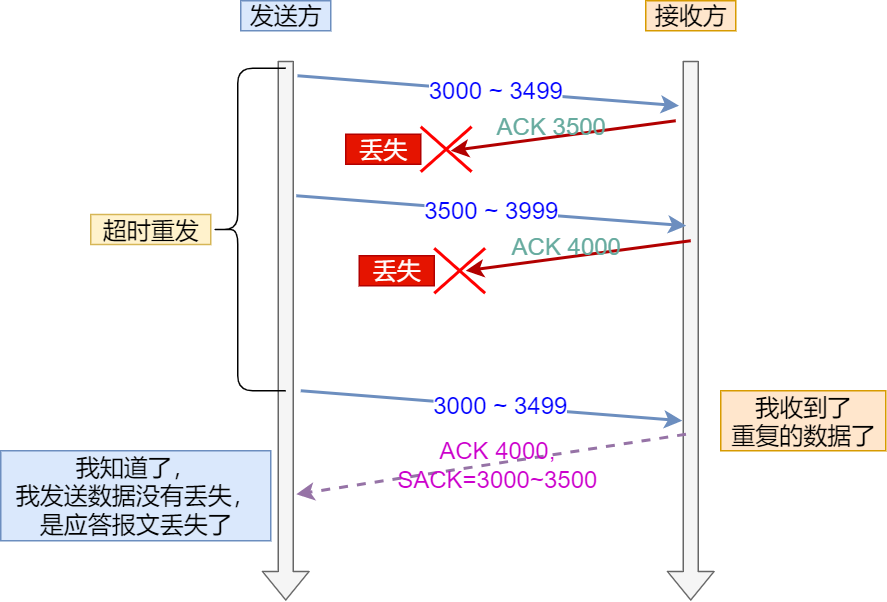
- 可以知道是不是「发送方」的数据包被网络延迟了;

- 可以知道网络中是不是把「发送方」的数据包给复制了;
- 可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
-
在 Linux 下可以通过
net.ipv4.tcp_dsack参数开启/关闭这个功能(Linux 2.4 后默认打开)。
32.3 滑动窗口的作用是什么?
- 没有滑动窗口的话
- 仅按数据包进行确认应答,数据包的往返时间越长,通信的效率就越低
- 使用滑窗
- 窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值
- 窗口内的数据可以不用等待接收方的应答,先行发送出去
- 如果收到了应答,就可以将数据从窗口内清除
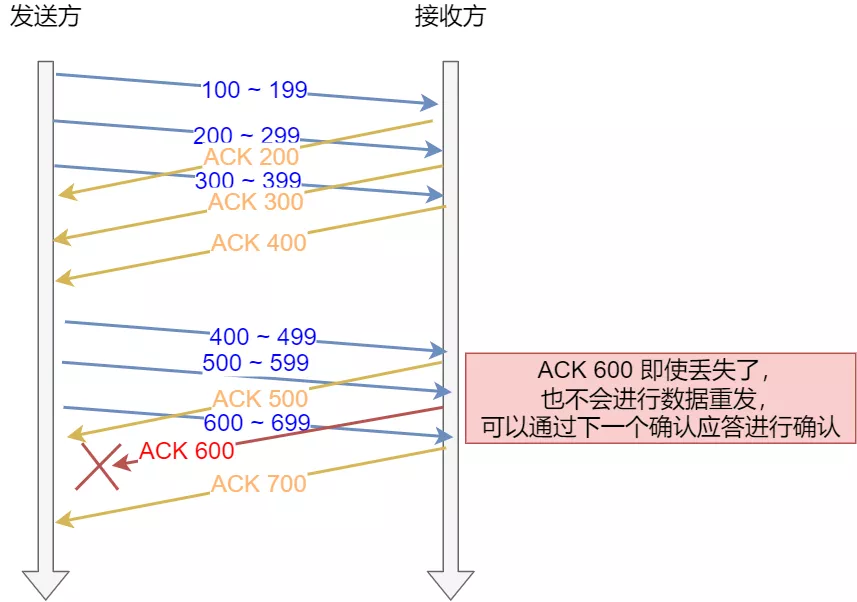
- 累计确认:利用ACK700就能确认前面的数据发送无误,这就是累计确认或者累计应答
32.3.1 窗口大小由哪一方决定?
- TCP 头里有一个字段叫
Window,也就是窗口大小。 - 这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
- 所以,一般是否接收方决定。
- 发送方发送的数据大小不能超过接收方的窗口大小,否则接收方就无法正常接收到数据。
32.3.2 程序是如何表示发送方的四个部分的呢?
-
一个指针指向已发送且收到了确认的第一个字节的序列号,绝对指针
-
一个指针指向已发送但未收到了确认的第一个字节的序列号,绝对指针
-
一个指针指向未发送,且超出窗口的第一个字节序列号,相对指针,由第一个指针和窗口大小得到
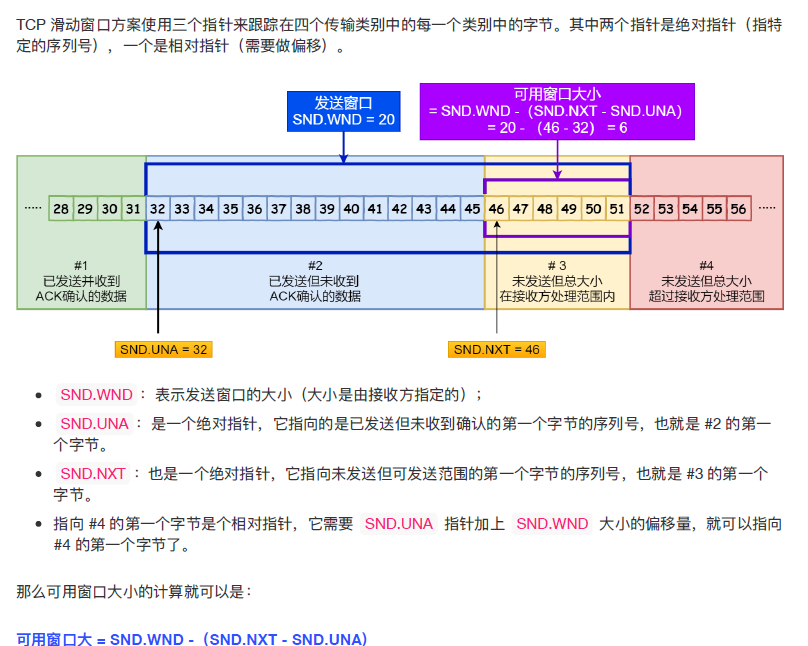
32.3.3 窗口关闭问题如何解决?
- 如果窗口大小为 0 时,就会阻止发送方给接收方传递数据,直到窗口变为非 0 为止,这就是窗口关闭。
- 死锁问题见下图
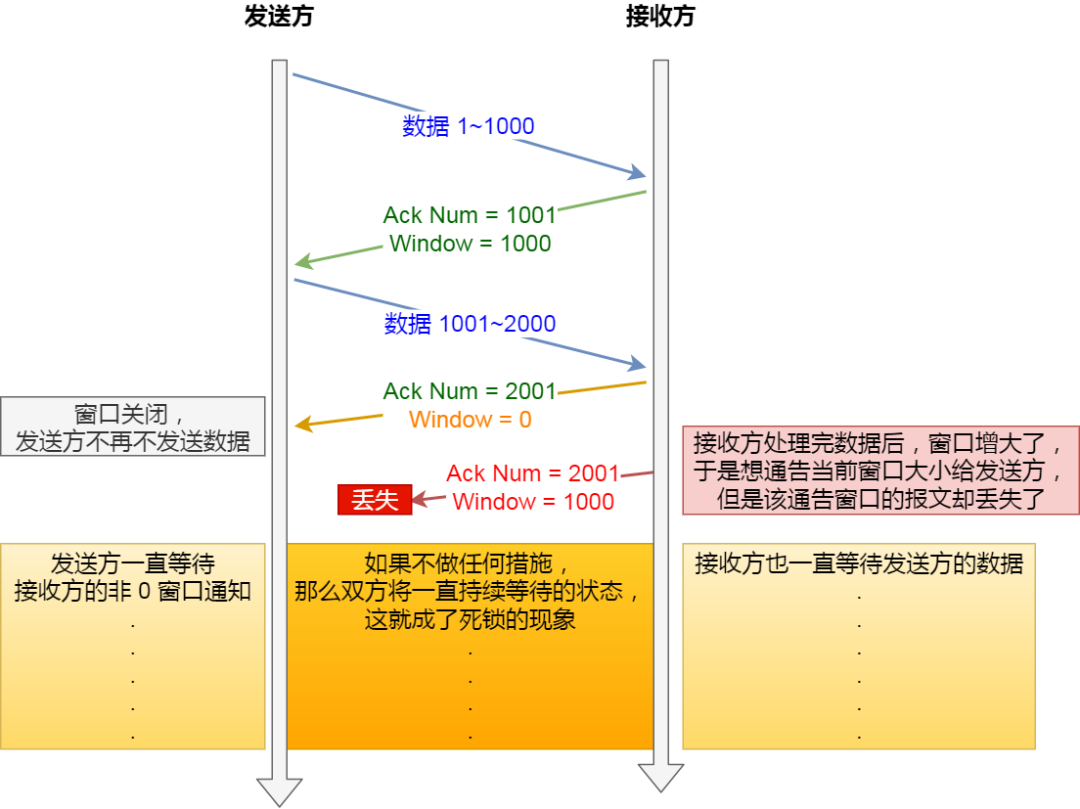
- 解决方法:
- TCP 为每个连接设有一个持续定时器,只要 TCP 连接一方收到对方的零窗口通知,就启动持续计时器
- 如果持续计时器超时,就会发送窗口探测 ( Window probe ) 报文,而对方在确认这个探测报文时,给出自己现在的接收窗口大小
32.3.4 糊涂窗口综合症如何解决?
-
接收方太忙,导致发送方的发送窗口越来越小
-
到最后,如果接收方腾出几个字节并告诉发送方现在有几个字节的窗口,而发送方会义无反顾地发送这几个字节,这就是糊涂窗口综合症
-
TCP + IP头有40个字节,如果只传输几个字节的数据,代价很大 -
问题形成原因:
- 接收方可以通告一个小的窗口(解决:不通告小窗口)
- 而发送方可以发送小数据(解决:避免发送小数据)
-
解决方法:
- 接收方判断窗口大小 < MSS 与 1/2 缓存大小中的最小值时,向发送方通告窗口为
0 - 发送方使用 Nagle 算法
- 要等到窗口大小 >=
MSS或是 数据大小 >=MSS - 收到之前发送数据的
ack回包
- 要等到窗口大小 >=

- 接收方判断窗口大小 < MSS 与 1/2 缓存大小中的最小值时,向发送方通告窗口为
-
Nagle 算法:
- 一个 TCP 连接上最多只能有一个未被确认的未完成的小分组,在它到达目的地前,不能发送其它分组。
- 在上一个小分组未到达目的地前,即还未收到它的 ack 前,TCP 会收集后来的小分组。当上一个小分组的 ack 收到后,TCP 就将收集的小分组合并成一个大分组发送出去。
32.4 流量控制目的?
- 发送方不能无脑的发数据给接收方,要考虑接收方处理能力
- 本质上利用的还是滑动窗口的原理
- 不会发送超过约定的滑动窗口大小的数据
- TCP 通过让接收方指明希望从发送方接收的数据大小(窗口大小)来进行流量控制
32.5 TCP拥塞机制介绍一下?
-
流量控制只能控制通信双方的流量,但是计算机网络是一个共享的环境,有可能会因为其它主机的通信而使得网络拥塞
-
目的
- 防止过多的数据注入到网络中,避免网络中路由器、链路过载
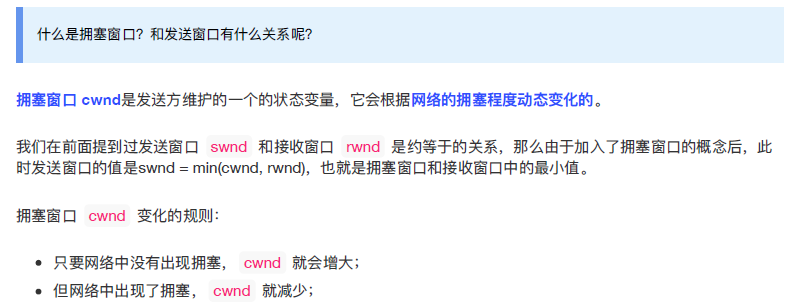
32.5.1 什么是拥塞窗口?和发送窗口有什么关系呢?
- 拥塞窗口 cwnd是发送方维护的一个 的状态变量,它会根据网络的拥塞程度动态变化的
- 发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值
32.5.2 那么怎么知道当前网络是否出现了拥塞呢?
- 发生了超时重传,就会认为网络出现了拥塞
32.5.3 拥塞控制算法介绍一下
32.5.3.1 慢启动
-
一开始一点一点提高发送数据包的数量
-
cwnd = 10
-
当发送方每收到一个 ACK,就拥塞窗口 cwnd 的大小就会加 1
-
呈指数增长
-
慢启动门限
ssthresh:- 默认:65536
- 当
cwnd < ssthresh时,使用慢启动算法。 - 当
cwnd >= ssthresh时,就会使用「拥塞避免算法」。
-
拥塞窗口的1代表的是可以发送一个MSS大小的数据
32.5.3.2 拥塞避免算法
- 每当收到一个 ACK 时,cwnd 增加 1/cwnd
- 将指数级增长变为了线性增长
- 增长速度变慢,但是最终还是会进入网络拥塞
- 此时会采用拥塞发生算法
32.5.3.3 拥塞发生后(超时重传、快速重传)
- 发送端超时重传,出现拥塞
ssthresh设为cwnd/2,cwnd重置为1- 因为超时没有收到任何ack,所以认为网络拥塞严重
- 进入满开始
- 接收端连发3个ack,快速重传
ssthresh = cwnd/2;cwnd = cwnd/2,也就是设置为原来的一半;- 进入快速恢复算法
- 因为还是能连续收到接收方的3个ack,说明拥塞不算太严重
32.5.3.4 快速恢复算法
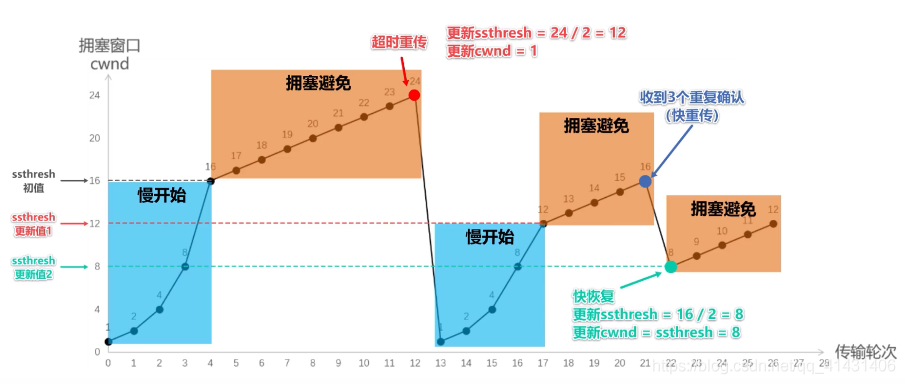
- 发送方一旦收到 3 个重复确认,就知道现在只是丟失了个别的报文段。于是不启动慢开始算法,而执行快恢复算法;
- 发送方将慢开始门限 ssthresh 值和拥塞窗口 cwnd 值调整为当前窗口的一半; 开始执行拥塞避免算法。
- 也有的快恢复实现是把快恢复开始时的拥塞窗口 cwnd 值再增大一些,即等于新的 ssthresh + 3。
- 既然发送方收到3个重复的确认,就表明有3个数据报文段已经离开了网络;
- 这3个报文段不再消耓网络资源而是停留在接收方的接收缓存中;
- 可见现在网络中不是堆积了报文段而是减少了 3 个报文段。因此可以适当把拥塞窗口扩大些。
33. 关闭TCP连接的方法?
- RST 报文关闭
- 进程异常退出,发送RST报文,不走四挥流程,暴力关闭连接
- FIN 报文关闭
34. 调用 close 函数 和 shutdown 函数有什么区别?
close 函数意味着完全断开连接
- 既不能发送,也不能接收
- 调用了 close 函数的一方的连接叫做「孤儿连接」
- 把全双工的两个方向的连接都关闭了
shutdown函数可以通过参数控制只关闭一个方向上的连接
- SHUT_RD(0):关闭连接的「读」这个方向,如果接收缓冲区有已接收的数据,则将会被丢弃,并且后续再收到新的数据,会对数据进行 ACK,然后悄悄地丢弃。也就是说,对端还是会接收到 ACK,在这种情况下根本不知道数据已经被丢弃了。
- SHUT_WR(1):关闭连接的「写」这个方向,这就是常被称为「半关闭」的连接。如果发送缓冲区还有未发送的数据,将被立即发送出去,并发送一个 FIN 报文给对端。
- SHUT_RDWR(2):相当于 SHUT_RD 和 SHUT_WR 操作各一次,关闭套接字的读和写两个方向。

35. TCP全连接队列和半连接队列的作用?
- 服务端并发处理大量请求时,如果 TCP 全连接队列过小,就容易溢出。发生 TCP 全连接队溢出的时候,后续的请求就会被丢弃,这样就会出现服务端请求数量上不去的现象
35.1 全连接队列满了,就只会丢弃连接吗?

tcp_abort_on_overflow 共有两个值分别是 0 和 1,其分别表示:
- 0 :如果 accept 队列满了,那么 server 扔掉 client 发过来的 ack ;
- 1 :如果 accept 队列满了,server 发送一个
RST包给 client,表示废掉这个握手过程和这个连接;
35.2 如何增大 TCP 全连接队列呢?
- TCP 全连接队列足最大值取决于 somaxconn 和 backlog 之间的最小值,也就是 min(somaxconn, backlog)
somaxconn是 Linux 内核的参数,默认值是 128,可以通过/proc/sys/net/core/somaxconn来设置其值;backlog是listen(int sockfd, int backlog)函数中的 backlog 大小,Nginx 默认值是 511,可以通过修改配置文件设置其长度;- NGINX设置
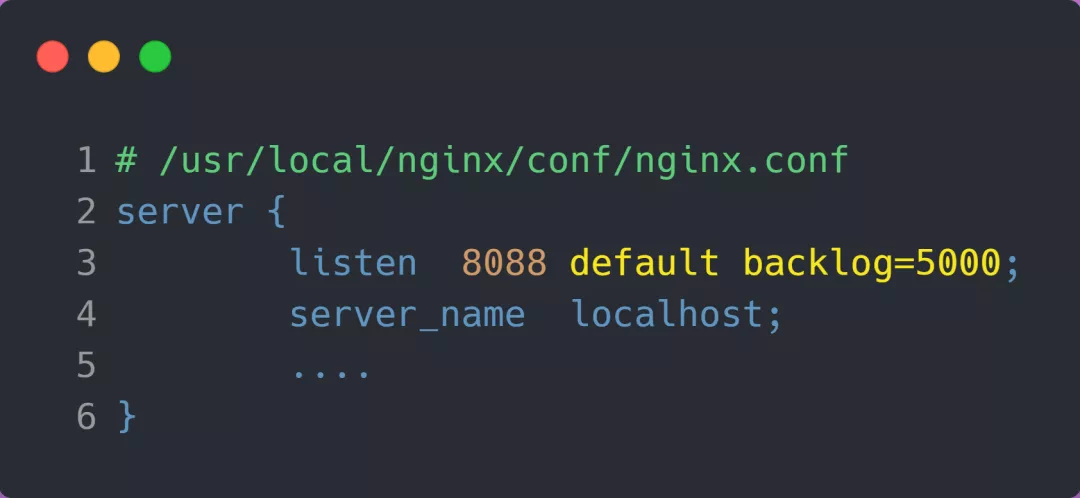
- 服务端执行
ss命令,查看 TCP 全连接队列使用情况:

- 从上面的执行结果,可以发现全连接队列使用增长的很快,但是一直都没有超过最大值,所以就不会溢出,那么
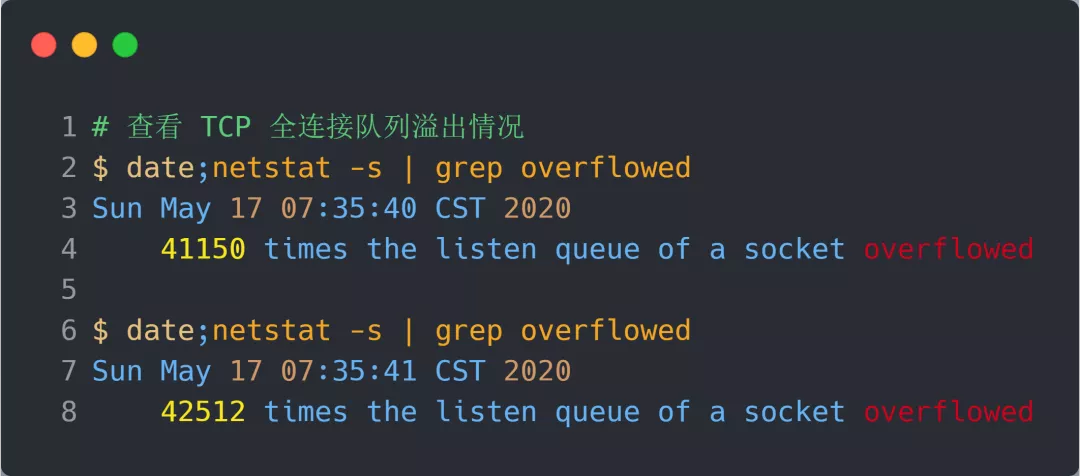
netstat -s就不会有 TCP 全连接队列溢出个数的显示:

- 溢出示例
36. 如何查看 TCP 的连接状态?
TCP 的连接状态查看,在 Linux 可以通过 netstat -napt 命令查看。

37. 假设客户端有多个网卡,就会有多个 IP 地址,那 IP 头部的源地址应该选择哪个 IP 呢?
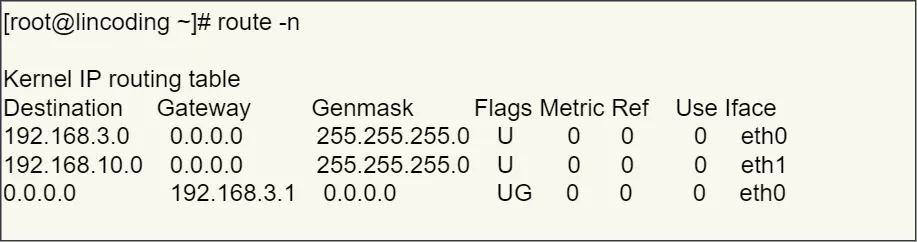
- 此时会根据路由表来进行匹配,确定哪一个网卡作为源地址IP
- 主要是根据网络号进行匹配
- 如果没有匹配,则选用最后一个,表示默认网关
- 即后续就把包发给路由器,
Gateway即是路由器的 IP 地址。
38. 交换机如何转发包信息?
- 交换机的各个端口是没有MAC地址的,是二层网络设备,工作在MAC层
- 交换机的 MAC 地址表主要包含两个信息:
- 一个是设备的 MAC 地址,
- 另一个是该设备连接在交换机的哪个端口上。
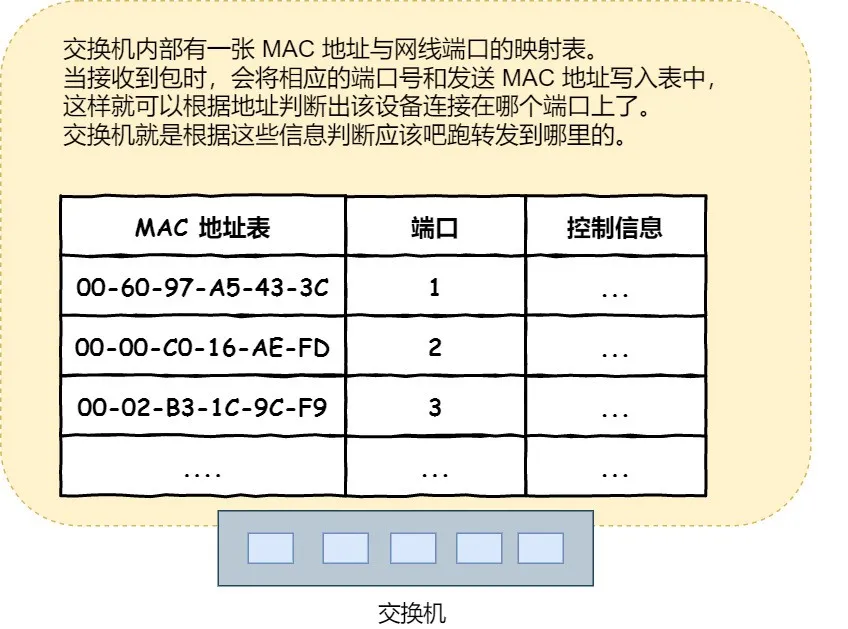
- 根据接收到的包上面的接收方的MAC地址进行匹配,可以得到应该转发到的端口信息。
- 只要有对交换机发送过消息,MAC地址就会记录下来
- 如果没有找到MAC地址,就将包转发到除了源端口之外的所有端口上
39. 路由器是怎么工作的?
- 基于IP设计,三层网络设备,各个端口都有MAC地址和IP地址
- 收到包后,通过包的 MAC 头部判断是否给自己的,是的话就放入缓冲区,否则丢弃
- 然后去掉 MAC 头部,根据 IP 头部的目的IP地址在路由表中进行匹配
- 找到对应的接口信息,然后将报文转发到该接口
- 是在没有找到就会使用最后的默认路由
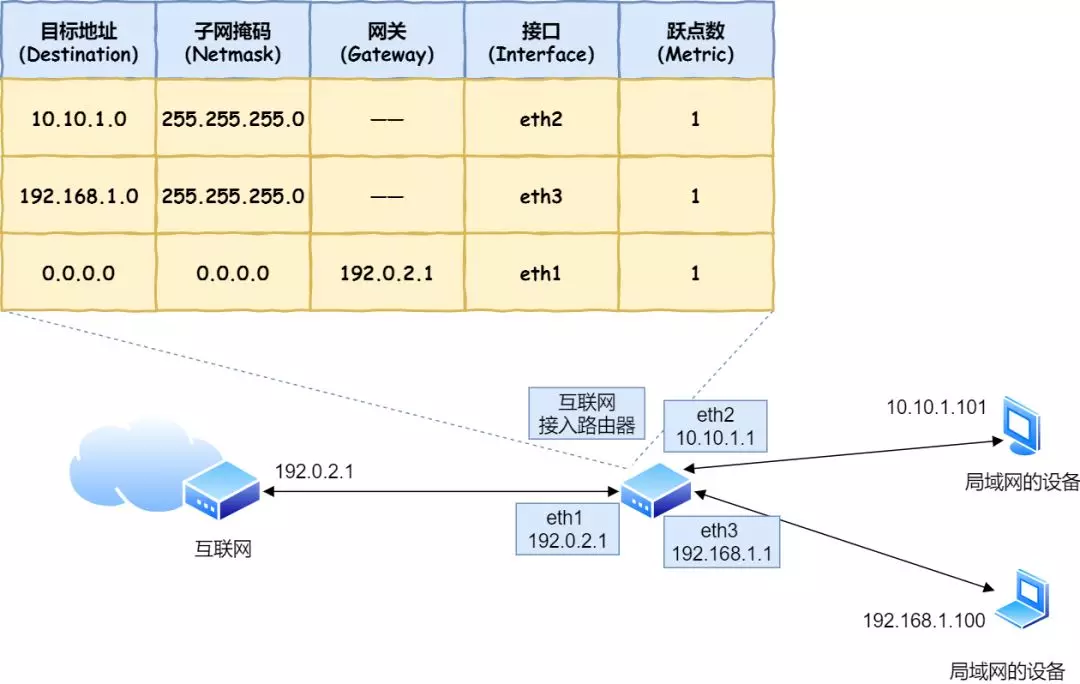
-
通过路由表进行匹配后有两种结果:
- 如果网关是一个 IP 地址,则这个IP 地址就是我们要转发到的目标地址,还未抵达终点,还需继续需要路由器转发。
- 如果网关为空,则 IP 头部中的接收方 IP 地址就是要转发到的目标地址,也是就终于找到 IP 包头里的目标地址了,说明已抵达终点。
-
根据路由表得到的接口就是MAC的发送地址
-
然后查询ARP缓存或者使用ARP广播得到目标地址的MAC地址
-
两者组合得到MAC头部,然后继续进行传输
-
在网络包传输的过程中,源 IP 和目标 IP 始终是不会变的,一直变化的是 MAC 地址,因为需要 MAC 地址在以太网内进行两个设备之间的包传输
40. HTTP 是什么?描述一下
-
HTTP 是超文本传输协议,也就是HyperText Transfer Protocol。
-
HTTP 是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」。
-
HTTP 是超文本传输协议,是在两台计算机之间传送文字、图片、视频等超文本数据的约定和规范
41. 简述 HTTP1.0/1.1/2.0 的区别?
https://mp.weixin.qq.com/s/amOya0M00LwpL5kCS96Y6w
41.1 HTTP1.0
- 默认使用短连接,每次请求都需要建立连接
41.2 HTTP1.1
- 使用 TCP 长连接的方式改善了 HTTP/1.0 短连接造成的性能开销。
- 支持 管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
- 开始支持获取文件的部分内容,这支持了并行下载和断点续传。通过在Header的两个参数实现
存在的问题:
-
高延迟——队头阻塞
- 顺序发送的请求序列中的一个请求因为某种原因被阻塞时,在后面排队的所有请求也一并被阻塞,会导致客户端迟迟收不到数据
-
无状态特性 — 阻碍交互
- 无状态是指协议对于连接状态没有记忆能力
-
明文传输 — 不安全性
- 传输内容没有加密,中途可能被篡改和劫持
-
不支持服务端推送
41.3 HTTP2.0
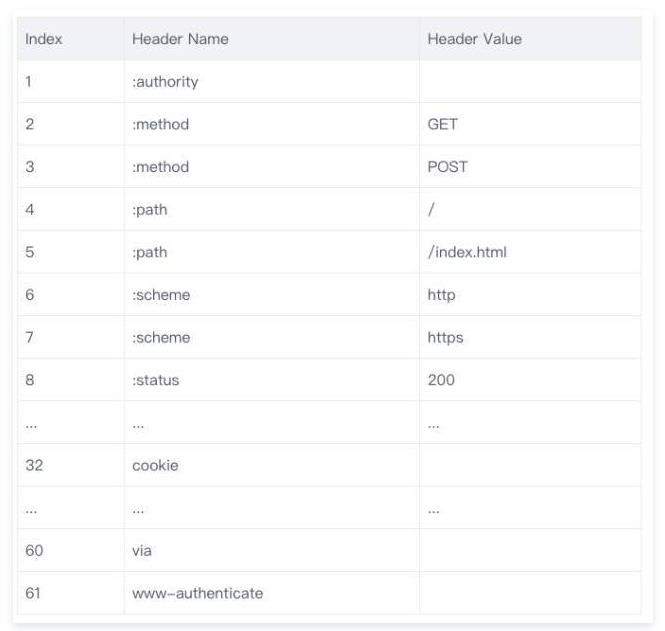
-
头部压缩
- HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复。
- 使用的是HPACK算法。在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了
- 每次请求和响应只发送差异头部
- 原理
- 维护一份相同的静态字典(Static Table),包含常见的头部名称,以及特别常见的头部名称与值的组合;
- 维护一份相同的动态字典(Dynamic Table),可以动态的添加内容;
- 支持基于静态哈夫曼码表的哈夫曼编码(Huffman Coding);
- 静态字典作用:
- 对于完全匹配的头部键值对,例如 “:method :GET”,可以直接使用一个字符表示;
- 对于头部名称可以匹配的键值对,例如 “cookie :xxxxxxx”,可以将名称使用一个字符表示。
- 同时,浏览器和服务端都可以向动态字典中添加键值对,之后这个键值对就可以使用一个字符表示了。需要注意的是,动态字典上下文有关,需要为每个 HTTP/2 连接维护不同的字典。在传输过程中使用,使用字符代替键值对大大减少传输的数据量。
-
二进制格式
- 报文采用二进制格式。头信息和数据体都是二进制,统称为帧:头信息帧和数据帧
- 当计算机收到报文后,无需将明文报文转成二进制,而是直接解析二进制报文,增加了数据传输的效率
-
数据流
- 数据包不按顺序发送
- 每个请求或者回应的所有数据包称为一个数据流
- 每个数据流会标记一个独一无二的编号,其中客户端为奇数,服务器为偶数。
- 使得并行的数据传输成为可能
- 通过标记来指出它属于哪个回应
- 通过给数据包添加标签来区分不同的请求和响应
-
多路复用
- 在一个连接中能够并发多个请求或回应,不用按顺序一一对应
- 最终根据每个请求和响应上的标记组合成正常的请求和响应
- 即对于A、B请求,A的请求在先,但是A的请求处理很慢,B的请求在后,但是处理速度较快。在这种情况下,可以先回应A已完成的部分,然后回应B请求,待A完成后,再回应剩余部分
- 避免了1.1管道传输过程中,由于前面一个请求的响应被阻塞了,导致后面请求的响应也被阻塞了
- 好处
- 单连接多资源的方式,减少服务端的链接压力,内存占用更少,连接吞吐量更大;由于减少TCP 慢启动时间,提高传输的速度
- 在一个连接中能够并发多个请求或回应,不用按顺序一一对应
-
服务器推送
- 服务器不再完全是被动响应
- 譬如说在浏览器请求HTML的时候,可以提前将可能用到的静态文件主动发送给客户端,减少延时等待
-
不足:
- HTTP/1.1 中的管道( pipeline)传输中如果有一个请求阻塞了,那么队列后请求也统统被阻塞住了
- HTTP/2 多请求复用一个TCP连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。
-
不足:
- TCP 以及 TCP+TLS 建立连接的延时
- TCP连接需要3次握手,即1.5个RTT时间
- TLS大致需要1-2个RTT
- TCP 的队头阻塞并没有彻底解决
- 丢包发生时,需要进行重传确认,此时会阻塞整个TCP连接中的所有请求
- 多路复用导致服务器压力上升
- 多路复用没有限制同时请求数
- 请求的平均数量与往常相同,但实际会有许多请求的短暂爆发,导致瞬时 QPS 暴增
- 多路复用容易 Timeout
- 大批量的请求同时发送,由于 HTTP2 连接内存在多个并行的流,而网络带宽和服务器资源有限,每个流的资源会被稀释,虽然它们开始时间相差更短,但却都可能超时
- TCP 以及 TCP+TLS 建立连接的延时
41.4 HTTP3.0
- 将HTTP下层的TCP改成了UDP
- 基于UDP的QUIC协议可以实现类似TCP的可靠传输
- QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响
- QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议
- TL3 升级成了最新的
1.3版本,头部压缩算法也升级成了QPack - HTTPS 要建立一个连接,要花费 6 次交互,先是建立三次握手,然后是
TLS/1.3的三次握手。QUIC 直接把以往的 TCP 和TLS/1.3的 6 次交互合并成了 3 次,减少了交互次数
42. 同步异步、阻塞非阻塞的区别?
- 阻塞/非阻塞:
- 描述的是调用者调用方法后的状态
- 阻塞:调用者在调用方法后需要一直等待结果,不能干别的事情
- 非阻塞:调用者在调用后无需等待,可以干别的事情
- 同步/异步:
- 描述的是方法跟调用者间通信的方式
- 同步:调用的方法需要自身完成,在调用方法后,调用者需要一直等待结果返回,也就是要不停地查询结果是否得出
- 异步:调用的方法无需自身完成,调用方在调用方法后直接返回,调用方法通过回调或者消息通知等方式来通知调用者结果
43. ARP协议可以确定MAC地址,为什么还需要IP协议?
- 使用IP协议更像是一种分层的思想
- ARP协议使用的是广播的方式来确定目标的MAC地址
- 但是在世界范围内不可能通过广播的方式来从数以千万的计算机中找到目标MAC地址而不超时
- 因此通过IP协议将报文送达至指定的网段中,然后再使用ARP协议找到目标的MAC地址
44. 连接异常与RST的区别?
- TCP连接出现严重的错误,必须释放连接就会将报文的RST置位
- 这种方式属于异常终止连接:
- 丢弃任何尚未发送的数据,立即发送 RST 报文段
- RST 接收方会区分另一端是异常关闭还是正常关闭,从而做出不同响应
- 任何收到 RST 段的一方根本不会为这个 RST 进行确认
- 主动发送 RST 段的一方,不会进入 TIME_WAIT 状态
45. 半打开(Half-Open)是什么意思?
- 如果一方已经关闭或异常终止,而另一方却对此毫不知情,这种连接就称为半打开的。
- 处于半打开的 A 向主机 B 发送数据:
- 如果主机 B 仍然断网或者已经连接上网络,但是服务未启动,A 向 B 发送数据,经过数次超时重传后放弃连接,并发送 RST 段给对方(不一定非得发送,这系统实现有关)。
- 如果主机 B 已经连接上网络且重新启动了服务,A 向 B 发送数据,B 收到后因为不认识这个连接,向 A 发送 RST 段。
46. 累计确认和捎带确认是什么意思?

累计确认:累计多个 TCP 段,最后一次确认
捎带确认:将 ACK 确认先不发送,等到有数据发送的时候,和数据一起发送,捎带过去
47. PSH标志位的作用?
- 用来通知TCP什么时候将数据发送出去(从发送缓冲区中取数据),以及 read 函数什么时候将数据从接收缓冲区读取都是未知的
- 发送方由TCP模块自行决定什么时候将缓冲区数据打包成TCP报文,并加上PSH标志。一般来说,write一次就会发送一次,或者缓冲区满了也会立即发送
- 接收方收到了包含PSH标志的TCP报文后,立即将缓冲区的所有数据推送给应用程序
- 总结
- 通知发送方立即发送报文
- 通知接收方立即将数据推送到应用程序
48. UDP相关问题
48.1 概述
- 无连接协议。意味着各个报文没有顺序性,你可能先发了一个数据包 A,后发一个数据包 B,结果对方却先收到 B,后收到 A
- UDP 协议不提供可靠性,这意味着不能保证对端一定能收到数据
48.2 UDP也可以是有连接的
-
有连接的协议,存在 sockname + peername
- bind 函数本质上就是 setsockname,而 connect 函数本质上就是 setpeername 函数
-
无连接的情况,总是缺少 peername
-
如果想让UDP套接字称为有连接,只需要指定它的 peername 即可
- 即在UDP客户端调用 connect 函数
-
有连接的UDP套接字的变化
-
- 不能再使用 sendto 函数指定目的 IP 和 port,这个参数需要指定成 NULL,或者干脆使用 write 函数。
-
- 不需要再使用 recvfrom 来获取数据报的发送者了,应该改用 read 或 recv 等函数。
-
- 有连接的 UDP 套接字引发错误,会返回给它所在的进程。无连接的 UDP 套接字不会。
-
48.3 有连接和无连接的性能比较
- 无连接在每次发送数据时,需要在内核中暂时创建该套接字,发送完数据后再次断开
- 有连接会在第一次的时候建立连接,然后一直复用
- 因此有连接的性能会更好一些
48.4 UDP如何增加可靠性?(使用UDP做为传输层协议时,如何确保数据传输的可靠性?)
- 借鉴TCP的思想,可以采用确认+重传的方式来增加UDP的可靠性
- 与TCP的不同:
- 可靠性的安全机制可以根据自己的需求进行灵活的设计
- 可以利用RUDP 等开源库来实现可靠的UDP传输
49. TCP粘包问题的原因和解决方法是什么?
-
主要原因:
- TCP 协议是面向字节流的协议,它可能会组合或者拆分应用层协议的数据;
- 应用层协议的没有定义消息的边界导致数据的接收方无法拼接数据;
-
发送方原因:
- Nagle算法:
- 当数据包较小时,不会将数据包直接发送出去,而是在缓存区间等待一段时间,看一下后续有没有其它的数据包可以合并一起发送
- 能够降低网络拥塞的可能性,减少数据发送的额外开销(IP首部+TCP首部将近40字节)
- 内核参数:
- TCP_NODELAY
- TCP_CORK
- 延迟发送数据
- 当发送的数据小于 MSS 时,TCP 协议就会延迟 200ms 发送该数据或者等待缓冲区中的数据超过 MSS
- Nagle算法:
-
接收方原因:
- TCP接收到数据包时,并不会马上交到应用层进行处理,或者说应用层并不会立即处理
- TCP将接收到的数据包保存在接收缓存里,然后应用程序主动从缓存读取收到的分组
- 当接收速度大于应用程序的读取速度,应用程序就有可能得到首尾相连粘在一起的包
-
消息边界
- 由于TCP协议是面向字节流的协议,它有可能组合或者拆分应用层协议的数据,因此,应用层的协议需要自己划分消息边界。
- 使用固定长度的消息
- 在协议头中增加表示负载长度的字段
- 举例:
- HTTP 消息中,使用
Content-Length头表示 HTTP 消息的负载大小,这样接收方在接收到足够的字节数后,就可以分离出完整的HTTP消息 - HTTP还会使用基于终结符的策略
- 终结符不能包含在数据正文中
- 在使用块传输机制时,不再包含
Content-Length字段,使用负载为0的HTTP消息作为终结符表示消息的边界
- HTTP 消息中,使用
-
UDP协议是面向报文的
-
UDP的发送单元与应用程序的消息单元是一一对应的关系,因此不存在将包的数据组合或者拆分的问题,本身就具备了消息边界,也就不存在粘包问题
-
单个报文不能超过MTU大小,否则IP层会拆分
-
对于TCP而言,多个数据包可以一次接收完成,然后放在缓冲区中
-
但是对于UDP而言,不论缓冲区有多大,每个数据包需要单独一次接收动作,然后将接收的数据包挂载在接收端的链式结构上,每一次接收端读取数据时会从链上读取一个数据包出来。而且UDP本身支持一对多的通信,因此数据包会保留消息头(消息来源地址、端口等消息),对于接收端而言能够更好地区分不同的数据包,避免粘包问题
50. 点对点和端对端的区别
-
点对点
- ==发送端把数据传给与它直接相连的设备==,这台设备在合适的时候又把数据传给与之直接相连的下一台设备,通过一台一台直接相连的设备,把数据传到接收端
- 优点:发送端发送完数据后,任务就结束了,不会浪费发送端资源
- 如果接收设备故障,就利用存储转发技术进行缓冲
- 不足:发送数据后,不知道接收端是否成功接收和何时接收
-
端对端
- 数据传输前,经过各种各样的交换设备,在两端设备间建立一条链路,就象它们是直接相连的一样,链路建立后,发送端就可以发送数据,直至数据发送完毕,接收端确认接收成功
- 发送前,经过各种交换设备建立一条链路后,发送端再发送数据,而且发送端需要一直等待,直到接收端确认成功
- 优点:确认消息送达,中间设备无需存储转发,延迟低
- 不足:发送端需要一直参与整个过程,浪费发送端资源
- 如果接收设备故障,那么端到端不可能实现
-
数据可靠性
-
数据链路层和网络层一般是点对点
-
传输层一般是端对端
51. 在浏览器输入 URL 回车之后发生了什么?
| 过程 | 使用的协议 |
|---|---|
| 1、浏览器查找域名DNS的IP地址 DNS查找过程(浏览器缓存、路由器缓存、DNS缓存) | DNS:获取域名对应的ip |
| 2、根据ip建立TCP连接 | TCP:与服务器建立连接 |
| 3、浏览器向服务器发送HTTP请求 | HTTP:发送请求 |
| 4、服务器响应HTTP响应 | HTTP |
| 5、浏览器进行渲染 |
-
URL 解析
- 判断输入的是否为一个合法的URL
-
DNS查询(域名解析)
- 首先检查本地是否有缓存
- 浏览器缓存
- 操作系统缓存,本地hosts文件
- 路由器缓存
- IPS DNS 服务器缓存
- 发送网络请求来查询
- 本地域名服务器先找根域名服务器
- 再找顶级域名服务器
- 最后找权威域名服务器
- 首先检查本地是否有缓存
-
得到IP地址后,进行TCP连接
- 三次握手
-
连接成功后,发送http请求
-
服务器处理请求
-
浏览器接收响应
- 对接收到的响应资源分析
- 根据不同的响应码做不同的事情
- 根据响应类型来解析响应内容
-
渲染页面
- 不同内核的渲染过程有所不同
52. 套接字类型有哪些?
- 数据报套接字(Datagram sockets):
- 无连接的服务
- 主要用于UDP协议
- 流套接字(Stream sockets)
- 面向连接
- 主要用于TCP协议
- 原始套接字(Raw sockets)
- 可以直接接收和发送IP数据包,无需基于特定的传输层协议
53. UDP协议的特点?
-
无连接协议,无需建立连接就可以发送数据
-
特点:
- 速度快
- 无需建立连接,因此没有建立连接的时延
- 无连接状态
- TCP需要维护序号、确认号、拥塞控制参数、发送缓存等数据
- UDP没有这些数据,也不存在发送缓存和接收缓存,因此使用UDP协议一般能支持更多的活跃用户
- 报文首部开销小
- 8个字节
- TCP为20字节
- UDP协议本身是不保证报文的可靠送达,但是应用层可以自己采取措施(如增加确认和重传机制),从而保证数据的可靠传输
-
组成:
- 源端口号
- 目标端口号
- 长度
- 校验和
- 前面四个都是16位,一共8字节的头部
- 数据
-
UDP的不可靠原因在于它虽然提供了差错检测(通过校验和),但是对于差错没有恢复功能,更没有重传机制
-
UDP收到应用层数据会立即交给IP层进行发送
54. UDP与TCP区别?
-
TCP提供面向连接的传输,UDP提供无连接的传输
-
TCP提供可靠的传输,UDP不保证可靠传输
-
TCP面向字节流,有额外的分组开销;UDP面向数据报,没有分组开销
-
TCP有拥塞和流控机制;UDP在网络繁忙的情况依然会继续发送
-
上层协议
- UDP:DNS
- TCP:HTTP,FTP
55. DNS何时使用TCP协议,何时使用UDP协议?
- DNS作为应用层协议,占用端口53,同时使用UDP和TCP
- 当DNS进行区域传输的时候会使用TCP协议,其它时候会使用UDP协议
- DNS规范中有两种类型的DNS服务器:主DNS服务器和辅助DNS服务器
- 在一个区中,主DNS服务器从自己本机的数据文件中读取该区的DNS数据信息,而辅助DNS服务器则从区的主DNS服务器中读取该区的DNS数据信息。
- 当一个辅助DNS服务器启动时,它需要与主DNS服务器通信,并加载数据信息,这就叫做区传送(zone transfer)
- 辅助DNS服务器会定时向主DNS服务器同步数据,如果数据变动,则进行区域传送,此时使用TCP,因为传送的数据量较多
- UDP是面向报文的,一般UDP长度不会大于512字节。TCP允许报文长度超过512字节,TCP协议能够对报文进行拆分和重组
- 而且使用TCP保证了数据同步的准确性
- 客户端在进行域名解析的时候会使用UDP协议
- 查询域名的返回结果一般不大于512字节
- 使用UDP能够减轻DNS服务器的负担,提高响应速度
- 很多DNS服务器仅支持UDP查询包
56. 为什么UDP报文大小要小于512字节?
- 在局域网通信的时候,数据帧长度需要在46-1500字节之间,去出到IP头部和UDP报文首部,大概剩下1472字节
- 但是在进行Internet编程的时候,由于Internet上不同路由器的MTU值可能有所不同,如果我们假定MTU为1500来发送数据的,而途经的某个网络的MTU值小于1500字节,那么系统将会使用一系列的机制来调整MTU值,使数据报能够顺利到达目的地,这样就会做许多不必要的操作.
- 鉴于Internet上的标准MTU值为576字节,所以我建议在进行Internet的UDP编程时.最好将UDP的数据长度控件在548字节(576-8-20)以内.
- 因此为了适应网络环境,一般UDP报文的长度不会大于512字节
当然,这个没有唯一答案,相对于不同的系统,不同的要求,其得到的答案是不一样的。
我这里仅对像ICQ一类的发送聊天消息的情况作分析,对于其他情况,你或许也能得到一点帮助:首先,我们知道,TCP/IP通常被认为是一个四层协议系统,包括链路层,网络层,运输层,应用层.UDP属于运输层,
下面我们由下至上一步一步来看:以太网(Ethernet)数据帧的长度必须在46-1500字节之间,这是由以太网的物理特性决定的.这个1500字节被称为链路层的MTU(最大传输单元).但这并不是指链路层的长度被限制在1500字节,其实这这个MTU指的是链路层的数据区.并不包括链路层的首部和尾部的18个字节.
所以,事实上,这个1500字节就是网络层IP数据报的长度限制。因为IP数据报的首部为20字节,所以IP数据报的数据区长度最大为1480字节.而这个1480字节就是用来放TCP传来的TCP报文段或UDP传来的UDP数据报的.又因为UDP数据报的首部8字节,所以UDP数据报的数据区最大长度为1472字节.这个1472字节就是我们可以使用的字节数。
当我们发送的UDP数据大于1472的时候会怎样呢?
这也就是说IP数据报大于1500字节,大于MTU.这个时候发送方IP层就需要分片(fragmentation).
把数据报分成若干片,使每一片都小于MTU.而接收方IP层则需要进行数据报的重组.
这样就会多做许多事情,而更严重的是,由于UDP的特性,当某一片数据传送中丢失时,接收方便
无法重组数据报.将导致丢弃整个UDP数据报。
因此,在普通的局域网环境下,我建议将UDP的数据控制在1472字节以下为好.
进行Internet编程时则不同,因为Internet上的路由器可能会将MTU设为不同的值.
如果我们假定MTU为1500来发送数据的,而途经的某个网络的MTU值小于1500字节,那么系统将会使用一系列的机
制来调整MTU值,使数据报能够顺利到达目的地,这样就会做许多不必要的操作.
鉴于Internet上的标准MTU值为576字节,所以我建议在进行Internet的UDP编程时.
最好将UDP的数据长度控件在548字节(576-8-20)以内
57. 域名分类
- 根域名用"."表示?
58. 根域名服务器的个数?
- IPV4: 13
- IPV6: 25
59. DNS缓存是怎么实现的?
- 进行域名解析的时候,会查看浏览器缓存、系统缓存、hosts文件,都没有才去LDNS查询
- 对于一个域名123.abc.qq.com.cn
- LDNS也会先看一下有没有123.abc.qq.com.cn的缓存,有就直接返回,没有,就继续看一下abc.qq.com.cn,qq.com.cn,com.cn,.cn的权威域名服务器的地址
- 如果有,则直接去对应的服务器那里进行解析
- 没有才去问根服务器
60. ICMP协议介绍一下?
-
ICMP协议,全称Internet Control Message Protocol,也叫互联网控制报文协议
-
常用类型:
- 查询报文
- 用来主动查询网络数据包是否可以到达目标主机
- 差错报文
- 用来通报源主机,发送数据包出错,到不了指定的网络、主机或者端口
- 查询报文
-
查询报文:
- 典型应用为ping程序,一种主动请求,并且获得主动应答的ICMP协议
- 主动请求的报文,称为ICMP请求数据包(ICMP echo request),主动请求的回复,ICMP响应数据包(ICMP echo reply)
-
差错报文
- 当互联网协议在传输过程中发生错误,会给源主机发送ICMP差错报文
- 分类:
- 终点不可达
- 源站抑制
- 源主机发送速度过快,目标主机处理不过来,告诉源主机放慢速度
- 超时
- IP数据报有TTL存活时间,每经过一个路由节点减一,到零还没有送到目标主机,就会发送超时的差错报文
- 路由重定向
- 通知下次发送给另外一个路由
-
典型应用:
-
PING,见下面
-
Traceroute
-
W10下命令:tracert www.baidu.com
-
使用的是ICMP差错报文的原理,可以用来跟踪网络数据包的路由途径
-
traceroute to blog.chenishr.com (120.77.213.253), 30 hops max, 60 byte packets 1 172.17.0.1 (172.17.0.1) 1.168 ms 1.091 ms 1.033 ms 2 192.168.5.1 (192.168.5.1) 15.025 ms 15.352 ms 15.948 ms 3 192.168.0.2 (192.168.0.2) 14.760 ms 14.683 ms 14.621 ms 4 * * * 5 113.106.40.50 (113.106.40.50) 208.131 ms 202.105.155.205 (202.105.155.205) 208.044 ms 61.146.241.233 (61.146.241.233) 208.000 ms 6 183.56.65.6 (183.56.65.6) 208.619 ms 183.56.65.14 (183.56.65.14) 91.293 ms 183.56.65.86 (183.56.65.86) 91.100 ms 7 119.147.223.110 (119.147.223.110) 90.981 ms 92.300 ms * 8 183.2.182.130 (183.2.182.130) 92.160 ms 58.61.162.134 (58.61.162.134) 92.146 ms 92.076 ms 9 183.61.45.10 (183.61.45.10) 92.041 ms 183.2.184.134 (183.2.184.134) 91.943 ms 183.61.45.10 (183.61.45.10) 91.948 ms 10 116.251.113.142 (116.251.113.142) 91.867 ms * 42.120.242.218 (42.120.242.218) 91.772 ms 11 42.120.253.2 (42.120.253.2) 91.730 ms 42.120.253.6 (42.120.253.6) 91.687 ms 116.251.117.153 (116.251.117.153) 103.880 ms 12 * * * 13 * * * 14 120.77.213.253 (120.77.213.253) 103.499 ms 103.443 ms 103.401 ms1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
- 序号表示经过的第几个路由,后接的IP地址即为该路由的IP
- Traceroute默认向每个网关发送三个探测数据包,那三个值是网关响应后返回的时间。星号表示网关没有返回数据
- 底层原理:
- **利用了IP数据报的TTL字段和ICMP的差错类型报文**
- **首先TTL设置为1,得到第一个路由返回的ICMP超时差错报文,以此类推,一直到到达目标主机为止**
- Traceroute 给目标主机发送一份UDP数据,但是端口号为不可能的值(大于30000),目标主机的任何程序都不会使用该端口。这样,目标主机会给程序返回端口不可达的差错报文,程序就会知道数据包已经到达目标主机,不再发送探测报文
- 通过以上信息,就可以将网络数据包的路由途径绘制出来
### 61. PING协议介绍一下?
- ICMP协议
- 互联网报文控制协议,工作在网络层
- 作用
- 确认IP包是否成功送达目标地址,报告发送过程中IP包被废弃的原因、改善网络设置等
- 检测目标地址是否可达
- PING过程
- 源主机构建一个ICMP请求数据包,里面包含了类型字段(8,代表请求数据包),顺序号(用于区分连续ping时发出去的多个数据包,每发一个,增加1),发送时间(用于计算RTT)
- 然后该数据包再加上目标IP地、本机MAC地址和目标MAC地址等信息后,会发送出去
- 目标主机收到数据包后,会构建一个ICMP响应数据包,类型字段为0,序号为接收到的请求报文的序号,然后发送给源主机
- 在规定时间内,如果源主机没有收到ICMP的应答包,说明目标主机不可达,否则,说明主机可达
- **在收到响应后,源主机用当前时刻减去发送时刻,就能得到数据包的延迟时间**
### 62. 长连接和短连接介绍一下?
- 短连接
- 客户端与服务端每进行一次HTTP请求,都会建立一次连接
- 应用场合
- 并发量大,但是每个用户不需要频繁操作的情况
- 用户登录场景
- 长连接
- 报文首部:Connection:keep-alive
- 当客户端和服务端建立连接后,在后续的请求中会复用这个连接,直到某一方主动断开连接
- 服务端会通过探测报文的方法来检测连接中的另外一方是否已经断开
- 如何选择
- 长连接适合操作频繁,点对点通讯,且连接数不会太多的情况
- 数据库连接
- 由于长连接会占用服务端的连接资源,短连接用完就会断开,因此对于大并发,大量连接的场景比较适用
- WEB网站的http服务一般用短连接
### 63. 并行连接是什么?
- 针对短连接的优化方案
- 允许客户端打开多条连接,并行执行多个事务,每个事务都有自己的TCP连接
- 有效利用带宽资源(但是由于带宽有限,因此带宽不足的情况下,性能提升很小)
- 利用浏览器多线程的能力,能够进行并发下载
- 长连接相比于并行连接的优势
- 避免了每个事务都会打开/关闭一条新的连接,造成时间和带宽的耗费
- 避免了 TCP 慢启动特性的存在导致的每条新连接的性能降低
- 可打开的并行连接数量实际上是有限的,持久连接则可以减少建立的连接的数量
### 64. 说一下ssl/tls过程?(Https通信过程)
- https://mp.weixin.qq.com/s/YHLS0WZGgq1SPsPXznIJKg
- 客户端发出一个 client hello 消息,携带的信息包括
- 所支持的SSL/TLS 版本列表;支持的加密算法;所支持的数据压缩方法;随机数A
- 服务端响应一个 server hello 消息,携带的信息包括
- 协商采用的SSL/TLS 版本号;会话ID;随机数B;服务端数字证书 serverCA
- 双向认证的情况下,服务端需要对客户端进行认证,会同时发送一个client certificate request,表示请求客户端的证书
- 客户端校验服务端的数字证书;校验通过之后发送随机数C,该随机数称为pre-master-key,使用数字证书中的公钥加密后发出
- 由于服务端请求客户端的证书,因此,客户端会使用私钥加密一个随机数随着客户端的证书一起发出
- 服务端校验客户端的证书,然后将客户端加密的随机数C解密
- 根据随机数A,B,C产生对称秘钥,加密一个finish消息发送至客户端
- 客户端根据同样的随机数和算法生成对称秘钥,加密一个finish消息发送至服务端
- 双方解密成功后,握手成功,之后的数据均通过对称秘钥加密传输
- https://www.nowcoder.com/discuss/613239?source_id=profile_create_nctrack&channel=-1
1. Client Hello **[客户端]()发起HTTPS请求**
- TLS层协议包含了一个[客户端]()生成的随机数 Random1,[客户端]()支持的加密套件(Support Ciphers)和 SSL Version ([客户端]()可用的版本号)等信息
2.
1. Server Hello **服务端向[客户端]()发送 Server Hello 消息**,这个消息会从 Client Hello 传过来的 Support Ciphers 里确定一份加密套件,这个套件决定了后续加密和生成摘要时具体使用哪些[算法](),另外还会生成一份随机数 Random2。
- 注意,至此[客户端]()和服务端都拥有了两个随机数(Random1+ Random2),这两个随机数会在后续生成对称秘钥时用到。
2. Server Certificate **服务端返回公钥和CA证书(数字证书)到[客户端]()**
- 该证书通常有两个目的:1. 身份验证;2. 证书中包含服务器的公钥,该公钥结合密码套件的密钥协商[算法]()协商出预备主密钥
3. Server Hello Done ,服务器发送完上述信息之后,会立刻发送该信息,然后等到[客户端]()的响应。该信息的主要作用有:
- 服务端发送了足够的信息,接下来可以和[客户端]()一起协商出预备主密钥
- [客户端]()接收到该信息后,可以进行证书校验、协商密钥等步骤
3.
1. Certificate Verify,[客户端]()解析证书,[客户端]()接收后会验证证书的安全性,验证通过后取出证书中的服务端公钥,再生成一个随机数 Random3,再用服务端公钥非对称加密 Random3 生成 PreMaster Key
Client Key Exchange ,上面[客户端]()根据服务器传来的公钥生成了 PreMaster Key,Client Key Exchange 就是将这个 key 传给服务端,服务端再用自己的私钥解出这个 PreMaster Key 得到[客户端]()生成的 Random3。至此,[客户端]()和服务端都拥有 Random1 + Random2 + Random3,两边再根据同样的[算法]()就可以生成一份秘钥,握手结束后的应用层数据都是使用这个秘钥进行对称加密。
- Q:为什么要使用三个随机数呢?
- 这是因为 SSL/TLS 握手过程的数据都是明文传输的,并且多个随机数种子来生成秘钥不容易被暴力破解出来。
2. Change Cipher Spec(Client),通知之后改用会话密钥加密通信
这一步是[客户端]()通知服务端后面再发送的消息都会使用前面协商出来的秘钥加密了
- 该信息用于告诉对方,我已经计算好需要使用的对称密钥了,我们接下来的通信都需要使用该密钥进行加密之后再发送。
- 需要注意的是,发送该信息的一方并不知道对方是否已经计算出密钥。一般由[客户端]()先行发送该信息
3. Finished ,所有握手数据的摘要。
该信息是第一个由TLS记录层协议进行加密保护的信息,双方需要验证对方发送的Finished信息,保证协商的密钥是可用的,保证协商过程中,没有被篡改。验证该verify Data的内容,包括三部分的内容:
- 主密钥
- 标签,[客户端]()的标签是client finished,服务端的标签是server finished
- handshake_messages,包括了所有的握手协议信息
4.
1. Change Cipher Spec(Server)
2. Finshed
SSL加密建立
#### 64.1 要点解析
- 双向认证和单向认证
- 双向认证可以更好地解决身份冒充的问题
- 但是在一些常见的应用场景中,只有单向认证,如采用https的网站只需要求客户端(浏览器)对服务端的证书进行认证
- 单向认证的场景下,第二阶段服务器不会请求客户端的证书
- 随机数的使用
- 通过使用三个随机数,来确保对称秘钥的随机性(SSL 协议中证书是静态的)
- 使用三个随机数,是因为SSL协议不信任每个主机都能产生完全的随机数,因此通过组合3个随机数,减少对称秘钥被识破的可能性
- 会话秘钥重用
- 避免重建连接时再次进行耗时的SSL/TLS握手过程
- 方法:
- SessionID,客户端和服务端同时维护一个会话ID和会话数据状态;重建连接时双方根据sessionID找到之前的会话密钥实现重用
- SessionTicket,由服务端根据会话状态生成一个加密的ticket,并将key也发给客户端保证两端都可以对其进行解密。该机制相较sessionID的方式更加轻量级,服务端不需要存储会话状态数据,可减轻一定压力
- 证书校验
- 检验数字签名
- 数字签名通过数字摘要算法生成并通过私钥加密传输,对端公钥解密;
- CA链授权检查
- 证书过期及激活时间检查
#### 64.2 公钥证书如何生成?
- SSL/TLS通过被称为X.509的证书数字文档将网站和公司实体信息绑定到加密密钥来进行工作
- 通过证书将加密密钥和公司组织进行安全关联
- 申请流程
- 服务端将自己的公钥以及要包含在证书中的信息(如域名,组织,电子邮件地址)生成一个CSR文件发送给数字证书认证机构来部署数字签名
- 数字认证机构会检验其中的信息是否正确,如果正确的话就使用自己的私钥来对证书部署数字签名,然后发送给申请人
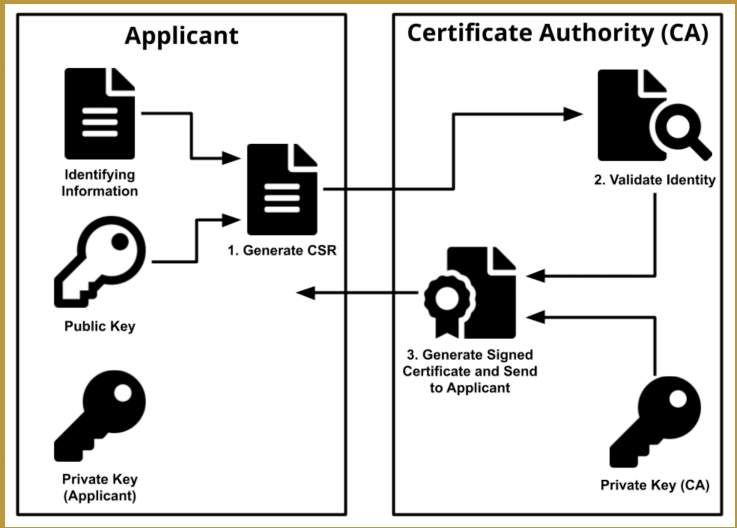
#### 64.3 HTTPS中间劫持?HTTPS一定是安全的吗?
- **什么是HTTPS劫持**?
- 在HTTPS劫持攻击(“中间人攻击”的一种类型)中,网络中的攻击者会伪装成一个网站(例如[facebook]().com),并且提供带有攻击者公钥的假证书。通常,攻击者无法让任何合法的CA来对一个不受攻击者控制的域名的证书进行签名,因此浏览器会检测并阻止这种攻击行为。
- 但是,如果攻击者可以说服用户安装一个新CA的根证书到浏览器当中,浏览器就会信任攻击者提供的由这个合法CA签发的假证书。通过这些假证书,攻击者可以模仿任何网站,进而可以篡改网站内容、记录用户在网站上的操作或发表的内容等。
- 因此,**用户不应该安装根CA证书(受信任证书)**,因为这样就会将原本安全的通信暴露无遗,**导致通信被劫持或篡改而不被用户所感知**。
### 65. 服务端申请证书,客户端验证证书过程详细说一下?
- 证书申请流程
- 服务端将自己的公开秘钥登录至数字证书认证机构
- 数字证书认证机构会用自己的私钥向服务器的公开秘钥部署数字签名并颁发公钥证书
- 证书校验
- 检验数字签名
- 数字签名通过数字摘要算法生成并通过私钥加密传输,对端公钥解密;
- CA链授权检查(证书链验证)
- 通过证书链追溯到可信赖的CA的根。目的是验证签发用户实体证书的CA是否是权威可信的CA
- 因为证书可能不是根CA签发的,可能是下级CA签发的,需要溯源到根CA来验证证书的合法性
- 证书过期及激活时间检查
- 检查有效期
- 域名检查
- 检查证书的域名与当前访问域名是否匹配
- 简单来说,先验证数字签名,判断数据是否在中途遭到恶意修改
- 然后,判断签发数字签名的认证机构是否是权威机构,这个就是通过信任链来进行验证,最终如果能够溯源到根CA的话,那么就是可信的
### 66. 知道http的长连接吗?举个场景说一下
- **长连接能够复用已经建立的TCP连接**
- 因此当打开一个网页的时候,网页包含的一系列资源就可以通过复用同一个TCP连接来进行传输,节省资源开销
- 当一个长连接中,一段时间内没有发送新的消息,那么这个长连接会被断开
### 67. 为什么计算机网络需要分层?
- 各层之间能够相互独立
- 高层不需要知道底层的工作原理,只需要知道底层的接口能够提供什么服务
- 灵活性好
- 每一层可以根据需要采用最适当的技术来实现
- 易于实现和标准化
- 将复杂的通讯过程划分为不同模块的有序交互过程
- 每个模块能够更加容易设计和实现标准化
### 68. 不同层的作用介绍一下?
- 物理层
- 计算机间的物理连线,用来传输0,1信号
- 数据链路层
- 对0,1信号进行分组,规定不同组所代表的含义
- 以太网协议
- 网络层
- 用来判断通信双方是否处于同一子网络中,实现不同网络间的通信
- 传输层
- 实现端口到端口通信,将网络中的数据正确传送给不同的应用程序
- 应用层
- 规定了应用程序的数据格式
### 69. PUT和POST的区别介绍一下?
- PUT是幂等操作
- PUT必须明确知道要操作的对象,如果对象不存在就创建对象,否则,将对象完全替换
- POST不要求幂等
- POST创建对象时,并不知道要操作的对象,由服务器为新建对象生成唯一URI
- 使用POST修改对象时,一般只是修改对象的部分属性
### 70. RESTful如何设计URL?
- REST:Resource Representational State Transfe
- 资源表现形式状态转移
- 通过method实现服务端资源的状态改变
- 协议格式
- Method +空格+URL(资源定向)[?过滤条件]+协议版本+操作符
- GET /order/{orderid} :获取指定订单详情
- Method(资源操作行为,改变资源的状态)
- GET :请求服务器特定资源
- POST :服务器创建一个新资源
- PUT :更新服务器资源(整个资源)
- DELETE :服务器删除特定资源
- PATCH :更新服务器上的资源(资源的部分)
### 71. 访问不了百度的原因?
- 运营商网络出现了问题
- DNS配置错误
- DNS劫持
- DNS服务器返回错误的IP
- 输入爱奇艺的网址,返回优酷的IP
- 服务器错误
- 查看错误代码
### 72. CDN 服务器
- Content Delivery Network 内容分发网络
- 目的是使得用户能够更快地访问文件
- CDN服务器通常分布在各地,将源服务器的数据缓存在CDN服务器中
- 当用户要请求数据的时候,会优先去访问就近的CDN服务器。由于服务器的距离较近,因此响应的成功率和速度会大大提升
- 应用场景
- 网站和应用加速
- 对于网站的静态资源,可以直接缓存在CDN服务器上,用户访问可以就近获取
- 但是对于网站的动态资源,则需要回到源服务器进行处理。对于此,CDN会通过优化算法找出最快的传输路径,提高回源效率
- 视频、大文件下载
- 直播加速
- 主播的数据先传送到CDN服务器,然后用户可以访问就近的CDN服务器来获取资源
### 73. curl 的作用?
- https://mp.weixin.qq.com/s/lEX5r6RVd_6UhM1ifrzbaA
- 命令行工具,用于请求web服务器
- 常用命令:
- 不带任何参数,默认是get请求
- curl https://www.example.com
- -b 能携带cookie
- curl -b 'foo=bar' https://google.com
- -X POST 发送post请求
- curl -X POST https://google.com/login
- -d发送携带数据体的post请求,此时可以省略上面的-X POST
- ```shell
curl -d'login=emma&password=123' https://google.com/login -
-G参数用来构造 URL 的查询字符串
- curl -G -d ‘q=kitties’ -d ‘count=20’ https://google.com/search
- 省略-G会发送post请求
-
-
感觉命令太多了,可能记不住,平常还是使用postman较多
74. cookie
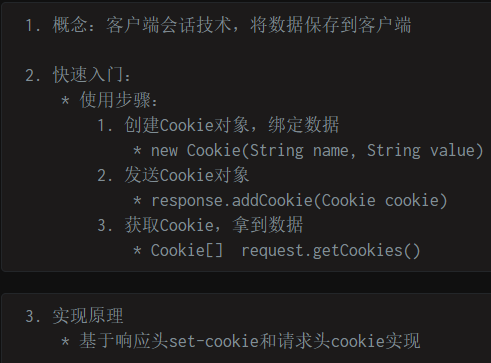
- 默认浏览器关闭的时候被销毁,默认值为负值,如果为正值,那么时间到了就自动失效,0则直接删除
- 通过setMaxAge来设置
75. Session
- 服务器端会话技术,在一次会话的多次请求间共享数据,将数据保存在服务器端的对象中。HttpSession
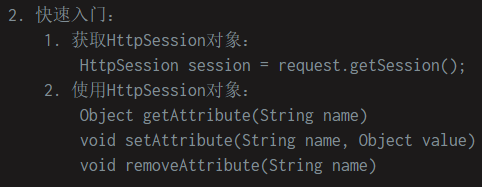
-
Session的实现依赖于cookie
-
session.invalidate(),强制清除session
-
否则,从最后一次访问起,过了30分钟会自动清除,如果中途有访问,则刷新时间
-
存储结构:
- 实际上是一个ConcurrentHashMap
-
存储位置:
- session是存储在servlet容器中的
- 对于Spring WEB应用而言,Context相当于servlet容器的抽象
- 其中对于内嵌Tomcat,默认使用的Context对象就是TomcatEmbeddedContext
- 该context对象继承于StandardContext,其中有一个Manager类型的内部属性
- 该内部属性维护了一个sessions,用于存储session,而这个数据结构为ConcurrentHashMap
- 该map的key一般使用String类型
-
默认失效时间
- 30分钟
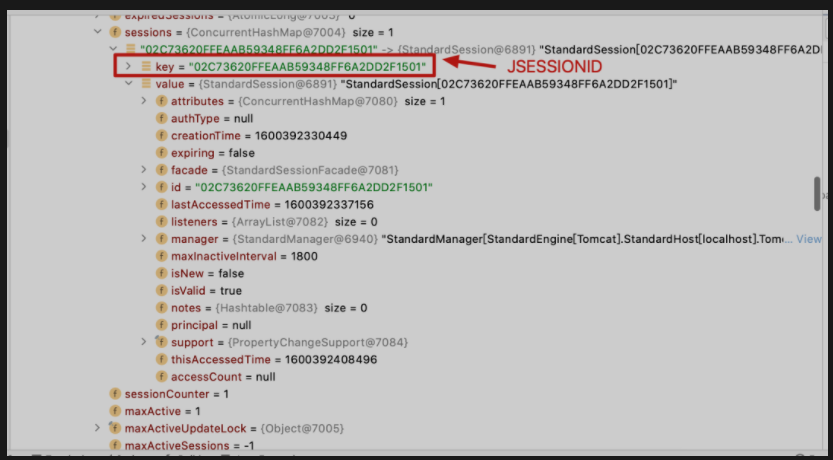
- 如果禁用了cookie怎么办?
- url重写技术来传送sessionID
- 或者通过表单隐藏字段来传送sessionID
77. ARQ协议是什么?
-
ARQ协议,自动重传请求(Automatic Repeat-reQuest)。该协议是对滑动窗口的一个实现
-
保证TCP可靠性的机制之一
-
停止等待ARQ协议
- 每次发送一个分组后,停止发送并等待接收方响应
- 一段时间内没有收到确认,就重传
- 直到收到确认才会发送下一个分组
- 不足:
- 信道的利用率低,等待时间久
-
连续ARQ协议
- 利用滑动窗口,维护了无需接收方确认也可以继续发送的数据范围
- 提高了信道利用率
78. 服务端出现大量的 timewait 的原因和解决方法?
-
如何查看
-
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
-
netstat -an |grep TIME_WAIT|wc -l 查看连接数等待time_wait状态连接数
-
通过上述命令可以查看不同状态下的TCP连接的数目
-
问题
- 大量连接处于timewait状态时,新建立TCP连接会报错,错误为“接口已被占用”
- 本地端口数目上限为65536(端口号16位)
-
出现原因
- 大量的短连接
- 高并发短连接
- 在HTTP请求中,如果connection头部的取值设置为close,那么基本都由服务端主动关闭连接
- 服务端处理完请求后主动关闭连接
- 在四挥关闭连接机制中,为了确保确认报文能够正确送达以及本次连接中的报文能全部消亡,会设置timewait状态的时间为2倍的最大报文存活时间(一共大概为4分钟)
- RFC 793中规定MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟等
- 大量的短连接
-
解决方法
-
客户端:
- connection 设置为 keep-alive,即尽量使用长连接(目前版本的http协议基本上都是长连接)
-
服务端:
- 允许time_wait状态的socket被重用
- net.ipv4.tcp_tw_reuse = 1
- 满足以下条件之一:
- 初始序列号比TW老连接的末序列号大
- 如果使能了时间戳,那么新到来的连接的时间戳比老连接的时间戳大
- 缩减time_wait的时间,设为1MSL
- 增加服务器,进行负载均衡
- 允许time_wait状态的socket被重用
79. 常见应用层、运输层、网络层协议,以及硬件如路由器位于哪一层?
- 应用层
- HTTP,DNS,FTP
- 传输层
- TCP,UDP
- 网络层
- IP,ICMP,路由器,防火墙
- 数据链路层
- 网卡,网桥,交换机
- 物理层
- 中继器,集线器
80. 以太网报文格式?
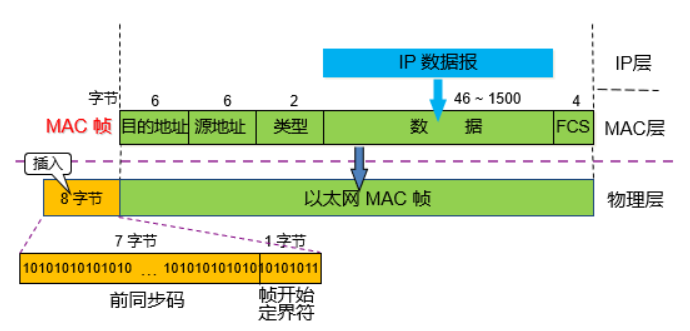
- 目标地址、源地址
- 网卡的硬件地址(MAC地址),网卡出厂时固化
- 数据
- 以太网帧中数据长度最小为46字节,最大为1500字节
- 不够长需要进行填充,太长了需要进行拆分
- 1500字节是指有效负载的长度,不包括首部长度
81. HTTP和TCP的区别?
- 前者是应用层协议,后者是传输层协议
- HTTP规定每段数据以什么形式表达才能被另外一台计算机理解
- TCP则是规定数据应该怎么传输才能稳定、高效地在计算机之间传输
- 应用层协议的通信依赖于传输层协议
82. HTTP常用首部字段有哪些?
- accept
- 表明客户端浏览器能够接收的媒体类型资源
- accept-encoding
- 表明客户端浏览器接收的编码方式
- accept-language
- 表明客户端浏览器接收的语言
- cache-control
- 控制浏览器缓存
- 如果使用缓存,后续访问相同页面则直接访问缓存
- cookie
- 保存用户会话信息
- refer
- 告诉服务器从哪个页面链接进来
- user-agent
- 浏览器的相关信息
- host
- 请求时服务器的ip和端口号
- Content-Type
- 服务器告诉客户端本次响应体数据格式以及编码格式
- Set-Cookie
- 用于服务器向客户端发送 sessionID
- 服务端向客户端设置cookie
83. 为什么会丢包?
- 接收到包在进行校验的时候出错
- 数据包在网络中超出最大存活时间(ttl)
- 路由器接收分组数量达到上限后,会丢弃多余分组
- 网络断路
84. 301和302的区别有哪些?
-
301 是永久重定向
-
302 是临时重定向
-
对于永久重定向,如果旧的URI保存为书签了,那么永久重定向会根据响应内容将标签的URI修改。临时重定向是不会修改的
-
使用302重定向有可能被判断为网站URL劫持,一个网站A的功能就是临时重定向到网站B,由于网站A的URL可能更加简洁,导致搜索引擎可能会判断网站A的网址更加合适,这时候搜索引擎的结果仍然是网站A,但是所用的网页内容却是网站B的
85. TCP的保活计时器的作用
- TCP的Keepalive,用来检查对方是否有发生异常,如果发生异常就即时关闭连接
- 当连接空闲一段时间,就会发送探测报文,判断对方的响应是否符合预期,如果不正常就主动关闭连接
- 使用SO_KEEPALIVE的套接字选项——相当于心跳包,一段时间没有响应就断开连接
86. 什么是连接?
- 所谓的连接其实只是双方都维护了一个状态,通过每一次通信来维护状态的变更,使得看起来好像有一条线关联了对方。
87. OSI七层模型的含义和作用是什么?
- 物理层
- 包含了网络通信的基础设施
- 包含了节点设备、网络硬件、设备接口、电缆协议等技术,主要功能是用来传输比特流
- 数据链路层
- 对比特流进行分组,规定不同组所代表的含义
- 允许局域网中各个节点彼此相互通信。建立了线路规划、流量控制和错误控制的基础
- 数据的传输格式、节点间流动的数据量大小
- 线路规划
- 流量控制
- 错误控制
- 数据单元是帧,包含帧头、主体和帧尾
- 帧头:通常包括源节点和目的节点的 MAC 地址
- 主体:由要传输的比特组成
- 帧尾:包括错误检测信息
- 帧的大小有限制,限制值为最大传输单元(MTU)
- 网络层
- 判断计算机是否处于同一个网络中,实现不同网络之间的通信
- 数据单元是数据包,会封上IP地址
- 不保证可靠传输
- ARP协议既属于数据链路层,其实也属于网络层,因为IP地址只在这层能够使用,因此需要在该层通过ARP协议定位MAC地址
- 传输层
- 实现端口到端口通信,将网络中的数据正确传送给不同的应用程序
- 会话层
- 会话层负责初始化、维持并终止两个用户应用程序之间的连接
- 这个连接可用是客户端与服务器模型,也可以是请求与响应模型(会话期间可能会有多个请求和响应)
- 例子:RPC调用
- 表示层
- 负责数据格式,比如字符编码与转换,以及数据加密
- 该层负责确保第七层中的用户程序可以成功消费数据,确保最终数据的展示
- 例子:TLS/SSL协议位于第六层,TLS是SSL的继任者
- 应用层
- 负责提供应用程序运行时所需要的服务和功能
- 例子:http,ftp
88. 常用TCP选项有哪些?
- 时间戳选项
- 发送方在报文中放置时间戳,接收方在接收确认中返回该数字,允许发送方为每一个ack计算RTT
- 在复用time_wati接口的时候,如果开启时间戳选项的话,那么新连接的时间戳应该大于旧连接的时间戳
- 最大报文传输字段(MSS)
- TCP数据包每次传输的最大数据分段大小
- 选择确认选线(SACK)
- 快速重传中,接收方用来通告发送发自己的缓存地图
- Window Scale:窗口缩放选项
- 将窗口大小进行缩放
89. 半打开和半关闭的区别?
- 半关闭
- 连接中的一方已经发送了fin报文,等待另外一方发送
- 半打开
- 连接中的一方已经崩溃下线了,另外一端还不知道
90. close-wait 过多的原因和解决方法?
-
根本原因是服务端在四挥的最后流程中,没有正确close掉连接
-
也有可能全连接队列过长,还没有处理,就被对方关闭了
-
解决方法
- 检查代码中是否有死循环或者耗时任务导致没有正确close掉连接
91. TCP异常原因有哪些?
- 试图与一个不存在的端口建立连接
- 虽然服务端的进程没有启动,但是操作系统会帮我们自动响应RST给客户端
- 试图与一个不存在的主机上面的某端口建立连接
- 如果connect没有设置超时的话,那么客户端会继续尝试发送syn报文一段时间,直到TCP的保护机制返回错误
- 为了避免多次发送请求带来的延时问题,可以在connect函数中设置超时时间
- server进程阻塞
- server进程无法响应任何请求,连接能正常建立,但是发送的数据会一直保存在缓冲区,永远不会返回结果
- 杀死server
- 其实这个应该不算异常
- 这时候相当于服务端主动关闭连接,走正常的四挥流程
92. 常用的网络工具 telnet、nc、netstat,介绍一下?
-
telnet 命令可以用来判断远端服务器指定端口的网络连接是否可达
-
telnet [domainname or ip] [port]
-
nc
- nc -l -p 9090
- -l表示监听
- -p代表要监听的端口
- 这个一般用于服务端,打开某个端口
- nc ip port
- 客户端连接服务端的某个接口
- 连接成功后可以在客户端发送数据给服务端
- nc -l -p 9090
-
该工具同样可以检测服务器的端口的网络连接是否可达
- nc -zv [host or ip] [port]
- -z表示不发送任何数据包,tcp三次握手后自动退出进程
- -v用来输出更多详细信息
- echo ping | nc localhost 6379
- 还可以通过管道的方式将命令发送给redis服务器
- nc -zv [host or ip] [port]
-
netstat
- 部分介绍可以查看linux面试题部分
- 常用的选项就是-anp,显示所有套接字,禁止使用端口别名,显示占用端口的进程
93. tcpdump用法?
-
https://juejin.cn/book/6844733788681928712/section/6844733788849717262
-
抓包工具
- wireshark
- 图形化界面抓包软件,一般Windows下使用较多
- tcpdump
- 命令行网络流量分析工具
- wireshark
-
tcpdump
- -i
- 用来指定网卡,通过ifconfig来查看有哪些网卡可用
- any 的话表示任意网卡
- -n
- 将主机名替换为ip地址
- -nn
- 在前述基础上,不会将端口名替换为协议名,使用端口本来的名称
- -s
- 获取报文中的前多少个字节,一般配合-A使用
- sudo tcpdump -i any -nn port 80 -A -s 500
- 如果想显示全部就使用 -s 0
- -c
- 抓取指定数目的报文
- sudo tcpdump -i any -nn port 80 -c 5
- 只抓5个包就退出了,一般用于交互频繁的服务器上抓包
- -w
- 将数据报文件输出到文件
- sudo tcpdump -i any port 80 -w test.pcap
- 生成的pcap文件可以使用wireshark 打开进行更加详细的分析
- -S
- 显示seq和ack的绝对序号
- 默认显示的是相对序号
- -i
-
tcpdump -i any host 10.211.55.2
- host选项,用来指定要捕获的特定IP的包,这个IP既可以是源地址也可以是目标地址
-
过滤源地址和目标地址
- sudo tcpdump -i any src 10.211.55.10
- 用来抓取主机10.211.55.10 发送的包
- sudo tcpdump -i any dst 10.211.55.10
- 用来抓取主机 10.211.55.10 收到的包
- sudo tcpdump -i any src 10.211.55.10
-
指定端口
- sudo tcpdump -i any port 80
- 只抓取端口80上的包
- 配合dst可以只抓取80端口收到的包
- tcpdump portrange 21-23
- 可以抓取21-23区间上所有端口的流量
- sudo tcpdump -i any port 80
-
指定协议
- sudo tcpdump -i any -nn udp
- 只抓udp的包
- sudo tcpdump -i any -nn udp
-
查看报文内容
- sudo tcpdump -i any -nn port 80 -A
- -A选项,以ASCII 格式查看报文内容
- 常用的HTTP协议中传输的json、html文件都可以使用这个选项
- sudo tcpdump -i any -nn port 80 -X
- 同时使用HEX和ASCII显示报文内容
- sudo tcpdump -i any -nn port 80 -A
-
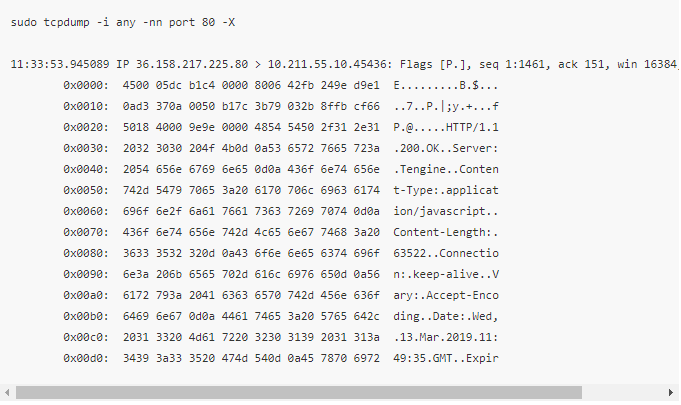
ASCII
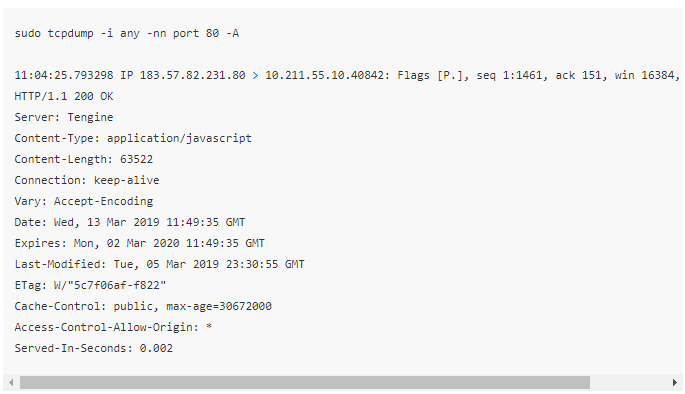
- HEX 和 ASCII
- 复杂过滤器
- 利用布尔运算符组合出复杂的过滤器
- sudo tcpdump -i any host 10.211.55.10 and dst port 3306
- 抓取 ip 为 10.211.55.10 到端口 3306 的数据包
- sudo tcpdump -i any src 10.211.55.10 and not dst port 22
- 抓取源 ip 为 10.211.55.10,目标端口除了22 以外所有的流量
- sudo tcpdump -i any ‘src 10.211.55.10 and (dst port 3306 or 6379)’
- 如果用到特殊字符’()'的话,就需要使用单引号将复杂组合条件包起来
- 过滤特殊控制位的包
- tcpdump ‘tcp[13] & 4 != 0’
- 过滤RST报文
- tcpdump ‘tcp[13] & 18 != 0’
- 过滤SYN+ACK报文
- tcpdump ‘tcp[13] & 4 != 0’
94. wireshark用法
- https://juejin.cn/book/6844733788681928712/section/6844733788853895182
- https://blog.csdn.net/wangyiyungw/article/details/82178070
95. session对服务器的压力问题和JWT
-
session在服务端保存用户的会话信息,当用户并发数大的时候,服务端的压力较大
-
可以考虑将部分数据使用cookie的方式存储到客户端浏览器
-
但是cookie本身不支持大量数据存储,而且使用cookie传输会增加网络压力,此时可以使用HTML5技术,使用浏览器的localStorage和sessionStorage来解决问题
-
当然亦可以在后台引入分布式存储机制来解决
-
针对cookie明文保存的不足,引入JSON Web Token(JWT)机制
-
其中Token用来将用户信息保存在客户端,
-
信息本身通过添加数字签名的方式来防止被篡改
-
token的数据一般保存在HTTP Header “X-Auth-Token”中,客户端在拿到数据后就可以将其保存在本地
-
JWT本身由三个部分组成:头部,载荷,签名
-
头部声明签名算法:对称或者非对称,推荐使用非对称
-
载荷可以保存特定用户信息,但是不能保存私密信息,因为是通过明文传输的
-
签名根据头部算法对头部和载荷数据生成一个签名
-
使用JWT可以比较容易地实现单点登录
-
认证中心保存私钥,其它服务保存公钥,当请求携带token访问时,使用公钥进行验证,合理即可使用,否则重定向到认证中心
-
认证功能这部分可以集成到网关API
96. CSRF 跨站点请求伪造 了解吗?
- 攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
- 大多数用户并不能保证:
- 不能保证关闭浏览器了后,本地的Cookie立刻过期,上次的会话已经结束
- 不能保证登录了一个网站后,不再打开一个tab页面并访问另外的网站
- 由于cookie的信息在访问对应域名的网站的时候会自动携带过去,因此就可以在用户无感的情况下直接攻击目标网站
96.1 有哪些攻击类型?
-
GET类型的CSRF
- GET类型的CSRF利用非常简单,只需要一个HTTP请求,一般会这样利用:在受害者访问含有这个img的页面后,浏览器会自动向
<img src=``"http://bank.example/withdraw?amount=10000&for=hacker"> -
POST类型的CSRF:
- 这种类型的CSRF利用起来通常使用的是一个自动提交的表单,访问该页面后,表单会自动提交,相当于模拟用户完成了一次POST操作。POST类型的攻击通常比GET要求更加严格一点,但仍并不复杂。任何个人网站、博客,被黑客上传页面的网站都有可能是发起攻击的来源,后端接口不能将安全寄托在仅允许POST上面
-
链接类型的CSRF:
- 这种需要用户点击链接才会触发。这种类型通常是在论坛中发布的图片中嵌入恶意链接,或者以广告的形式诱导用户中招,攻击者通常会以比较夸张的词语诱骗用户点击
96.2 特点是什么?
- 攻击一般发起在第三方网站,而不是被攻击的网站。被攻击的网站无法防止攻击发生
- 攻击利用受害者在被攻击网站的登录凭证,冒充受害者提交操作;而不是直接窃取数据。
- CSRF通常是跨域的,因为外域通常更容易被攻击者掌控。但是如果本域下有容易被利用的功能,比如可以发图和链接的论坛和评论区,攻击可以直接在本域下进行,而且这种攻击更加危险。
96.3 如何防御?
- token;token 验证的 CSRF 防御机制是公认最合适的方案。但若网站同时存在 XSS 漏洞的时候,这个方法也是空谈
- https://www.cnblogs.com/lsdb/p/9591399.html
- token不放cookie(一般form表单加个hidden属性的input标签来存放)csrf就没法获取token,这样我们就可以通过检测发送过来的数据包中是否有正确的token值来决定是否响应请求。
- 可以考虑直接使用sessionid作为token,不过通过隐藏表单项提交作为验证手段
- 验证码;强制用户必须与应用进行交互,才能完成最终请求。此种方式能很好的遏制 csrf,但是用户体验比较差
- Referer check;请求来源限制,此种方法成本最低,但是并不能保证 100% 有效,因为服务器并不是什么时候都能取到 Referer,而且低版本的浏览器存在伪造 Referer 的风险
- 浏览器禁止发送referer或者使用APP就不会有referer
97. XSS攻击是什么?
-
XSS全称cross-site scripting(跨站点脚本),是一种代码注入攻击,是当前 web 应用中最危险和最普遍的漏洞之一。攻击者向网页中注入恶意脚本,当用户浏览网页时,脚本就会执行,进而影响用户,比如关不完的网站、盗取用户的 cookie 信息从而伪装成用户去操作,危害数据安全。
-
举例:
-
存储型XSS(持久性跨站攻击)
- 通过表单输入(比如发布文章、回复评论等功能中)插入一些恶意脚本,并且提交到被攻击网站的服务器数据库中。当用户浏览指定网页时,恶意脚本从数据库中被加载到页面执行,QQ邮箱的早期版本就曾经被利用作为持久型跨站脚本攻击的平台。
- 与反射型 XSS 相比,该类的攻击更具有危害性,因为它影响的不只是一个用户,而是大量用户,而且该种类型还可进行蠕虫传播。
97.1 如何防范措施?
-
不相信用户输入的数据
-
对输入数据进行“消毒”
各层必备知识
协议层次以及服务类型
OSI 七层模型
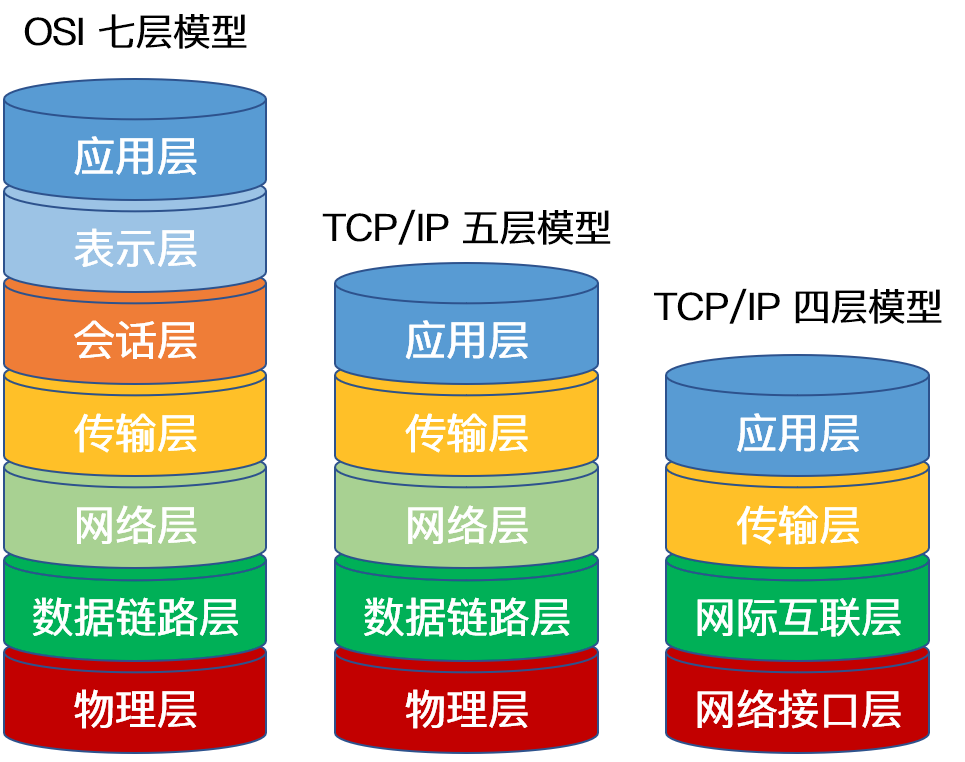
OSI 模型全称为开放式通信系统互连参考模型,是国际标准化组织 ( ISO ) 提出的一个试图使各种计算机在世界范围内互连为网络的标准框架。 OSI 将计算机网络体系结构划分为七层,每一层实现各自的功能和协议,并完成与相邻层的接口通信。OSI 的服务定义详细说明了各层所提供的服务。某一层的服务就是该层及其下各层的一种能力,它通过接口提供给更高一层。各层所提供的服务与这些服务是怎么实现的无关。
① 应用层
应用层位于 OSI 参考模型的第七层,其作用是通过应用程序间的交互来完成特定的网络应用。该层协议定义了应用进程之间的交互规则,通过不同的应用层协议为不同的网络应用提供服务。例如域名系统 DNS,支持万维网应用的 HTTP 协议,电子邮件系统采用的 SMTP 协议等。在应用层交互的数据单元我们称之为报文。
② 表示层
表示层的作用是使通信的应用程序能够解释交换数据的含义,其位于 OSI 参考模型的第六层,向上为应用层提供服务,向下接收来自会话层的服务。该层提供的服务主要包括数据压缩,数据加密以及数据描述。这使得应用程序不必担心在各台计算机中表示和存储的内部格式差异。
③ 会话层
会话层就是负责建立、管理和终止表示层实体之间的通信会话。该层提供了数据交换的定界和同步功能,包括了建立检查点和恢复方案的方法。
④ 传输层
传输层的主要任务是为两台主机进程之间的通信提供服务。应用程序利用该服务传送应用层报文。该服务并不针对某一特定的应用,多种应用可以使用同一个传输层服务。由于一台主机可同时运行多个线程,因此传输层有复用和分用的功能。所谓复用就是指多个应用层进程可同时使用下面传输层的服务,分用和复用相反,是传输层把收到的信息分别交付上面应用层中的相应进程。
⑤ 网络层
两台计算机之间传送数据时其通信链路往往不止一条,所传输的信息甚至可能经过很多通信子网。网络层的主要任务就是选择合适的网间路由和交换节点,确保数据按时成功传送。在发送数据时,网络层把传输层产生的报文或用户数据报封装成分组和包向下传输到数据链路层。在网络层使用的协议是无连接的网际协议(Internet Protocol)和许多路由协议,因此我们通常把该层简单地称为 IP 层。
⑥ 数据链路层
数据链路层通常也叫做链路层,在物理层和网络层之间。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层协议。在两个相邻节点之间传送数据时,数据链路层将网络层交下来的 IP 数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息。通过控制信息我们可以知道一个帧的起止比特位置,此外,也能使接收端检测出所收到的帧有无差错,如果发现差错,数据链路层能够简单的丢弃掉这个帧,以避免继续占用网络资源。
⑦ 物理层
作为 OSI 参考模型中最低的一层,物理层的作用是实现计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。该层的主要任务是确定与传输媒体的接口的一些特性(机械特性、电气特性、功能特性,过程特性)。
TCP/IP 参考模型
OSI 七层模型在提出时的出发点是基于标准化的考虑,而没有考虑到具体的市场需求,使得该模型结构复杂,部分功能冗余,因而完全实现 OSI 参考模型的系统不多。而 TCP/IP 参考模型直接面向市场需求,实现起来也比较容易,因此在一经提出便得到了广泛的应用。基于 TCP/IP 的参考模型将协议分成四个层次,如上图所示,它们分别是:网络访问层、网际互联层、传输层、和应用层。
① 应用层
TCP/IP 模型将 OSI 参考模型中的会话层、表示层和应用层的功能合并到一个应用层实现,通过不同的应用层协议为不同的应用提供服务。例如:FTP、Telnet、DNS、SMTP 等。
② 传输层
该层对应于 OSI 参考模型的传输层,为上层实体提供源端到对端主机的通信功能。传输层定义了两个主要协议:传输控制协议(TCP)和用户数据报协议(UDP)。其中面向连接的 TCP 协议保证了数据的传输可靠性,面向无连接的 UDP 协议能够实现数据包简单、快速地传输。
③ 网际互联层
网际互联层对应 OSI 参考模型的网络层,主要负责相同或不同网络中计算机之间的通信。在网际互联层, IP 协议提供的是一个不可靠、无连接的数据报传递服务。该协议实现两个基本功能:寻址和分段。根据数据报报头中的目的地址将数据传送到目的地址,在这个过程中 IP 负责选择传送路线。除了 IP 协议外,该层另外两个主要协议是互联网组管理协议(IGMP)和互联网控制报文协议(ICMP)。
④ 网络接入层
网络接入层的功能对应于 OSI 参考模型中的物理层和数据链路层,它负责监视数据在主机和网络之间的交换。事实上,TCP/IP 并未真正描述这一层的实现,而由参与互连的各网络使用自己的物理层和数据链路层协议,然后与 TCP/IP 的网络接入层进行连接,因此具体的实现方法将随着网络类型的不同而有所差异。
TCP/IP 五层参考模型
五层体系的协议结构是综合了 OSI 和 TCP/IP 优点的一种协议,包括应用层、传输层、网络层、数据链路层和物理层。其中应用层对应 OSI 的上三层,下四层和 OSI 相同。五层协议的体系结构只是为介绍网络原理而设计的,实际应用还是 TCP/IP 四层体系结构。
OSI 模型和 TCP/IP 模型异同比较
相同点
① OSI 参考模型与 TCP/IP 参考模型都采用了层次结构。
② 都能够提供面向连接和无连接两种通信服务机制。
不同点
① OSI 采用的七层模型; TCP/IP 是四层结构。
② TCP/IP 参考模型没有对网络接口层进行细分,只是一些概念性的描述; OSI 参考模型对服务和协议做了明确的区分。
③ OSI 先有模型,后有协议规范,适合于描述各种网络;TCP/IP 是先有协议集然后建立模型,不适用于非 TCP/IP 网络。
④ TCP/IP 一开始就提出面向连接和无连接服务,而 OSI 一开始只强调面向连接服务,直到很晚才开始制定无连接的服务标准。
⑤ OSI 参考模型虽然被看好,但将网络划分为七层,实现起来较困难;相反,TCP/IP 参考模型虽然有许多不尽人意的地方,但作为一种简化的分层结构还是比较成功的。
OSI 和 TCP/IP 协议之间的对应关系
| OSI 七层网络模型 | TCP/IP 四层概念模型 | 对应的网络协议 |
|---|---|---|
| 应用层(Application) | 应用层 | HTTP, TFTP, FTP, NFS, WAIS, SMTP, Telnet, DNS, SNMP |
| 表示层(Presentation) | TIFF, GIF, JPEG, PICT | |
| 会话层(Session) | RPC, SQL, NFS, NetBIOS, names, AppleTalk | |
| 传输层(Transport) | 传输层 | TCP, UDP |
| 网络层(Network) | 网络层 | IP, ICMP, ARP, RARP, RIP, IPX |
| 数据链路层(Data Link) | 数据链路层 | FDDI, Frame Relay, HDLC, SLIP, PPP |
| 物理层(Physical) | EIA/TIA-232, EIA/TIA-499, V.35, 802.3 |
ARP 属于网络层,原因是 ARP 属于 TCP/IP 协议簇。在 TCP/IP 模型中,未定义 OSI 参考模型的物理层和数据链路层这两层的功能,它定义的都是在网络层及以上的协议。
ARP 属于数据链路层,理由按照 OSI 参考模型,数据链路层封装 IP 报文时,需要通过 ARP 获取链路层目的地址,添加到报文头部,这就不属于网络层的功能了。
结论:在 TCP/IP 模式中 ARP 协议属于网络层,在 OSI 参考模型中 ARP 协议属于数据链路层。
OSI 参考模型过于理想化,先定义参考模型再定义协议。TCP/IP 模型则正好相反,通过已有的协议归纳总结出来的模型,成为实际的网络协议标准。
为什么 TCP/IP 去除了表示层和会话层
OSI 参考模型在提出时,他们的理想是非常好的,但实际上,由于会话层、表示层、应用层都是在应用程序内部实现的,最终产出的是一个应用数据包,而应用程序之间是几乎无法实现代码的抽象共享的,这也就造成 OSI 设想中的应用程序维度的分层是无法实现的,例如,我们几乎不会认为数据的压缩、加密算法算是一种协议,而会话的概念则更为抽象,难以用协议来进行描述,所以在后来的 TCP/IP 协议框架的设计中,便将表示层和会话层与应用层整合在一起,让整个过程更为清晰明了。
数据如何在各层之间传输【数据的封装过程】
在发送主机端,一个应用层报文被传送到运输层。在最简单的情况下,运输层收取到报文并附上附加信息,该首部将被接收端的运输层使用。应用层报文和运输层首部信息一道构成了运输层报文段。附加的信息可能包括:允许接收端运输层向上向适当的应用程序交付报文的信息以及差错检测位信息。该信息让接收端能够判断报文中的比特是否在途中已被改变。运输层则向网络层传递该报文段,网络层增加了如源和目的端系统地址等网络层首部信息,生成了网络层数据报。该数据报接下来被传递给链路层,在数据链路层数据包添加发送端 MAC 地址和接收端 MAC 地址后被封装成数据帧,在物理层数据帧被封装成比特流,之后通过传输介质传送到对端。
应用层
HTTP 头部包含哪些信息
HTTP 头部本质上是一个传递额外重要信息的键值对。主要分为:通用头部,请求头部,响应头部和实体头部。
- 通用头:是客户端和服务器都可以使用的头部,可以在客户端、服务器和其他应用程序之间提供一些非常有用的通用功能,如 Date 头部。
- 请求头:是请求报文特有的,它们为服务器提供了一些额外信息,比如客户端希望接收什么类型的数据,如Accept头部。
- 响应头:便于客户端提供信息,比如,客服端在与哪种类型的服务器进行交互,如 Server 头部。
- 实体头:指的是用于应对实体主体部分的头部,比如,可以用实体头部来说明实体主体部分的数据类型,如 Content-Type 头部。
通用头部
| 协议头 | 说明 | 举例 |
|---|---|---|
| Cache-Control | 用来指定当前的请求/回复中是否使用缓存机制 | Cache-Control: no-store |
| Connection | 客户端(浏览器)想要优先使用的连接类型 | Connection: keep-alive (Upgrade) |
| Date | 报文创建时间 | Date: Dec, 26 Dec 2015 17: 30: 00 GMT |
| Trailer | 会实现说明在报文主体后记录哪些首部字段,该首部字段可以使用在 HTTP/1.1 版本分块传输编码时 | Trailer: Expiress |
| Transfer-Encoding | 用来改变报文格式 | Transfer-Encoding: chunked |
| Upgrade | 要求服务器升级到一个高版本协议 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| Via | 告诉服务器,这个请求是由哪些代理发出的 | Via: 1.0 fred, 1.1 itbilu.com.com (Apache/1.1) |
| Warning | 一个一般性的警告,表示在实体内容中可能存在错误 | Warning: 199 Miscellaneous warning |
请求头部
| 协议头 | 说明 | 举例 |
|---|---|---|
| Accept | 告诉服务器自己允许哪些媒体类型 | Accept: text/plain |
| Accept-Charset | 浏览器申明可接受的字符集 | Accept-Charset: utf-8 |
| Accept-Encoding | 浏览器申明自己接收的编码方法 | Accept-Encoding: gzip, deflate |
| Accept-Language | 浏览器可接受的响应内容语言列表 | Accept-Language: en-US |
| Authorization | 用于表示 HTTP 协议中需要认证资源的认证信息 | Authorization: Basic OSdjJGRpbjpvcGVul ANIc2SdDE== |
| Expect | 表示客户端要求服务器做出特定的行为 | Expect: 100-continue |
| From | 发起此请求的用户的邮件地址 | From: user@itbilu.com |
| Host | 表示服务器的域名以及服务器所监听的端口号 | Host: www.itbilu.com:80 |
| If-XXX | 条件请求 | If-Modified-Since: Dec, 26 Dec 2015 17:30:00 GMT |
| Max-Forwards | 限制该消息可被代理及网关转发的次数 | Max-Forwards: 10 |
| Range | 表示请求某个实体的一部分,字节偏移以 0 开始 | Range: bytes=500-999 |
| Referer | 表示浏览器所访问的前一个页面,可以认为是之前访问页面的链接将浏览器带到了当前页面 | Referer: http://itbilu.com/nodejs |
| User-Agent | 浏览器的身份标识字符串 | User-Agent: Mozilla/…… |
响应头部
| 协议头 | 说明 | 举例 |
|---|---|---|
| Accept-Ranges | 字段的值表示可用于定义范围的单位 | Accept-Ranges: bytes |
| Age | 创建响应的时间 | Age:5744337 |
| ETag | 唯一标识分配的资源 | Etag:W/“585cd998-7c0f” |
| Location | 表示重定向后的 URL | Location: http://www.zcmhi.com/archives/94.html |
| Retry-After | 告知客户端多久后再发送请求 | Retry-After: 120 |
| Server | 告知客户端服务器信息 | Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) |
| Vary | 缓存控制 | Vary: Origin |
实体头部
| 协议头 | 说明 | 举例 |
|---|---|---|
| Allow | 对某网络资源的有效的请求行为,不允许则返回405 | Allow: GET, HEAD |
| Content-encoding | 返回内容的编码方式 | Content-Encoding: gzip |
| Content-Length | 返回内容的字节长度 | Content-Length: 348 |
| Content-Language | 响应体的语言 | Content-Language: en,zh |
| Content-Location | 请求资源可替代的备用的另一地址 | Content-Location: /index.htm |
| Content-MD5 | 返回资源的MD5校验值 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Range | 在整个返回体中本部分的字节位置 | Content-Range: bytes 21010-47021/47022 |
| Content-Type | 返回内容的MIME类型 | Content-Type: text/html; charset=utf-8 |
| Expires | 响应过期的日期和时间 | Expires: Thu, 01 Dec 2010 16:00:00 GMT |
| Last-Modified | 请求资源的最后修改时间 | Last-Modified: Tue, 15 Nov 2010 12:45:26 GMT |
Keep-Alive 和非 Keep-Alive 区别,对服务器性能有影响吗
- 非Keep-alive:早期HTTP1.0,浏览器发起http请求需要与服务器建立新的TCP连接,请求处理后连接立即断开,重新请求重新连接。但每一个这样的连接,客户机和服务器都要分配 TCP 的缓冲区和变量,这给服务器带来的严重的负担。
- Keep-alive:HTTP1.1默认持久连接,同一客户机可以连续请求通过相同的连接进行传送,一台服务器多个web页面也可通过单个TCP连接传送给同一个客户机。但长时间保持TCP连接会导致系统资源被无效占用。
在早期的 HTTP/1.0 中,浏览器每次发起 HTTP 请求都要与服务器创建一个新的 TCP 连接,服务器完成请求处理后立即断开 TCP 连接,服务器不跟踪每个客户也不记录过去的请求。然而创建和关闭连接的过程需要消耗资源和时间,为了减少资源消耗,缩短响应时间,就需要重用连接。在 HTTP/1.1 版本中默认使用持久连接,在此之前的 HTTP 版本的默认连接都是使用非持久连接,如果想要在旧版本的 HTTP 协议上维持持久连接,则需要指定 connection 的首部字段的值为 Keep-Alive 来告诉对方这个请求响应完成后不要关闭,下一次咱们还用这个请求继续交流,我们用一个示意图来更加生动的表示两者的区别:
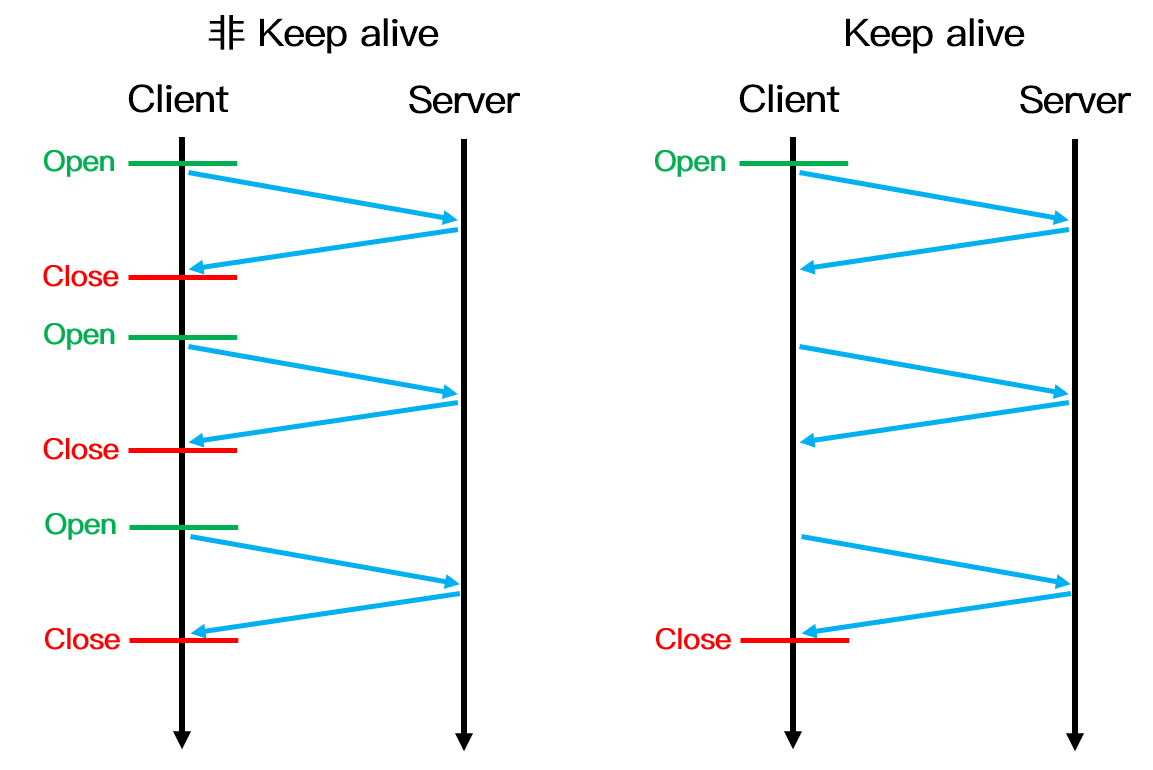
对于非 Keep-Alive 来说,必须为每一个请求的对象建立和维护一个全新的连接。对于每一个这样的连接,客户机和服务器都要分配 TCP 的缓冲区和变量,这给服务器带来的严重的负担,因为一台 Web 服务器可能同时服务于数以百计的客户机请求。在 Keep-Alive 方式下,服务器在响应后保持该 TCP 连接打开,在同一个客户机与服务器之间的后续请求和响应报文可通过相同的连接进行传送。甚至位于同一台服务器的多个 Web 页面在从该服务器发送给同一个客户机时,可以在单个持久 TCP 连接上进行。
然而,Keep-Alive 并不是没有缺点的,当长时间的保持 TCP 连接时容易导致系统资源被无效占用,若对 Keep-Alive 模式配置不当,将有可能比非 Keep-Alive 模式带来的损失更大。因此,我们需要正确地设置 keep-alive timeout 参数,当 TCP 连接在传送完最后一个 HTTP 响应,该连接会保持 keepalive_timeout 秒,之后就开始关闭这个链接。
HTTP 长连接短连接使用场景是什么
长连接:多用于操作频繁,点对点的通讯,而且客户端连接数目较少的情况。例如即时通讯、网络游戏等。
短连接:用户数目较多的Web网站的 HTTP 服务一般用短连接。例如京东,淘宝这样的大型网站一般客户端数量达到千万级甚至上亿,若采用长连接势必会使得服务端大量的资源被无效占用,所以一般使用的是短连接。
怎么知道 HTTP 的报文长度
当响应消息中存在 Content-Length 字段时,我们可以直接根据这个值来判断数据是否接收完成,例如客户端向服务器请求一个静态页面或者一张图片时,服务器能够很清楚的知道请求内容的大小,因此可以通过消息首部字段 Content- Length 来告诉客户端需要接收多少数据,但是如果服务器预先不知道请求内容的大小,例如加载动态页面的时候,就需要使用 Transfer-Encoding: chunked 的方式来代替 Content-Length。
分块传输编码(Chunked transfer encoding)是 HTTP/1.1 中引入的一种数据传输机制,其允许 HTTP 由服务器发送给客户端的数据可以分成多个部分,当数据分解成一系列数据块发送时,服务器就可以发送数据而不需要预先知道发送内容的总大小,每一个分块包含十六进制的长度值和数据,最后一个分块长度值为0,表示实体结束,客户机可以以此为标志确认数据已经接收完毕。
响应报文是发给客户端看的啊,服务器肯定知道有多少字节,但是在响应报文中有两种表现形式。
- 对于小点的文件,直接给出 content-length,也就是本次返回的数据长度
- 对于大文件,使用 Transfer-Encoding:chunked 字段,不传输数据长度,客户端只知道是分组传输,这也是订好了协议,客户端收到了会进行组装。然后给一个分组传输编码规则的图(借用罗剑锋老师的图):
HTTP 方法了解哪些
HTTP/1.0 定义了三种请求方法:GET, POST 和 HEAD 方法。
HTTP/1.1 增加了六种请求方法:OPTIONS, PUT, PATCH, DELETE, TRACE 和 CONNECT 方法。
| 方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回具体内容,通常只用于读取数据。 |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头。 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立或已有资源的更改。 |
| PUT | 替换指定的资源,没有的话就新增。 |
| DELETE | 请求服务器删除 URL 标识的资源数据。 |
| CONNECT | 将服务器作为代理,让服务器代替用户进行访问。 |
| OPTIONS | 向服务器发送该方法,会返回对指定资源所支持的 HTTP 请求方法。 |
| TRACE | 回显服务器收到的请求数据,即服务器返回自己收到的数据,主要用于测试和诊断。 |
| PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新。 |
http1.0:
- get(读取数据)
- head(获取报头)
- post(提交数据处理请求)
http1.1:(增加)
- put(增或换)
- delete(删除)
- options(返回支持方法)
- connect(server代理访问)
- trace(服务器返回接收数据)
- patch(局部更新)
GET 和 POST 的区别
- get 提交的数据会放在 URL 之后,并且请求参数会被完整的保留在浏览器的记录里,由于参数直接暴露在 URL 中,可能会存在安全问题,因此往往用于获取资源信息。而 post 参数放在请求主体中,并且参数不会被保留,相比 get 方法,post 方法更安全,主要用于修改服务器上的资源。
- get 方法产生一个 TCP 数据包,post 方法产生两个(并不是所有的浏览器中都产生两个)。
- 对于GET方式的请求,浏览器会把 http header 和 data 一并发送出去,服务端响应 200,请求成功。
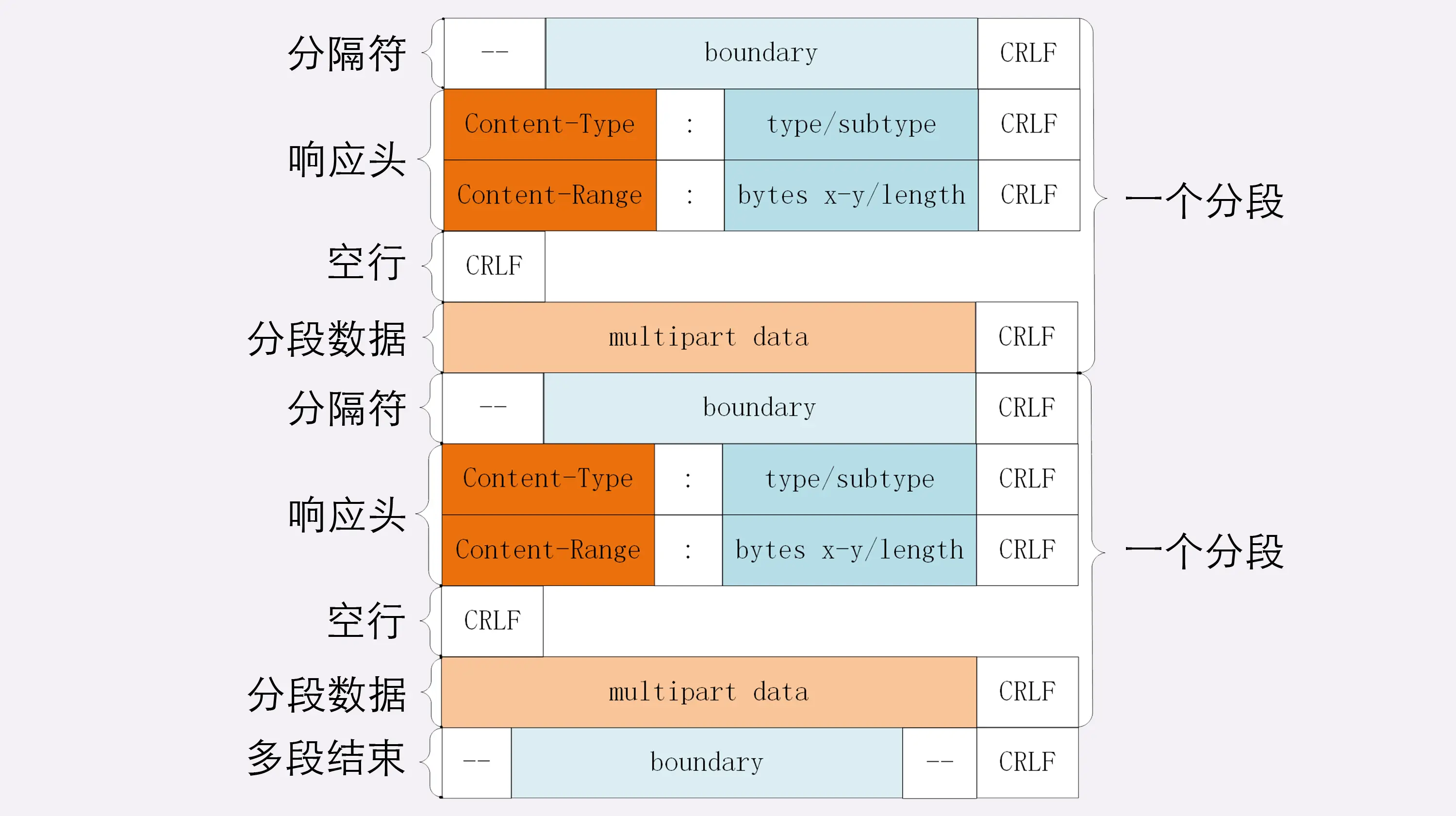
- 对于POST方式的请求,浏览器会先发送 http header 给服务端,告诉服务端等一下会有数据过来,服务端响应 100 continue,告诉浏览器我已经准备接收数据,浏览器再 post 发送一个 data 给服务端,服务端响应 200,请求成功。
- get 请求只支持 URL 编码,post 请求支持多种编码格式。
- get 只支持 ASCII 字符格式的参数,而 post 方法没有限制。
- get 提交的数据大小有限制(这里所说的限制是针对浏览器而言的),而 post 方法提交的数据没限制
- get 方式需要使用 Request.QueryString 来取得变量的值,而 post 方式通过 Request.Form 来获取。
简述一下Get和Post区别:
1) GET请求的数据是放在 HTTP 包头中的,也就是 URL 之后,通常是像下面这样定义格式的,(而Post是把提交的数据放在HTTP正文中的)。
login.action?name=hyddd&password=idontknow&verify=%E4%BD%E5%A5%BD
- 以 ?来分隔URL和数据
- 以 & 来分隔参数
- 如果数据是英文或数字,原样发送
- 如果数据是中文或其它字符,则进行BASE64编码
2)GET 提交的数据比较少,最多 1024B,因为 GET 数据是附在 URL 之后的,而 URL 则会受到不同环境的限制的,比如说 IE 对其限制为 2K+35,而 POST 可以传送更多的数据(理论上是没有限制的,但一般也会受不同的环境,如浏览器、操作系统、服务器处理能力等限制,IIS4 可支持 80KB,IIS5 可支持 100KB)。
3)Post 的安全性要比 Get 高,因为 Get 时,参数数据是明文传输的,而且使用 GET 的话,还可能造成Cross-site request forgery攻击。而 POST 数据则可以加密的,但 GET 的速度可能会快些。
所以综上几点,总结成下表:
| 操作方式 | 数据位置 | 明文密文 | 数据安全 | 长度限制 | 应用场景 |
|---|---|---|---|---|---|
| GET | HTTP包头 | 明文 | 不安全 | 长度较小 | 查询数据 |
| POST | HTTP正文 | 可明可密 | 安全 | 支持较大数据传输 | 修改数据 |
GET 的长度限制是多少
HTTP 中的 GET 方法是通过 URL 传递数据的,而 URL 本身并没有对数据的长度进行限制,真正限制 GET 长度的是浏览器,例如 IE 浏览器对 URL 的最大限制为 2000 多个字符,大概 2KB 左右,像 Chrome, FireFox 等浏览器能支持的 URL 字符数更多,其中 FireFox 中 URL 最大长度限制为 65536 个字符,Chrome 浏览器中 URL 最大长度限制为 8182 个字符。并且这个长度不是只针对数据部分,而是针对整个 URL 而言,在这之中,不同的服务器同样影响 URL 的最大长度限制。因此对于特定的浏览器,GET的长度限制不同。
由于 POST 方法请求参数在请求主体中,理论上讲,post 方法是没有大小限制的,而真正起限制作用的是服务器处理程序的处理能力。
URL构成:协议 + :// + 认证信息 + @ + 域名 or IP地址 + 端口号 + 资源路径 + ? + 查询字符串 + # + 片段标识符;
所以这里说整个URL 的长度,就是指包含上述所有组成部分在内的总长度,数据部分就是指查询字符串。
HTTP 与 HTTPs 的工作方式【建立连接的过程】
HTTP
HTTP(Hyper Text Transfer Protocol: 超文本传输协议) 是一种简单的请求 - 响应协议,被用于在 Web 浏览器和网站服务器之间传递消息。HTTP 使用 TCP(而不是 UDP)作为它的支撑运输层协议。其默认工作在 TCP 协议 80 端口,HTTP 客户机发起一个与服务器的 TCP 连接,一旦连接建立,浏览器和服务器进程就可以通过套接字接口访问 TCP。客户机从套接字接口发送 HTTP 请求报文和接收 HTTP 响应报文。类似地,服务器也是从套接字接口接收 HTTP 请求报文和发送 HTTP 响应报文。其通信内容以明文的方式发送,不通过任何方式的数据加密。当通信结束时,客户端与服务器关闭连接。
HTTPS
HTTPS,三次握手建立连接后,还需要 TSL/SSL 握手进行加密。
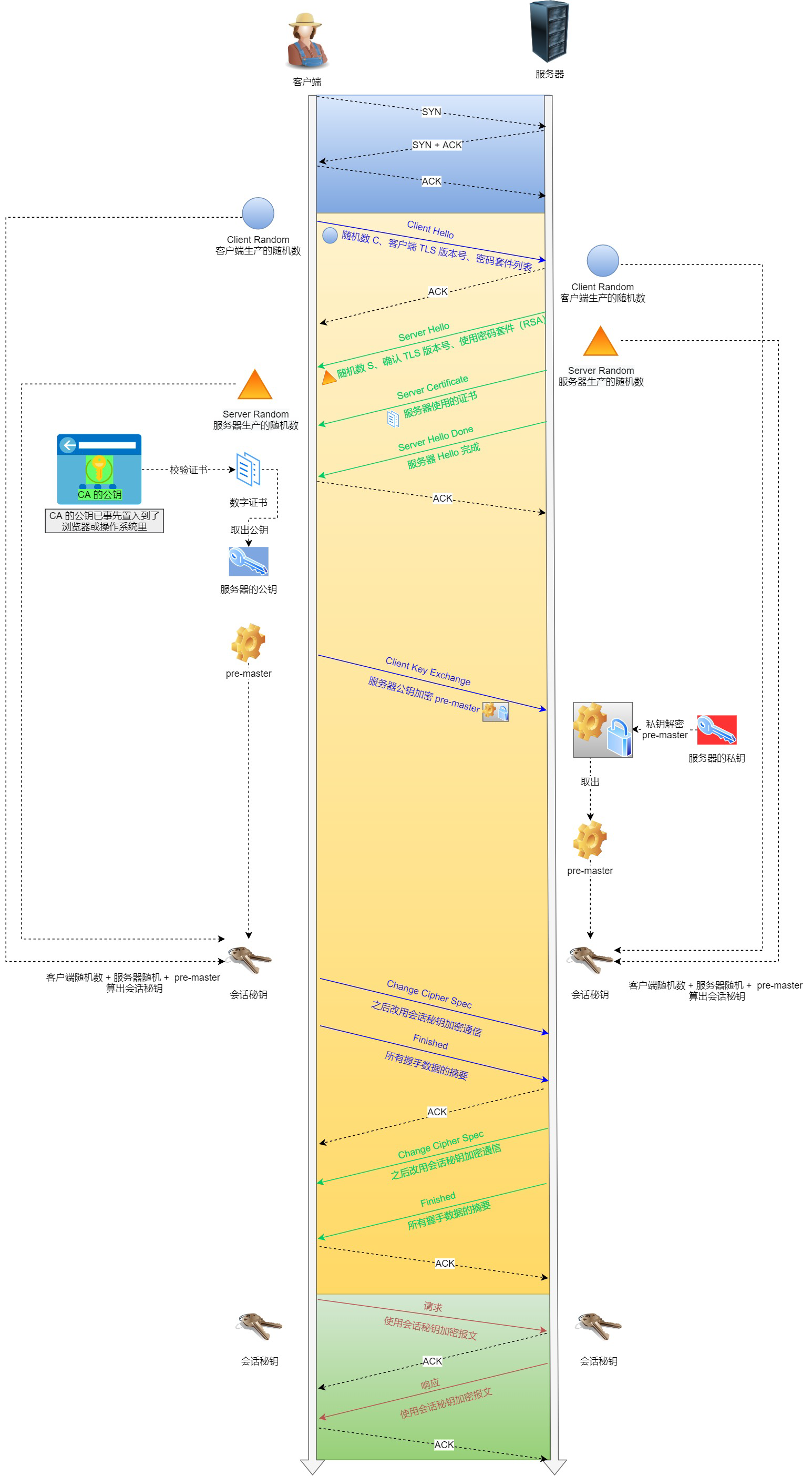


HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer)是以安全为目标的 HTTP 协议,在 HTTP 的基础上通过传输加密和身份认证的方式保证了传输过程的安全性。其工作流程如下:
① 客户端发起一个 HTTPS 请求,并连接到服务器的 443 端口,发送的信息主要包括自身所支持的算法列表和密钥长度等;
② 服务端将自身所支持的所有加密算法与客户端的算法列表进行对比并选择一种支持的加密算法,然后将它和其它密钥组件一同发送给客户端。
③ 服务器向客户端发送一个包含数字证书的报文,该数字证书中包含证书的颁发机构、过期时间、服务端的公钥等信息。
④ 最后服务端发送一个完成报文通知客户端 SSL 的第一阶段已经协商完成。
⑤ SSL 第一次协商完成后,客户端发送一个回应报文,报文中包含一个客户端生成的随机密码串,称为 pre_master_secre,并且该报文是经过证书中的公钥加密过的。
⑥ 紧接着客户端会发送一个报文提示服务端在此之后的报文是采用pre_master_secre 加密的。
⑦ 客户端向服务端发送一个 finish 报文,这次握手中包含第一次握手至今所有报文的整体校验值,最终协商是否完成取决于服务端能否成功解密。
⑧ 服务端同样发送与第 ⑥ 步中相同作用的报文,已让客户端进行确认,最后发送 finish 报文告诉客户端自己能够正确解密报文。
当服务端和客户端的 finish 报文交换完成之后,SSL 连接就算建立完成了,之后就进行和 HTTP 相同的通信过程,唯一不同的是在 HTTP 通信过程中并不是采用明文传输,而是采用对称加密的方式,其中对称密钥已经在 SSL 的建立过程中协商好了。
简单概括:
- 客户端请求服务器443端口,建立TCP连接
- 客户端发送支持的对称加密算法列表和密钥长度
- 服务器根据双方共同支持的加密算法列表选择一种返回给客户端
- 服务器返回自身的CA证书,证书包括了服务器域名和公钥
- 客户端用本地证书库的根证书校验CA证书,生成随机密码串作为后续对称加密的种子,用公钥加密发送给服务器
- 服务器用私钥解密报文,得到随机密码串,用协商好的对称加密算法和种子,加密数据报文发送给客户端
- SSL连接建立
HTTPS 和 HTTP 的区别
- 加密:HTTP 协议以明文方式发送内容,数据都是未加密的,安全性较差。HTTPS 数据传输过程是加密的,安全性较好。
- 端口:HTTP 和 HTTPS 使用的是完全不同的连接方式,用的端口也不一样,前者是 80 端口,后者是 443 端口。
- 数字证书:HTTPS 协议需要到数字认证机构(Certificate Authority, CA)申请证书,一般需要一定的费用。
- 响应速度:HTTP 页面响应比 HTTPS 快,主要因为 HTTP 使用 3 次握手建立连接,客户端和服务器需要握手 3 次,而 HTTPS 除了 TCP 的 3 次握手,还需要经历一个 SSL 协商过程。
SSL(Secure Sockets Layer 安全套接层), 及其继任者传输层安全 (Transport Layer Security,TLS) 是为网络通信提供安全及数据完整性的一种安全协议。如今被广泛使用,如网页,电子邮件,互联网传真,即时消息和语音在IP电话(VoIP)。其中网站是通过使用 TLS 来保护 WEB 浏览器与服务器之间的通信安全。
HTTPS 的加密方式
HTTPS 采用对称加密和非对称加密相结合的方式,首先使用 SSL/TLS 协议进行加密传输,为了弥补非对称加密的缺点,HTTPS 采用证书来进一步加强非对称加密的安全性,通过非对称加密,客户端和服务端协商好之后进行通信传输的对称密钥,后续的所有信息都通过该对称秘钥进行加密解密,完成整个 HTTPS 的流程。
1)公钥用于加密(私钥解密)。
这种场景是向特定的人发送秘密信息,所以消息加密后,只有私钥的拥有者才能解密。
2)公钥用于解密(私钥加密)。
这种场景是向公众发布一个签名。要求任何人都可以对加密之后的信息进行解密,所以要使用公钥来进行解密,解密之后的数据如果符合预期则证明私钥拥有者处理过了签名数据。
客户端为什么信任第三方证书
假设中间人篡改了证书原文,由于他没有 CA 机构的私钥,所以无法得到此时加密后的签名,因此无法篡改签名。客户端浏览器收到该证书后会发现原文和签名解密后的值不一致,则说明证书被中间人篡改,证书不可信,从而终止向服务器传输信息。
上述过程说明证书无法被篡改,我们考虑更严重的情况,例如中间人拿到了 CA 机构认证的证书,它想窃取网站 A 发送给客户端的信息,于是它成为中间人拦截到了 A 传给客户端的证书,然后将其替换为自己的证书。此时客户端浏览器收到的是被中间人掉包后的证书,但由于证书里包含了客户端请求的网站信息,因此客户端浏览器只需要把证书里的域名与自己请求的域名比对一下就知道证书有没有被掉包了。
HTTP 是不保存状态的协议,如何保存用户状态
如何维持用户状态?
- 基于 Session ,服务器创建并保存键值对:SessionId-Session,然后将 SessionId 下发给客户端,客户端将其存在 Cookie 中,每次请求带上这个 SessionId ,服务器就可以将状态和会话联系起来。
- 基于 Cookie ,服务器发送响应消息时在响应头中设置 Set-Cookie 字段,存储客户端的状态信息。客户端根据这个字段来创建 Cookie 并在请求时带上(每个 Cookie 都包含着客户端的状态信息),从而实现状态保持。
- 二者的区别:后者完全将会话状态存储在浏览器 Cookie 中。
- Cookie被禁用了,可以通过重写 URL 的方式将会话标识放在 URL 的参数里。
我们知道,假如某个特定的客户机在短时间内两次请求同一个对象,服务器并不会因为刚刚为该用户提供了该对象就不再做出反应,而是重新发送该对象,就像该服务器已经完全忘记不久之前所做过的是一样。因为一个 HTTP 服务器并不保存关于客户机的任何信息,所以我们说 HTTP 是一个无状态协议。
通常有两种解决方案:
① 基于 Session 实现的会话保持
在客户端第一次向服务器发送 HTTP 请求后,服务器会创建一个 Session 对象并将客户端的身份信息以键值对的形式存储下来,然后分配一个会话标识(SessionId)给客户端,这个会话标识一般保存在客户端 Cookie 中,之后每次该浏览器发送 HTTP 请求都会带上 Cookie 中的 SessionId 到服务器,服务器根据会话标识就可以将之前的状态信息与会话联系起来,从而实现会话保持。
优点:安全性高,因为状态信息保存在服务器端。
缺点:由于大型网站往往采用的是分布式服务器,浏览器发送的 HTTP 请求一般要先通过负载均衡器才能到达具体的后台服务器,倘若同一个浏览器两次 HTTP 请求分别落在不同的服务器上时,基于 Session 的方法就不能实现会话保持了。
【解决方法:采用中间件,例如 Redis,我们通过将 Session 的信息存储在 Redis 中,使得每个服务器都可以访问到之前的状态信息】
② 基于 Cookie 实现的会话保持
当服务器发送响应消息时,在 HTTP 响应头中设置 Set-Cookie 字段,用来存储客户端的状态信息。客户端解析出 HTTP 响应头中的字段信息,并根据其生命周期创建不同的 Cookie,这样一来每次浏览器发送 HTTP 请求的时候都会带上 Cookie 字段,从而实现状态保持。基于 Cookie 的会话保持与基于 Session 实现的会话保持最主要的区别是前者完全将会话状态信息存储在浏览器 Cookie 中。
优点:服务器不用保存状态信息, 减轻服务器存储压力,同时便于服务端做水平拓展。
缺点:该方式不够安全,因为状态信息存储在客户端,这意味着不能在会话中保存机密数据。除此之外,浏览器每次发起 HTTP 请求时都需要发送额外的 Cookie 到服务器端,会占用更多带宽。
拓展:Cookie被禁用了怎么办?
若遇到 Cookie 被禁用的情况,则可以通过重写 URL 的方式将会话标识放在 URL 的参数里,也可以实现会话保持。
状态码
HTTP 状态码由三个十进制数字组成,第一个数字定义了状态码的类型,后两个并没有起到分类的作用。HTTP 状态码共有 5 种类型:
| 分类 | 分类描述 | 分类描述 |
|---|---|---|
| 1XX | 指示信息 | 表示请求正在处理 |
| 2XX | 成功 | 表示请求已被成功处理完毕 |
| 3XX | 重定向 | 要完成的请求需要进行附加操作 |
| 4XX | 客户端错误 | 请求有语法错误或者请求无法实现,服务器无法处理请求 |
| 5XX | 服务器端错误 | 服务器处理请求出现错误 |
相应的 HTTP 状态码列表:
| 状态码 | 英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端继续处理请求 |
| 101 | Switching Protocol | 切换协议。服务器根据客户端的请求切换到更高级的协议 |
| 200 | OK | 请求成功。请求所希望的响应头或数据体将随此响应返回 |
| 201 | Created | 请求以实现。并且有一个新的资源已经依据需求而建立 |
| 202 | Accepted | 请求已接受。已经接受请求,但还未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的 meta 信息不在原始的服务器中,而是一个副本。 |
| 204 | No Content | 无内容。服务器成功处理了请求,但不需要返回任何实体内容 |
| 205 | Reset Content | 重置内容。与 204 类似,不同点是返回此状态码的响应要求请求者重置文档视图 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分 GET 请求 |
| 300 | Multiple Choices | 多种选择。被请求的资源有一系列可供选择的回馈信息,用户或浏览器能够自行选择一个首选地址进行重定向 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久地移动到新 URI,返回信息会包含新的 URI,浏览器会自动定向到新 URI |
| 302 | Found | 临时移动。与 301 类似。但资源只是临时被移动,客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。如果客户端发送了一个带条件的 GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个状态码 |
| 305 | Use Proxy | 使用代理。被请求的资源必须通过指定的代理才能被访问 |
| 306 | Unused | 在最新版的规范中,306状态码已经不再被使用 |
| 307 | Temporary Redirect | 临时重定向。请求的资源现在临时从不同的URI 响应请求,与302类似 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解;请求的参数有误 |
| 401 | Unauthorized | 当前请求需要用户验证 |
| 402 | Payment Required | 该状态码是为了将来可能的需求而预留的 |
| 403 | Forbidden | 服务器已经理解请求,但是拒绝执行它 |
| 404 | Not Found | 请求失败,请求所希望得到的资源未被在服务器上发现 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体 |
| 407 | Proxy Authentication Required | 与401响应类似,只不过客户端必须在代理服务器上进行身份验证 |
| 408 | Request Time-out | 请求超时。服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 由于和被请求的资源的当前状态之间存在冲突,请求无法完成 |
| 410 | Gone | 被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址 |
| 411 | Length Required | 服务器拒绝在没有定义 Content-Length 头的情况下接受请求 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 服务器拒绝处理当前请求,因为该请求提交的实体数据大小超过了服务器愿意或者能够处理的范围 |
| 414 | Request-URI Too Large | 请求的 URI 长度超过了服务器能够解释的长度,因此服务器拒绝对该请求提供服务 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server | 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理 |
| 501 | Not Implemented | 服务器不支持当前请求所需要的某个功能 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到无效的响应 |
| 503 | Service Unavailable | 由于临时的服务器维护或者过载,服务器当前无法处理请求,一段时间后可能恢复正常 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持,或者拒绝支持在请求中使用的 HTTP 版本 |
① 状态码 301 和 302 的区别?
301:永久移动。请求的资源已被永久的移动到新的URI,旧的地址已经被永久的删除了。返回信息会包括新的URI,浏览器会自动定向到新的URI。今后新的请求都应使用新的URI代替。
302:临时移动。与301类似,客户端拿到服务端的响应消息后会跳转到一个新的 URL 地址。但资源只是临时被移动,旧的地址还在,客户端应继续使用原有URI。
② HTTP 异常状态码知道哪些?
200 请求成功
204 请求成功但无内容返回
206 范围请求成功
301 永久重定向; 30(2|3|7) 临时重定向,语义和实现有略微区别;
304 带 if-modified-since 请求首部的条件请求,条件没有满足
400 语法错误(前端挨打)
401 需要认证信息
403 拒绝访问
404 找不到资源
412 除if-modified-since 以外的条件请求,条件未满足
500 服务器错误(后端挨打)
503 服务器宕机了(DevOps or IT 挨打)
HTTP/1.1 和 HTTP/1.0 的区别
长短连接(keep-alive、基于tcp、应用场景);缓存策略(更加灵活、增加);节约带宽(range头域请求部分资源);错误消息管理(增加24);host请求头(ip、虚拟主机);
-
长连接:1.0 默认浏览器和服务器之间是短连接,服务器发送完之后会直接关闭 TCP 连接,如果想多个 HTTP 请求复用TCP连接,需要在头部里增加 Connection:Keep-Alive ; 1.1的时候默认使用持久连接,减少了资源消耗
-
缓存处理:1.1 请求头中增加了一些和缓存相关的字段,比如 If-Match,可以更加灵活地控制缓存策略
-
HTTP缓存
访问一个网站的时候,浏览器会向服务器请求很多资源,比如 css、js 这些静态文件,如果每次请求都要让服务器发送所有资源,请求多了会对服务器造成很大的压力
HTTP为了解决这个问题,就引入了缓存,缓存有两种策略:
-
强缓存:每次请求资源的时候会先去缓存里找,如果有就直接用,没有才去向服务器请求资源
-
对比缓存:每次请求资源的时候先发个消息和服务器确认一下,如果服务器返回304,说明缓存可以用,浏览器就会去缓存里寻找资源
-
-
-
节约带宽:1.0 默认把资源相关的整个对象都发给客户端,但是可能客户端不需要所有的信息,这就浪费了带宽资源;1.1 的请求头引入了 Range 头域,可以只请求部分资源,比如断点下载的时候就可以用 Range
-
错误通知的管理:1.1增加了一些错误状态响应码(24个),比如 410 表示请求的资源已经被永久删除
-
Host 请求头:1.0的时候每台服务器都绑定唯一的IP地址,后面出现了虚拟主机,一个物理服务器可以有多个虚拟主机,一起共享同一个IP地址,所以为了区分不同虚拟主机,1.1 添加了 host 请求头存放主机名
HTTP/1.X 和 HTTP/2.0 的区别

-
二进制传送:之前版本 数据都是用文本传输,因为文本有多种格式,所以不能很好地适应所有场景; 2.0传送的是二进制,相当于统一了格式
-
多路复用:1.1虽然默认复用TCP连接,但是每个请求是串行执行的,如果前面的请求超时,后面的请求只能等着(也就是线头阻塞); 2.0的时候每个请求有自己的ID,多个请求可以在同一个TCP连接上并行执行,不会互相影响
-
header压缩:每次进行HTTP请求响应的时候,头部里很多的字段都是重复的,在2.0中,将字段记录到一张表中,头部只需要存放字段对应的编号就行,用的时候只需要拿着编号去表里查找就行,减少了传输的数据量
-
服务端推送:服务器会在客户端没发起请求的时候主动推送一些需要的资源,比如客户端请求一个html文件,服务器发送完之后会把和这个html页面相关的静态文件也发送给客户端,当客户端准备向服务器请求静态文件的时候,就可以直接从缓存中获取,就不需要再发起请求了
HTTP/3
HTTP/2 存在的问题
我们知道,传统 Web 平台的数据传输都基于 TCP 协议,而 TCP 协议在创建连接之前不可避免的需要三次握手,如果需要提高数据交互的安全性,即增加传输层安全协议(TLS),还会增加更多的握手次数。 HTTP 从 1.0 到 2.0,其传输层都是基于 TCP 协议的。即使是带来巨大性能提升的 HTTP/2,也无法完全解决 TCP 协议存在的固有问题(慢启动,拥塞窗口尺寸的设置等)。此外,HTTP/2 多路复用只是减少了连接数,其队头的拥塞问题并没有完全解决,倘若 TCP 丢包率过大,则 HTTP/2 的表现将不如 HTTP/1.1。
QUIC 协议
QUIC(Quick UDP Internet Connections),直译为快速 UDP 网络连接,是谷歌制定的一种基于 UDP 的低延迟传输协议。其主要目的是解决采用传输层 TCP 协议存在的问题,同时满足传输层和应用层对多连接、低延迟等的需求。该协议融合了 TCP, TLS, HTTP/2 等协议的特性,并基于 UDP传输。该协议带来的主要提升有:
-
低延迟连接。当客户端第一次连接服务器时,QUIC 只需要 1 RTT(Round-Trid Time)延迟就可以建立安全可靠的连接(采用 TLS 1.3 版本),相比于 TCP + TLS 的 3 次 RTT 要更加快捷。之后,客户端可以在本地缓存加密的认证信息,当再次与服务器建立连接时可以实现 0 RTT 的连接建立延迟。
-
QUIC 复用了 HTTP/2 协议的多路复用功能,由于 QUIC 基于 UDP,所以也避免了 HTTP/2存在的队头阻塞问题。
-
基于 UDP 协议的 QUIC 运行在用户域而不是系统内核,这使得 QUIC 协议可以快速的更新和部署,从而很好地解决了 TPC 协议部署及更新的困难。
-
QUIC 的报文是经过加密和认证的,除了少量的报文,其它所有的 QUIC 报文头部都经过了认证,报文主体经过了加密。只要有攻击者篡改 QUIC 报文,接收端都能及时发现。
-
具有向前纠错机制,每个数据包携带了除了本身内容外的部分其他数据包的内容,使得在出现少量丢包的情况下,尽量地减少其它包的重传次数,其通过牺牲单个包所携带的有效数据大小换来更少的重传次数,这在丢包数量较小的场景下能够带来一定程度的性能提升。
HTTP/3
HTTP/3 是在 QUIC 基础上发展起来的,其底层使用 UDP 进行数据传输,上层仍然使用 HTTP/2。在 UDP 与 HTTP/2 之间存在一个 QUIC 层,其中 TLS 加密过程在该层进行处理。HTTP/3 主要有以下几个特点:
① 使用 UDP 作为传输层进行通信;
② 在 UDP 之上的 QUIC 协议保证了 HTTP/3 的安全性。QUIC 在建立连接的过程中就完成了 TLS 加密握手;
③ 建立连接快,正常只需要 1 RTT 即可建立连接。如果有缓存之前的会话信息,则直接验证和建立连接,此过程 0 RTT。建立连接时,也可以带有少量业务数据;
④ 不和具体底层连接绑定,QUIC 为每个连接的两端分别分配了一个唯一 ID,上层连接只认这对逻辑 ID。网络切换或者断连时,只需要继续发送数据包即可完成连接的建立;
⑤ 使用 QPACK 进行头部压缩,因为在 HTTP/2 中的 HPACK 要求传输过程有序,这会导致队头阻塞,而 QPACK 不存在这个问题。
最后我们使用一张图来清晰的表示出 HTTP 协议的发展变化:
quic为啥快🤔
- tcp的慢
- 三次握手
- 防止拥塞慢启动
- 丢包导致的队头阻塞
- quic 为啥快❗️
- 减少往返次数RTT, 缩短连接建立时间: 缓存对方的信息
- 连接多路复用,且采用独立数据流避免丢包阻塞
- 使用前行纠错恢复丢失的包,减少超时重传
- 连接保存连接标志符,网络迁移连接快
DNS 为什么用 UDP
更正确的答案是 DNS 既使用 TCP 又使用 UDP。
当进行区域传送(主域名服务器向辅助域名服务器传送变化的那部分数据)时会使用 TCP,因为数据同步传送的数据量比一个请求和应答的数据量要多,而 TCP 允许的报文长度更长,因此为了保证数据的正确性,会使用基于可靠连接的 TCP。
当客户端向 DNS 服务器查询域名 ( 域名解析) 的时候,一般返回的内容不会超过 UDP 报文的最大长度,即 512 字节。用 UDP 传输时,不需要经过 TCP 三次握手的过程,从而大大提高了响应速度,但这要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。
怎么实现 DNS 劫持
DNS 劫持即域名劫持,是通过将原域名对应的 IP 地址进行替换从而使得用户访问到错误的网站或者使得用户无法正常访问网站的一种攻击方式。域名劫持往往只能在特定的网络范围内进行,范围外的 DNS 服务器能够返回正常的 IP 地址。攻击者可以冒充原域名所属机构,通过电子邮件的方式修改组织机构的域名注册信息,或者将域名转让给其它组织,并将新的域名信息保存在所指定的 DNS 服务器中,从而使得用户无法通过对原域名进行解析来访问目的网址。
具体实施步骤如下:
① 获取要劫持的域名信息:攻击者首先会访问域名查询站点查询要劫持的域名信息。
② 控制域名相应的 E-MAIL 账号:在获取到域名信息后,攻击者通过暴力破解或者专门的方法破解公司注册域名时使用的 E-mail 账号所对应的密码。更高级的攻击者甚至能够直接对 E-mail 进行信息窃取。
③ 修改注册信息:当攻击者破解了 E-MAIL 后,会利用相关的更改功能修改该域名的注册信息,包括域名拥有者信息,DNS 服务器信息等。
④ 使用 E-MAIL 收发确认函:在修改完注册信息后,攻击者在 E-mail 真正拥有者之前收到修改域名注册信息的相关确认信息,并回复确认修改文件,待网络公司恢复已成功修改信件后,攻击者便成功完成 DNS 劫持。
用户端的一些预防手段:
- 直接通过 IP 地址访问网站,避开 DNS 劫持。
- 由于域名劫持往往只能在特定的网络范围内进行,以在此范围外的域名服务器(DNS)能够返回正常的IP地址,因此一些高级用户可以通过网络设置让 DNS 指向正常的域名服务器以实现对目的网址的正常访问,例如将计算机首选 DNS 服务器的地址固定为 8.8.8.8。
socket() 套接字有哪些
套接字(Socket)是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象,网络进程通信的一端就是一个套接字,不同主机上的进程便是通过套接字发送报文来进行通信。例如 TCP 用主机的 IP 地址 + 端口号作为 TCP 连接的端点,这个端点就叫做套接字。
套接字主要有以下三种类型:
- 流套接字(SOCK_STREAM):流套接字基于 TCP 传输协议,主要用于提供面向连接、可靠的数据传输服务。由于 TCP 协议的特点,使用流套接字进行通信时能够保证数据无差错、无重复传送,并按顺序接收,通信双方不需要在程序中进行相应的处理。
- 数据报套接字(SOCK_DGRAM):和流套接字不同,数据报套接字基于 UDP 传输协议,对应于无连接的 UDP 服务应用。该服务并不能保证数据传输的可靠性,也无法保证对端能够顺序接收到数据。此外,通信两端不需建立长时间的连接关系,当 UDP 客户端发送一个数据给服务器后,其可以通过同一个套接字给另一个服务器发送数据。当用 UDP 套接字时,丢包等问题需要在程序中进行处理。
- 原始套接字(SOCK_RAW):由于流套接字和数据报套接字只能读取 TCP 和 UDP 协议的数据,当需要传送非传输层数据包(例如 Ping 命令时用的 ICMP 协议数据包)或者遇到操作系统无法处理的数据包时,此时就需要建立原始套接字来发送。
URI(统一资源标识符)和 URL(统一资源定位符)之间的区别
URI:资源是什么?
URL:资源是什么,如何获取?
URL,即统一资源定位符 (Uniform Resource Locator ),URL 其实就是我们平时上网时输入的网址,它标识一个互联网资源,并指定对其进行操作或获取该资源的方法。例如 https://leetcode-cn.com/problemset/all/ 这个 URL,标识一个特定资源并表示该资源的某种形式是可以通过 HTTP 协议从相应位置获得。
从定义即可看出,URL 是 URI 的一个子集,两者都定义了资源是什么,而 URL 还定义了如何能访问到该资源。URI 是一种语义上的抽象概念,可以是绝对的,也可以是相对的,而URL则必须提供足够的信息来定位,是绝对的。简单地说,只要能唯一标识资源的就是 URI,在 URI 的基础上给出其资源的访问方式的就是 URL。
为什么 fidder,charles 能抓到你的包【抓取数据包的过程】
- 其实就是将抓包工具视为中间人,其对于本地而言相当于服务端;而对于真正的服务端而言则相当于客户端;
- 抓包工具分别和本地以及服务器都进行TLS握手协商;
- 这就需要本地能够信任抓包工具提供的证书(也就是需要额外安装一个证书)
假如我们需要抓取客户端的数据包,需要监控客户端与服务器交互之间的网络节点,监控其中任意一个网络节点(网卡),获取所有经过网卡中的数据,对这些数据按照网络协议进行解析,这就是抓包的基本原理。而中间的网络节点不受我们控制,是基本无法实现抓包的,因此只能在客户端与服务器之间进行抓包。
① 当采用抓包工具抓取 HTTP 数据包时,过程较为简单:
- 首先抓包工具会提出代理服务,客户端需要连接该代理;
- 客户端发出 HTTP 请求时,会经过抓包工具的代理,抓包工具将请求的原文进行展示;
- 抓包工具使用该原文将请求发送给服务器;
- 服务器返回结果给抓包工具,抓包工具将返回结果进行展示;
- 抓包工具将服务器返回的结果原样返回给客户端。
这里抓包工具相当于透明人,数据经过的时候它一只手接到数据,然后另一只手把数据传出去。
② 当抓取 HTTPS 数据包时:
- 客户端连接抓包工具提供的代理服务,并安装抓包工具的根证书;
- 客户端发出 HTTPS 请求,抓包工具模拟服务器与客户端进行 TLS 握手交换密钥等流程;
- 抓包工具发送一个 HTTPS 请求给客户端请求的目标服务器,并与目标服务器进行 TLS 握手交换密钥等流程;
- 客户端使用与抓包工具协定好的密钥加密数据后发送给抓包工具;
- 抓包工具使用与客户端协定好的密钥解密数据,并将结果进行展示;
- 抓包工具将解密后的客户端数据,使用与服务器协定好的密钥进行加密后发送给目标服务器;
- 服务器解密数据后,做对应的逻辑处理,然后将返回结果使用与抓包工具协定好的密钥进行加密发送给抓包工具;
- 抓包工具将服务器返回的结果,用与服务器协定好的密钥解密,并将结果进行展示;
- 抓包工具将解密后的服务器返回数据,使用与客户端协定好的密钥进行加密后发送给客户端;
- 客户端解密数据。
这个时候抓包工具对客户端来说相当于服务器,对服务器来说相当于客户端。在这个传输过程中,客户端会以为它就是目标服务器,服务器也会以为它就是请求发起的客户端。
如果你访问一个网站很慢,怎么排查和解决
网页打开速度慢的原因有很多,这里列举出一些较常出现的问题:
① 首先最直接的方法是查看本地网络是否正常,可以通过网络测速软件例如电脑管家等对电脑进行测速,若网速正常,我们查看网络带宽是否被占用,例如当你正在下载电影时并且没有限速,是会影响你打开网页的速度的,这种情况往往是处理器内存小导致的;
② 当网速测试正常时,我们对网站服务器速度进行排查,通过 ping 命令查看链接到服务器的时间和丢包等情况,一个速度好的机房,首先丢包率不能超过 1%,其次 ping 值要小,最后是 ping 值要稳定,如最大和最小差值过大说明路由不稳定。或者我们也可以查看同台服务器上其他网站的打开速度,看是否其他网站打开也慢。
③ 如果网页打开的速度时快时慢,甚至有时候打不开,有可能是空间不稳定的原因。当确定是该问题时,就要找你的空间商解决或换空间商了,如果购买空间的话,可选择购买购买双线空间或多线空间;如果是在有的地方打开速度快,有的地方打开速度慢,那应该是网络线路的问题。电信线路用户访问放在联通服务器的网站,联通线路用户访问放在电信服务器上的网站,相对来说打开速度肯定是比较慢。
④ 从网站本身找原因。网站的问题主要包括网站程序设计、网页设计结构和网页内容三个部分。
- 网站程序设计:当访问网页中有拖慢网站打开速度的代码,会影响网页的打开速度,例如网页中的统计代码,我们最好将其放在网站的末尾。因此我们需要查看网页程序的设计结构是否合理;
- 网页设计结构:如果是 table 布局的网站,查看是否嵌套次数太多,或是一个大表格分成多个表格这样的网页布局,此时我们可以采用 div 布局并配合 css 进行优化。
- 网页内容:查看网页中是否有许多尺寸大的图片或者尺寸大的 flash 存在,我们可以通过降低图片质量,减小图片尺寸,少用大型 flash 加以解决。此外,有的网页可能过多地引用了其他网站的内容,若某些被引用的网站访问速度慢,或者一些页面已经不存在了,打开的速度也会变慢。一种直接的解决方法是去除不必要的加载项。
补充:
- 如果使用了CDN,CDN节点网络质量差也会导致打开慢
- CDN的解析IP跨网
- CDN的服务器负载高
- 源站服务器过载或出口带宽被占满
- DNS解析耗时
其他协议
FTP
- FTP(File Transfer Protocol,文件传输协议)是用于在网络上进行文件传输的一套标准协议,使用客户/服务器模式,使用 TCP 数据报,提供交互式访问,双向传输。
- TFTP(Trivial File Transfer Protocol,简单文件传输协议)一个小且易实现的文件传输协议,也使用客户/服务器方式,使用 UDP 数据报,只支持文件传输而不支持交互,没有列目录,不能对用户进行身份鉴定。
SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)是在 Internet 传输 Email 的标准,是一个相对简单的基于文本的协议。在其之上指定了一条消息的一个或多个接收者(在大多数情况下被确认是存在的),然后消息文本会被传输。可以很简单地通过 Telnet 程序来测试一个 SMTP 服务器。SMTP 使用 TCP 端口 25。
DHCP ( Dynamic Host Configuration Protocol,动态主机设置协议 ) 是一个局域网的网络协议,使用 UDP 协议工作,主要有两个用途:
- 用于内部网络或网络服务供应商自动分配 IP 地址给用户
- 用于内部网络管理员作为对所有电脑作中央管理的手段
SNMP(Simple Network Management Protocol,简单网络管理协议)构成了互联网工程工作小组(IETF,Internet Engineering Task Force)定义的 Internet 协议族的一部分。该协议能够支持网络管理系统,用以监测连接到网络上的设备是否有任何引起管理上关注的情况。
网页解析全过程【用户输入网址到显示对应页面的全过程】

① DNS 解析:当用户输入一个网址并按下回车键的时候,浏览器获得一个域名,而在实际通信过程中,我们需要的是一个 IP 地址,因此我们需要先把域名转换成相应 IP 地址。
② TCP 连接:浏览器通过 DNS 获取到 Web 服务器真正的 IP 地址后,便向 Web 服务器发起 TCP 连接请求,通过 TCP 三次握手建立好连接后,浏览器便可以将 HTTP 请求数据发送给服务器了。
③ 发送 HTTP 请求:浏览器向 Web 服务器发起一个 HTTP 请求,HTTP 协议是建立在 TCP 协议之上的应用层协议,其本质是在建立起的TCP连接中,按照HTTP协议标准发送一个索要网页的请求。在这一过程中,会涉及到负载均衡等操作。
拓展:什么是负载均衡?
负载均衡,英文名为 Load Balance,其含义是指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行,例如 FTP 服务器、Web 服务器、企业核心服务器和其他主要任务服务器等,从而协同完成工作任务。负载均衡建立在现有的网络之上,它提供了一种透明且廉价有效的方法扩展服务器和网络设备的带宽、增加吞吐量、加强网络处理能力并提高网络的灵活性和可用性。
负载均衡是分布式系统架构设计中必须考虑的因素之一,例如天猫、京东等大型用户网站中为了处理海量用户发起的请求,其往往采用分布式服务器,并通过引入反向代理等方式将用户请求均匀分发到每个服务器上,而这一过程所实现的就是负载均衡。
④ 处理请求并返回:服务器获取到客户端的 HTTP 请求后,会根据 HTTP 请求中的内容来决定如何获取相应的文件,并将文件发送给浏览器。
⑤ 浏览器渲染:浏览器根据响应开始显示页面,首先解析 HTML 文件构建 DOM 树,然后解析 CSS 文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。
⑥ 断开连接:客户端和服务器通过四次挥手终止 TCP 连接。
Web 页面请求过程
准备 DHCP、UDP、IP 和以太网
-
主机生成 DHCP 请求报文,放入UDP 报文段中,源地址0.0.0.0,目的地址255.255.255.255
-
将包含 DHCP 请求报文的 IP 数据报放入以太网帧中,目的 MA C地址 FF:FF:FF:FF:FF:FF,源 MAC 地址是主机 MAC 地址。 交换机会广播该数据帧。
-
交换机广播 DHCP 帧到所有端口,包括连接路由器的端口。
-
路由器接收到以太网帧后抽取 IP 数据报,抽取 DHCP 请求报文。
-
路由器生成 DHCP ACK 报文,包括分配的 IP 地址,DNS 服务器的地址,默认网关地址,子网掩码,包装成 UDP 数据报,放入以太网帧,包括源 MAC 地址(路由器地址)和目的 IP 地址(主机地址)。
-
交换机收到后转发到主机端口。
-
主机接收到 DHCP ACK 报文后设置自己的 IP 地址、DNS 地址、默认网关和子网掩码,之后在子网掩码以外的所有数据报都被发送到默认网关。
准备 DNS 和 ARP
当我们向浏览器键入 www.google.com 时,浏览器会生成一个TCP套接字,由套接字发送HTTP请求,为了生成套接字我们需要知道 www.google.com 的IP地址,这就涉及 DNS 协议。
-
主机生成 DNS 查询,将 DNS 报文放入 UDP 报文段中,目的地址在 7 中记录的 DNS 服务器地址。
-
封装成以太网帧发送到网关路由器,虽然我们知道网关路由器的 IP 地址,但仍然需要用 ARP 协议获取网关的 MAC 地址。
-
主机生成 ARP 查询报文,目的地址就是默认网关,MAC 地址为广播地址,交换机广播该报文。
-
网关地址接收到 ARP 查询报文,解析出目的地址就是自己的地址,因此返回一个 ARP 回答包含自己的 MAC 地址,向交换机发送,交换机转发给主机。
-
主机得到默认网关的 MAC 地址
-
现在可以使 DNS 查询报文到达 DNS 服务器,此时 DNS 数据报的 IP 目的地址是 DNS 服务器的地址,MAC 目的地址是网关路由器。
-
网关路由器接收 DNS 查询报文,根据目的 IP 地址和存储的转发表发送到合适的路由器。
-
路由器收到 IP 数据报后根据目的 IP 地址和转发表发送到 DNS 服务器。
-
DNS 服务器抽取到 DNS 查询报文,查找到 www.google.com 的记录,然后将 DNS 回答报文放入 UDP 报文段,经过路由器交换机达到主机。
-
主机终于获取到 www.google.com 的 IP 地址。
TCP 和 HTTP
- 有了 IP 地址就可以生成 TCP 套接字,向 www.google.com 发送 HTTP get 报文,在生成 TCP 套接字时需要先和服务器三次握手连接,此时主机会发送目的端口 80 的 TCP SYN 报文,MAC 地址为网关。
- 在网络中的路由器转发 TCP SYN 数据报
- 达到 www.google.com 的服务器,抽取出 TCP SYN 数据报发送到 80 端口的套接字上,回复 TCP SYN ACK 报文。
_问题:_客户端可以向服务器发送请求是因为服务器有公网IP,但是客户端没有,他是怎么接收服务器的回复的 - 主机最终会接收到 TCP SYN ACK 报文,从而进入连接状态。
- 现在已经建立 TCP 连接,主机向服务器发送 HTTP GET 报文。
- 服务器返回 HTTP 响应报文
- 主机浏览器读取 HTTP 响应报文,抽取 HTML 显示网页。
传输层
三次握手和四次挥手机制
三次握手
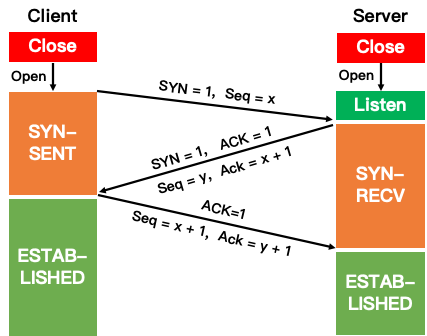
三次握手是 TCP 连接的建立过程。在握手之前,主动打开连接的客户端结束 CLOSE 阶段,被动打开的服务器也结束 CLOSE 阶段,并进入 LISTEN 阶段。随后进入三次握手阶段:
① 首先客户端向服务器发送一个 SYN 包,并等待服务器确认,其中:
- 标志位为 SYN,表示请求建立连接;
- 序号为 Seq = x(x 一般取随机数);
- 随后客户端进入 SYN-SENT 阶段。
② 服务器接收到客户端发来的 SYN 包后,对该包进行确认后结束 LISTEN 阶段,并返回一段 TCP 报文,其中:
- 标志位为 SYN 和 ACK,表示确认客户端的报文 Seq 序号有效,服务器能正常接收客户端发送的数据,并同意创建新连接;
- 序号为 Seq = y;
- 确认号为 Ack = x + 1,表示收到客户端的序号 Seq 并将其值加 1 作为自己确认号 Ack 的值,随后服务器端进入 SYN-RECV 阶段。
③ 客户端接收到发送的 SYN + ACK 包后,明确了从客户端到服务器的数据传输是正常的,从而结束 SYN-SENT 阶段。并返回最后一段报文。其中:
- 标志位为 ACK,表示确认收到服务器端同意连接的信号;
- 序号为 Seq = x + 1,表示收到服务器端的确认号 Ack,并将其值作为自己的序号值;
- 确认号为 Ack= y + 1,表示收到服务器端序号 seq,并将其值加 1 作为自己的确认号 Ack 的值。
- 随后客户端进入 ESTABLISHED。
当服务器端收到来自客户端确认收到服务器数据的报文后,得知从服务器到客户端的数据传输是正常的,从而结束 SYN-RECV 阶段,进入 ESTABLISHED 阶段,从而完成三次握手。
四次挥手:
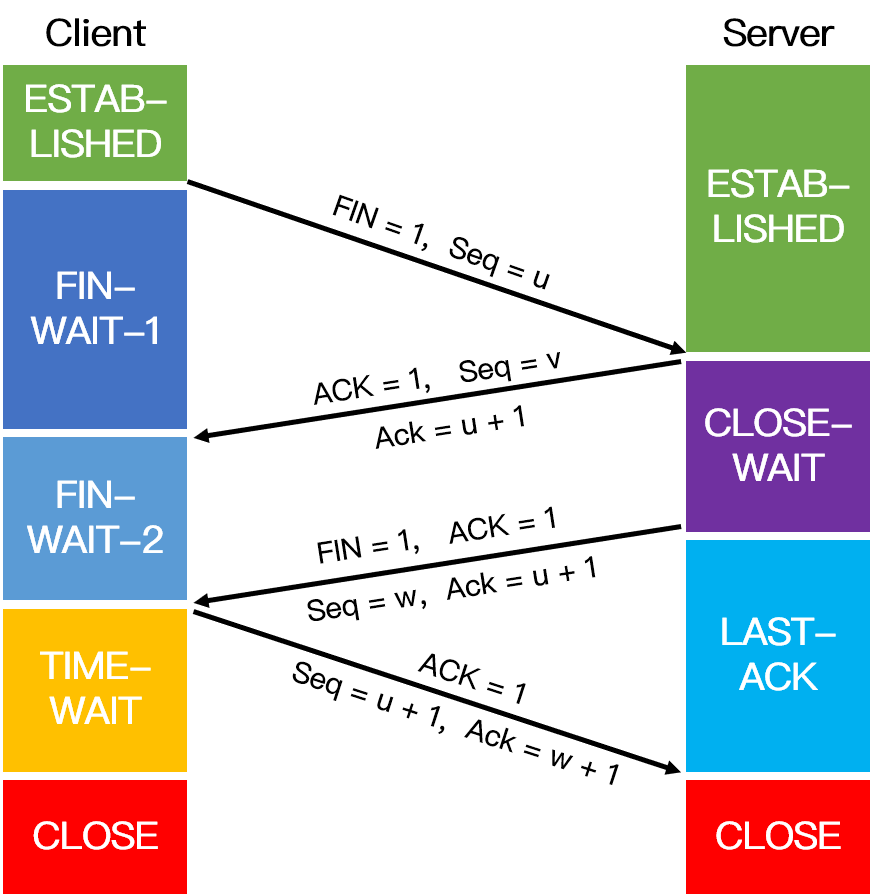
四次挥手即 TCP 连接的释放,这里假设客户端主动释放连接。在挥手之前主动释放连接的客户端结束 ESTABLISHED 阶段,随后开始四次挥手:
① 首先客户端向服务器发送一段 TCP 报文表明其想要释放 TCP 连接,其中:
- 标记位为 FIN,表示请求释放连接;
- 序号为 Seq = u;
- 随后客户端进入 FIN-WAIT-1 阶段,即半关闭阶段,并且停止向服务端发送通信数据。
② 服务器接收到客户端请求断开连接的 FIN 报文后,结束 ESTABLISHED 阶段,进入 CLOSE-WAIT 阶段并返回一段 TCP 报文,其中:
- 标记位为 ACK,表示接收到客户端释放连接的请求;
- 序号为 Seq = v;
- 确认号为 Ack = u + 1,表示是在收到客户端报文的基础上,将其序号值加 1 作为本段报文确认号 Ack 的值;
- 随后服务器开始准备释放服务器端到客户端方向上的连接。
客户端收到服务器发送过来的 TCP 报文后,确认服务器已经收到了客户端连接释放的请求,随后客户端结束 FIN-WAIT-1 阶段,进入 FIN-WAIT-2 阶段。
③ 服务器端在发出 ACK 确认报文后,服务器端会将遗留的待传数据传送给客户端,待传输完成后即经过 CLOSE-WAIT 阶段,便做好了释放服务器端到客户端的连接准备,再次向客户端发出一段 TCP 报文,其中:
- 标记位为 FIN 和 ACK,表示已经准备好释放连接了;
- 序号为 Seq = w;
- 确认号 Ack = u + 1,表示是在收到客户端报文的基础上,将其序号 Seq 的值加 1 作为本段报文确认号 Ack 的值。
随后服务器端结束 CLOSE-WAIT 阶段,进入 LAST-ACK 阶段。并且停止向客户端发送数据。
④ 客户端收到从服务器发来的 TCP 报文,确认了服务器已经做好释放连接的准备,于是结束 FIN-WAIT-2 阶段,进入 TIME-WAIT 阶段,并向服务器发送一段报文,其中:
- 标记位为 ACK,表示接收到服务器准备好释放连接的信号;
- 序号为 Seq= u + 1,表示是在已收到服务器报文的基础上,将其确认号 Ack 值作为本段序号的值;
- 确认号为 Ack= w + 1,表示是在收到了服务器报文的基础上,将其序号 Seq 的值作为本段报文确认号的值。
随后客户端开始在 TIME-WAIT 阶段等待 2 MSL。服务器端收到从客户端发出的 TCP 报文之后结束 LAST-ACK 阶段,进入 CLOSED 阶段。由此正式确认关闭服务器端到客户端方向上的连接。客户端等待完 2 MSL 之后,结束 TIME-WAIT 阶段,进入 CLOSED 阶段,由此完成「四次挥手」。
如果三次握手的时候每次握手信息对方没有收到会怎么样
- 若第一次握手服务器未接收到客户端请求建立连接的数据包时,服务器不会进行任何相应的动作,而客户端由于在一段时间内没有收到服务器发来的确认报文, 因此会等待一段时间后重新发送 SYN 同步报文,若仍然没有回应,则重复上述过程直到发送次数超过最大重传次数限制后,建立连接的系统调用会返回 -1。
- 若第二次握手客户端未接收到服务器回应的 ACK 报文时,客户端会采取第一次握手失败时的动作,这里不再重复,而服务器端此时将阻塞在 accept() 系统调用处等待 client 再次发送 ACK 报文。
- 若第三次握手服务器未接收到客户端发送过来的 ACK 报文,同样会采取类似于客户端的超时重传机制,若重传次数超过限制后仍然没有回应,则 accep() 系统调用返回 -1,服务器端连接建立失败。但此时客户端认为自己已经连接成功了,因此开始向服务器端发送数据,但是服务器端的 accept() 系统调用已返回,此时没有在监听状态。因此服务器端如果接收到来自客户端发送来的数据时会发送 RST 报文给客户端,消除客户端单方面建立连接的状态。

为什么要进行三次握手?两次握手可以吗?
三次握手的主要目的是确认自己和对方的发送和接收都是正常的,从而保证了双方能够进行可靠通信。若采用两次握手,当第二次握手后就建立连接的话,此时客户端知道服务器能够正常接收到自己发送的数据,而服务器并不知道客户端是否能够收到自己发送的数据。
我们知道网络往往是非理想状态的(存在丢包和延迟),当客户端发起创建连接的请求时,如果服务器直接创建了这个连接并返回包含 SYN、ACK 和 Seq 等内容的数据包给客户端,这个数据包因为网络传输的原因丢失了,丢失之后客户端就一直接收不到返回的数据包。由于客户端可能设置了一个超时时间,一段时间后就关闭了连接建立的请求,再重新发起新的请求,而服务器端是不知道的,如果没有第三次握手告诉服务器客户端能否收到服务器传输的数据的话,服务器端的端口就会一直开着,等到客户端因超时重新发出请求时,服务器就会重新开启一个端口连接。长此以往, 这样的端口越来越多,就会造成服务器开销的浪费。

- 避免历史连接
简单来说,三次握⼿的⾸要原因是为了防⽌旧的重复连接初始化造成混乱。
⽹络环境是错综复杂的,往往并不是如我们期望的⼀样,先发送的数据包,就先到达⽬标主机,反⽽可能会由于⽹络拥堵等乱七⼋糟的原因,会使得旧的数据包,先到达⽬标主机,那么这种情况下 TCP 三次握⼿是如何避免的呢?
客户端连续发送多次 SYN 建⽴连接的报⽂,在⽹络拥堵情况下:
- ⼀个「旧 SYN 报⽂」⽐「最新的 SYN 」 报⽂早到达了服务端;那么此时服务端就会回⼀个 SYN + ACK 报⽂给客户端;
- 客户端收到后可以根据⾃身的上下⽂,判断这是⼀个历史连接(序列号过期或超时),那么客户端就会发送
RST 报⽂给服务端,表示中⽌这⼀次连接。
如果是两次握⼿连接,就不能判断当前连接是否是历史连接,三次握⼿则可以在客户端(发送⽅)准备发送第三次报⽂时,客户端因有⾜够的上下⽂来判断当前连接是否是历史连接:
- 如果是历史连接(序列号过期或超时),则第三次握⼿发送的报⽂是 RST 报⽂,以此中⽌历史连接;
- 如果不是历史连接,则第三次发送的报⽂是 ACK 报⽂,通信双⽅就会成功建⽴连接;
所以,TCP 使⽤三次握⼿建⽴连接的最主要原因是防⽌历史连接初始化了连接。
-
同步双⽅初始序列号
TCP 协议的通信双⽅, 都必须维护⼀个「序列号」, 序列号是可靠传输的⼀个关键因素,它的作⽤:- 接收⽅可以去除重复的数据;
- 接收⽅可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中, 哪些是已经被对⽅收到的;
可⻅,序列号在 TCP 连接中占据着⾮常重要的作⽤,所以当客户端发送携带「初始序列号」的 SYN 报⽂的时 候,需要服务端回⼀个 ACK 应答报⽂,表示客户端的 SYN 报⽂已被服务端成功接收,那当服务端发送「初始序列号」给客户端的时候,依然也要得到客户端的应答回应,这样⼀来⼀回,才能确保双⽅的初始序列号能被可靠的
同步。- 四次握⼿其实也能够可靠的同步双⽅的初始化序号,但由于第⼆步和第三步可以优化成⼀步,所以就成了「三次握⼿」。
- ⽽两次握⼿只保证了⼀⽅的初始序列号能被对⽅成功接收,没办法保证双⽅的初始序列号都能被确认接收。
-
避免资源浪费
如果只有「两次握⼿」,当客户端的 SYN 请求连接在⽹络中阻塞,客户端没有接收到 ACK 报⽂,就会重新发送 SYN ,由于没有第三次握⼿,服务器不清楚客户端是否收到了⾃⼰发送的建⽴连接的 ACK 确认信号,所以每收到⼀个 SYN 就只能先主动建⽴⼀个连接,这会造成什么情况呢?
- 如果客户端的 SYN 阻塞了,重复发送多次 SYN 报⽂,那么服务器在收到请求后就会建⽴多个冗余的⽆效链不必要的资源浪费。
- 即两次握⼿会造成消息滞留情况下,服务器重复接受⽆⽤的连接请求 SYN 报⽂,⽽造成重复分配资源。
为什么客户端和服务端的初始序列号 ISN 是不相同的?
如果⼀个已经失效的连接被重⽤了,但是该旧连接的历史报⽂还残留在⽹络中,如果序列号相同,那么就⽆法分辨
出该报⽂是不是历史报⽂,如果历史报⽂被新的连接接收了,则会产⽣数据错乱。
所以,每次建⽴连接前重新初始化⼀个序列号主要是
- 为了通信双⽅能够根据序号将不属于本连接的报⽂段丢弃。
- 为了安全性,防⽌⿊客伪造的相同序列号的 TCP 报⽂被对⽅接收。
为什么要四次挥手?
简单来说就是因为TCP是全双工的,两个方向的连接需要单独关闭。
释放 TCP 连接时之所以需要四次挥手,是因为 FIN 释放连接报文和 ACK 确认接收报文是分别在两次握手中传输的。 当主动方在数据传送结束后发出连接释放的通知,由于被动方可能还有必要的数据要处理,所以会先返回 ACK 确认收到报文。当被动方也没有数据再发送的时候,则发出连接释放通知,对方确认后才完全关闭TCP连接。
举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
不要求半关闭的情况下, 可以将第二次的ACK报文和第三次的FIN报文合并成一个, 所以三次挥手也是可行的.
CLOSE-WAIT 和 TIME-WAIT 的状态和意义
CLOSE-WAIT:
- 保证服务器在关闭连接之前将待发送的数据发送完成
- 在服务器收到客户端关闭连接的请求并告诉客户端自己已经成功收到了该请求之后,服务器进入了 CLOSE-WAIT 状态,然而此时有可能服务端还有一些数据没有传输完成,因此不能立即关闭连接
TIME-WAIT :
-
防⽌旧连接的数据包
-
TIME-WAIT 发生在第四次挥手,当客户端向服务端发送 ACK 确认报文后进入该状态,若取消该状态,即客户端在收到服务端的 FIN 报文后立即关闭连接,此时服务端相应的端口并没有关闭,若客户端在相同的端口立即建立新的连接,则有可能接收到上一次连接中残留的数据包,可能会导致不可预料的异常出现。
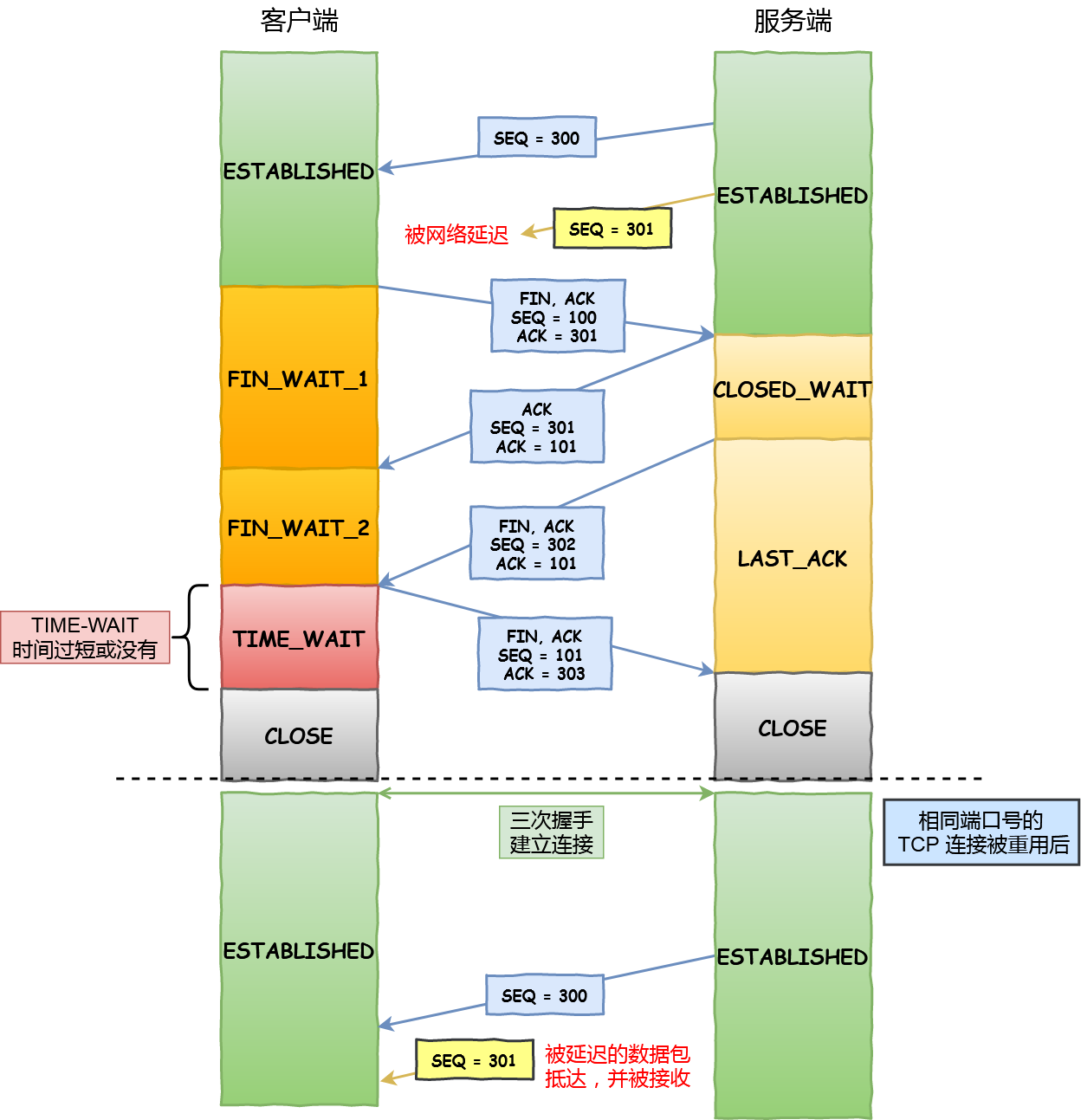
如上图⻩⾊框框服务端在关闭连接之前发送的 SEQ = 301 报⽂,被⽹络延迟了。
这时有相同端⼝的 TCP 连接被复⽤后,被延迟的 SEQ = 301 抵达了客户端,那么客户端是有可能正常接收这个过期的报⽂,这就会产⽣数据错乱等严重的问题。所以,TCP 就设计出了这么⼀个机制,经过 2MSL 这个时间,⾜以让两个⽅向上的数据包都被丢弃,使得原来连接的数据包在网络中都自然消失,再出现的数据包⼀定都是新建⽴连接所产⽣的。
-
-
保证连接正确关闭
-
TIME-WAIT 作⽤是等待⾜够的时间以确保最后的 ACK 能让被动关闭方接收,从⽽帮助其正常关闭。
假设 TIME-WAIT 没有等待时间或时间过短,断开连接会造成什么问题呢?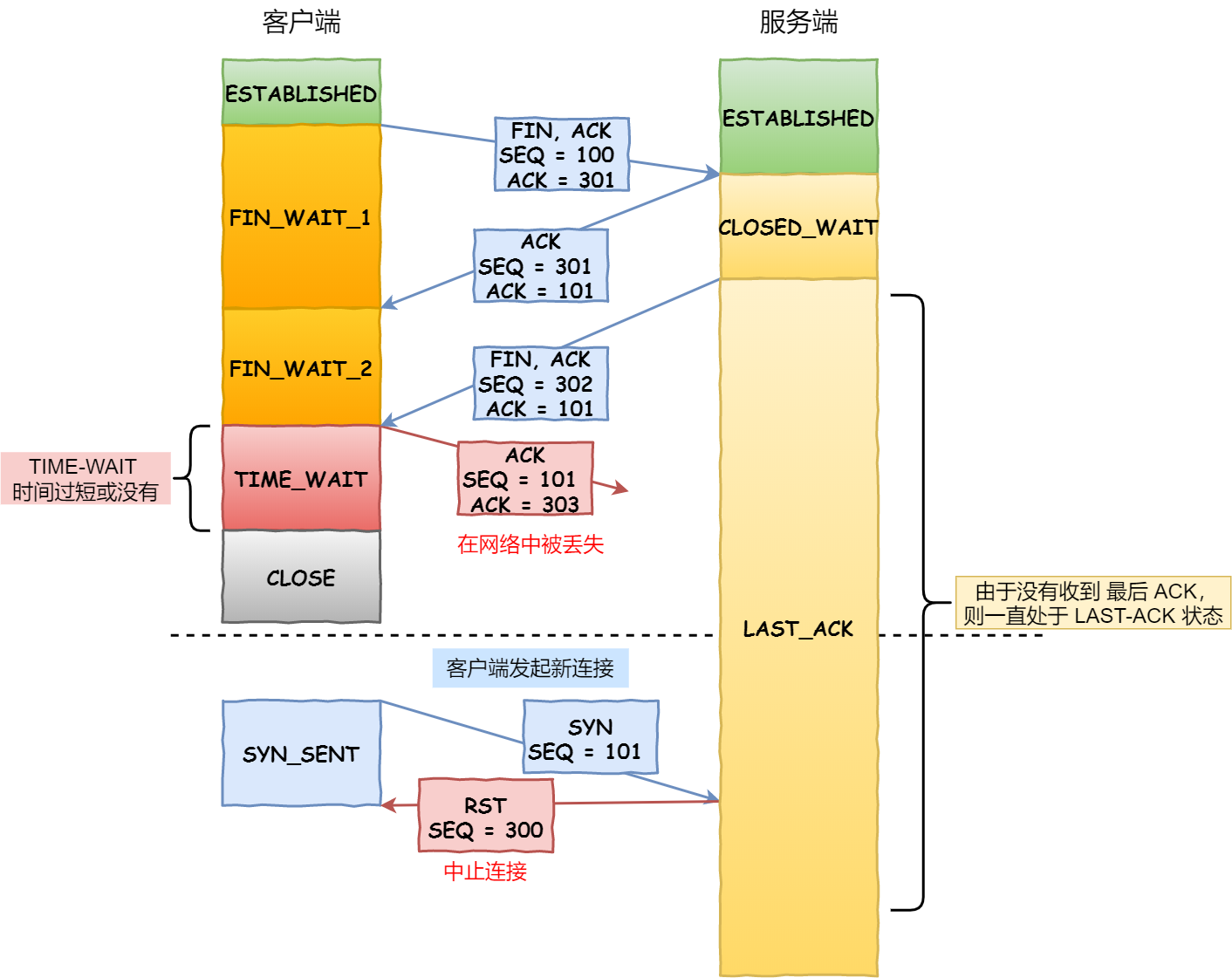
如上图红⾊框框客户端四次挥⼿的最后⼀个 ACK 报⽂如果在⽹络中被丢失了,此时如果客户端 TIME-WAIT 过短或没有,则就直接进⼊了 CLOSED 状态了,那么服务端则会⼀直处在 LASE_ACK 状态。- 由于 TCP 协议的超时重传机制,服务端将重发 FIN 报文,若客户端并没有维持 TIME-WAIT 状态而直接关闭的话,当收到服务端重新发送的 FIN 包时,客户端就会用 RST 包来响应服务端,这将会使得对方认为是有错误发生,然而其实只是正常的关闭连接过程,并没有出现异常情况。
- 当客户端发起建⽴连接的 SYN 请求报⽂后,服务端会发送 RST 报⽂给客户端,连接建⽴的过程就会被终⽌。
如果 TIME-WAIT 等待⾜够⻓的情况就会遇到两种情况:
- 服务端正常收到四次挥⼿的最后⼀个 ACK 报⽂,则服务端正常关闭连接。
- 服务端没有收到四次挥⼿的最后⼀个 ACK 报⽂时,则会重发 FIN 关闭连接报⽂并等待新的 ACK 报⽂。
所以客户端在 TIME-WAIT 状态等待 2MSL 时间后,就可以保证双⽅的连接都可以正常的关闭。
-
TIME_WAIT 状态(过多)会导致什么问题,怎么解决
如果服务器有处于 TIME-WAIT 状态的 TCP,则说明是由服务器⽅主动发起的断开请求。过多的 TIME-WAIT 状态主要的危害有两种:
- 第⼀是内存资源占⽤;
- 第⼆是对端⼝资源的占⽤,⼀个 TCP 连接⾄少消耗⼀个本地端⼝;
第⼆个危害是会造成严重的后果的,要知道,端⼝资源也是有限的,⼀般可以开启的端⼝为 32768~61000 。
如果发起连接⼀⽅的 TIME_WAIT 状态过多,占满了所有端⼝资源,则会导致⽆法创建新连接。
客户端受端⼝资源限制:
- 客户端TIME_WAIT过多,就会导致端⼝资源被占⽤,因为端⼝就65536个,被占满就会导致⽆法创建新的连接。
服务端受系统资源限制:
- 由于⼀个四元组表示 TCP 连接,理论上服务端可以建⽴很多连接。服务端确实只监听⼀个端⼝,但是会把连接扔给处理线程,所以理论上监听的端⼝可以继续监听。但是线程池处理不了那么多⼀直不断的连接了。所以当服务端出现⼤量 TIME_WAIT,系统资源被占满时,会导致处理不过来新的连接。
- 服务器维护每一个连接需要一个 socket,也就是每个连接会占用一个文件描述符,而文件描述符的使用是有上限的,如果持续高并发,会导致一些正常的连接失败。
TIME-WAIT 为什么是 2MSL
当客户端发出最后的 ACK 确认报文时,并不能确定服务器端能够收到该段报文。所以客户端在发送完 ACK 确认报文之后,会设置一个时长为 2 MSL 的计时器。MSL(Maximum Segment Lifetime),指一段 TCP 报文在传输过程中的最大生命周期。2 MSL 即是服务器端发出 FIN 报文和客户端发出的 ACK 确认报文所能保持有效的最大时长。
若服务器在 1 MSL 内没有收到客户端发出的 ACK 确认报文,再次向客户端发出 FIN 报文。如果客户端在 2 MSL 内收到了服务器再次发来的 FIN 报文,说明服务器由于一些原因并没有收到客户端发出的 ACK 确认报文。客户端将再次向服务器发出 ACK 确认报文,并重新开始 2 MSL 的计时。
若客户端在 2MSL 内没有再次收到服务器发送的 FIN 报文,则说明服务器正常接收到客户端 ACK 确认报文,客户端可以进入 CLOSE 阶段,即完成四次挥手。
所以客户端要经历 2 MSL 时长的 TIME-WAIT 阶段,为的是确认服务器能否接收到客户端发出的 ACK 确认报文。

MSL,RTT,TTL
MSL 报文最大生存时间,TTL 生存时间(跳数),RTT 客户到服务器往返所花时间
-
MSL 是 Maximum Segment Lifetime 英文的缩写,中文可以译为“ 报文最大生存时间 ”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为 TCP 报文(segment)是 IP 数据报(datagram)的数据部分。
-
而 IP 头中有一个 TTL 域,TTL 是 time to live 的缩写,中文可以译为 “ 生存时间 ”,这个生存时间是由源主机设置初始值但不是存的具体时间,而是存储了一个 IP 数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报文通知源主机。RFC 793 中规定 MSL 为 2 分钟,实际应用中常用的是 30 秒,1 分钟和 2 分钟等。
2MSL 即两倍的 MSL,TCP 的 TIME_WAIT 状态也称为 2MSL 等待状态,当 TCP 的一端发起主动关闭,在发出最后一个 ACK 包后,即第 3 次握手完成后发送了第四次握手的 ACK 包后就进入了 TIME_WAIT 状态,必须在此状态上停留两倍的 MSL 时间,等待 2MSL 时间主要目的是怕最后一个 ACK 包对方没收到,那么对方在超时后将重发第三次握手的 FIN 包,主动关闭端接到重发的 FIN 包后可以再发一个 ACK 应答包。在 TIME_WAIT 状态时两端的端口不能使用,要等到 2MSL 时间结束才可继续使用。当连接处于 2MSL 等待阶段时任何迟到的报文段都将被丢弃。不过在实际应用中可以通过设置 SO_REUSEADDR 选项达到不必等待 2MSL 时间结束再使用此端口。
TTL 与 MSL 是有关系的但不是简单的相等的关系,MSL 要大于等于 TTL 。 -
RTT 是客户到服务器往返所花时间(round-trip time,简称 RTT ),TCP 含有动态估算 RTT 的算法。TCP 还持续估算一个给定连接的 RTT,这是因为 RTT 受网络传输拥塞程序的变化而变化。
表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。
一般认为 单向时延 = 传输时延 t1 + 传播时延 t2 + 排队时延 t3- t1 是数据从进入节点到传输媒体所需要的时间,通常等于数据块长度/信道带宽
- t2 是信号在信道中需要传播一定距离而花费的时间,等于信道长度/传播速率(光纤中电磁波的传播速率约为210^5 km/s,铜缆中2.310^5 km/s)
- t3 可笼统归纳为随机噪声,由途径的每一跳设备及收发两端负荷情况及吞吐排队情况决定(包含互联网设备和传输设备时延)
有很多 TIME-WAIT 状态如何解决
- SO_REUSEADDR:服务器可以设置 SO_REUSEADDR 套接字选项来通知内核,如果端口被占用,但 TCP 连接位于 TIME_WAIT 状态时可以重用端口。如果你的服务器程序停止后想立即重启,而新的套接字依旧希望使用同一端口,此时 SO_REUSEADDR 选项就可以避免 TIME-WAIT 状态。
- 长连接:也可以采用长连接的方式减少 TCP 的连接与断开,在长连接的业务中往往不需要考虑 TIME-WAIT 状态,但其实在长连接的业务中并发量一般不会太高。
有很多 CLOSE-WAIT 怎么解决
- 首先检查是不是自己的代码问题(看是否服务端程序忘记关闭连接),如果是,则修改代码。
- 调整系统参数,包括句柄相关参数和 TCP/IP 的参数,一般一个 CLOSE_WAIT 会维持至少 2 个小时的时间,我们可以通过调整参数来缩短这个时间。
TCP 和 UDP 的区别
| 类型 | 是否面向连接 | 传输可靠性 | 传输形式 | 传输效率 | 所需资源 | 应用场景 | 首部字节 |
|---|---|---|---|---|---|---|---|
| TCP | 是 | 可靠 | 字节流 | 慢 | 多 | 文件传输、邮件传输 | 20~60 |
| UDP | 否 | 不可靠 | 数据报文段 | 快 | 少 | 即时通讯、域名转换 | 8个字节 |
TCP 协议中的定时器
TCP中有七种计时器,分别为:
-
建立连接定时器:顾名思义,该定时器是在建立 TCP 连接的时候使用的,在 TCP 三次握手的过程中,发送方发送 SYN 时,会启动一个定时器(默认为 3 秒),若 SYN 包丢失了,那么 3 秒以后会重新发送 SYN 包,直到达到重传次数。
-
重传定时器:该计时器主要用于 TCP 超时重传机制中,当 TCP 发送报文段时,就会创建特定报文的重传计时器,并可能出现两种情况:
① 若在计时器截止之前发送方收到了接收方的 ACK 报文,则撤销该计时器;
② 若计时器截止时间内并没有收到接收方的 ACK 报文,则发送方重传报文,并将计时器复位。 -
坚持计时器:我们知道 TCP 通过让接受方指明希望从发送方接收的数据字节数(窗口大小)来进行流量控制,当接收端的接收窗口满时,接收端会告诉发送端此时窗口已满,请停止发送数据。此时发送端和接收端的窗口大小均为0,直到窗口变为非0时,接收端将发送一个 确认 ACK 告诉发送端可以再次发送数据,但是该报文有可能在传输时丢失。若该 ACK 报文丢失,则双方可能会一直等待下去,为了避免这种死锁情况的发生,发送方使用一个坚持定时器来周期性地向接收方发送探测报文段,以查看接收方窗口是否变大。
-
延迟应答计时器:延迟应答也被称为捎带 ACK,这个定时器是在延迟应答的时候使用的,为了提高网络传输的效率,当服务器接收到客户端的数据后,不是立即回 ACK 给客户端,而是等一段时间,这样如果服务端有数据需要发送给客户端的话,就可以把数据和 ACK 一起发送给客户端了。
-
保活定时器:该定时器是在建立 TCP 连接时指定 SO_KEEPLIVE 时才会生效,当发送方和接收方长时间没有进行数据交互时,该定时器可以用于确定对端是否还活着。
-
FIN_WAIT_2 定时器:当主动请求关闭的一方发送 FIN 报文给接收端并且收到其对 FIN 的确认 ACK后进入 FIN_WAIT_2状态。如果这个时候因为网络突然断掉、被动关闭的一端宕机等原因,导致请求方没有收到接收方发来的 FIN,主动关闭的一方会一直等待。该定时器的作用就是为了避免这种情况的发生。当该定时器超时的时候,请求关闭方将不再等待,直接释放连接。
-
TIME_WAIT 定时器:我们知道在 TCP 四次挥手中,发送方在最后一次挥手之后会进入 TIME_WAIT 状态,不直接进入 CLOSE 状态的主要原因是被动关闭方万一在超时时间内没有收到最后一个 ACK,则会重发最后的 FIN,2 MSL(报文段最大生存时间)等待时间保证了重发的 FIN 会被主动关闭的一段收到且重新发送最后一个 ACK 。还有一个原因是在这 2 MSL 的时间段内任何迟到的报文段会被接收方丢弃,从而防止老的 TCP 连接的包在新的 TCP 连接里面出现。
TCP 是如何保证可靠性的
- 数据分块:应用数据被分割成 TCP 认为最适合发送的数据块。
- 序列号和确认应答:TCP 给发送的每一个包进行编号,在传输的过程中,每次接收方收到数据后,都会对传输方进行确认应答,即发送 ACK 报文,这个 ACK 报文当中带有对应的确认序列号,告诉发送方成功接收了哪些数据以及下一次的数据从哪里开始发。除此之外,接收方可以根据序列号对数据包进行排序,把有序数据传送给应用层,并丢弃重复的数据。
- 校验和: TCP 将保持它首部和数据部分的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到报文段的检验和有差错,TCP 将丢弃这个报文段并且不确认收到此报文段。
- 流量控制: TCP 连接的双方都有一个固定大小的缓冲空间,发送方发送的数据量不能超过接收端缓冲区的大小。当接收方来不及处理发送方的数据,会提示发送方降低发送的速率,防止产生丢包。TCP 通过滑动窗口协议来支持流量控制机制。
- 拥塞控制: 当网络某个节点发生拥塞时,减少数据的发送。
- ARQ协议: 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
- 超时重传: 当 TCP 发出一个报文段后,它启动一个定时器,等待目的端确认收到这个报文段。如果超过某个时间还没有收到确认,将重发这个报文段。
TCP是字节流、UDP是数据报
TCP 虽然是面向字节流的,但 TCP 传输数据单元却是报文段,TCP 的滑动窗口是以字节为单位的。面向字节流的含义是:虽然应用程序和TCP的交互是一次一个数据块 (大小不等),但 TCP 把应用程序交付下来的数据看成仅仅是一连串的无结构的字节流。
- TCP 都是数据报的形式,这个字节流指的是与应用程序的区别
- TCP 把应用程序当成一个无结构的字节流,然后 TCP 有一个缓冲窗口,对应用程序传输下来的数据进行处理,比如太少了,就等到多了一起传输等。
- UDP 则不管这么多,应用程序传输多少下来也是直接打包报文直接发送。
UDP 为什么是不可靠的?bind 和 connect 对于 UDP 的作用是什么
UDP 只有一个 socket 接收缓冲区,没有 socket 发送缓冲区,即只要有数据就发,不管对方是否可以正确接收。而在对方的 socket 接收缓冲区满了之后,新来的数据报无法进入到 socket 接受缓冲区,此数据报就会被丢弃,因此 UDP 不能保证数据能够到达目的地,此外,UDP 也没有流量控制和重传机制,故 UDP 的数据传输是不可靠的。
和 TCP 建立连接时采用三次握手不同,UDP 中调用 connect 只是把对端的 IP 和 端口号记录下来,并且 UDP 可以多次调用 connect 来指定一个新的 IP 和端口号,或者断开旧的 IP 和端口号(通过设置 connect 函数的第二个参数)。和普通的 UDP 相比,调用 connect 的 UDP 会提升效率,并且在高并发服务中会增加系统稳定性。
当 UDP 的发送端调用 bind 函数时,就会将这个套接字指定一个端口,若不调用 bind 函数,系统内核会随机分配一个端口给该套接字。当手动绑定时,能够避免内核来执行这一操作,从而在一定程度上提高性能。
TCP 超时重传的原理
发送方在发送一次数据后就开启一个定时器,在一定时间内如果没有得到发送数据包的 ACK 报文,那么就重新发送数据,在达到一定次数还没有成功的话就放弃重传并发送一个复位信号。其中超时时间的计算是超时的核心,而定时时间的确定往往需要进行适当的权衡,因为当定时时间过长会造成网络利用率不高,定时太短会造成多次重传,使得网络阻塞。在 TCP 连接过程中,会参考当前的网络状况从而找到一个合适的超时时间。
TCP 的停止等待协议是什么
一句话, 在已发送但未确认的报文被确认之前, 发送方的滑动窗口将不会滑动。
停止等待协议是为了实现 TCP 可靠传输而提出的一种相对简单的协议,该协议指的是发送方每发完一组数据后,直到收到接收方的确认信号才继续发送下一组数据。我们通过四种情形来帮助理解停等协议是如何实现可靠传输的:
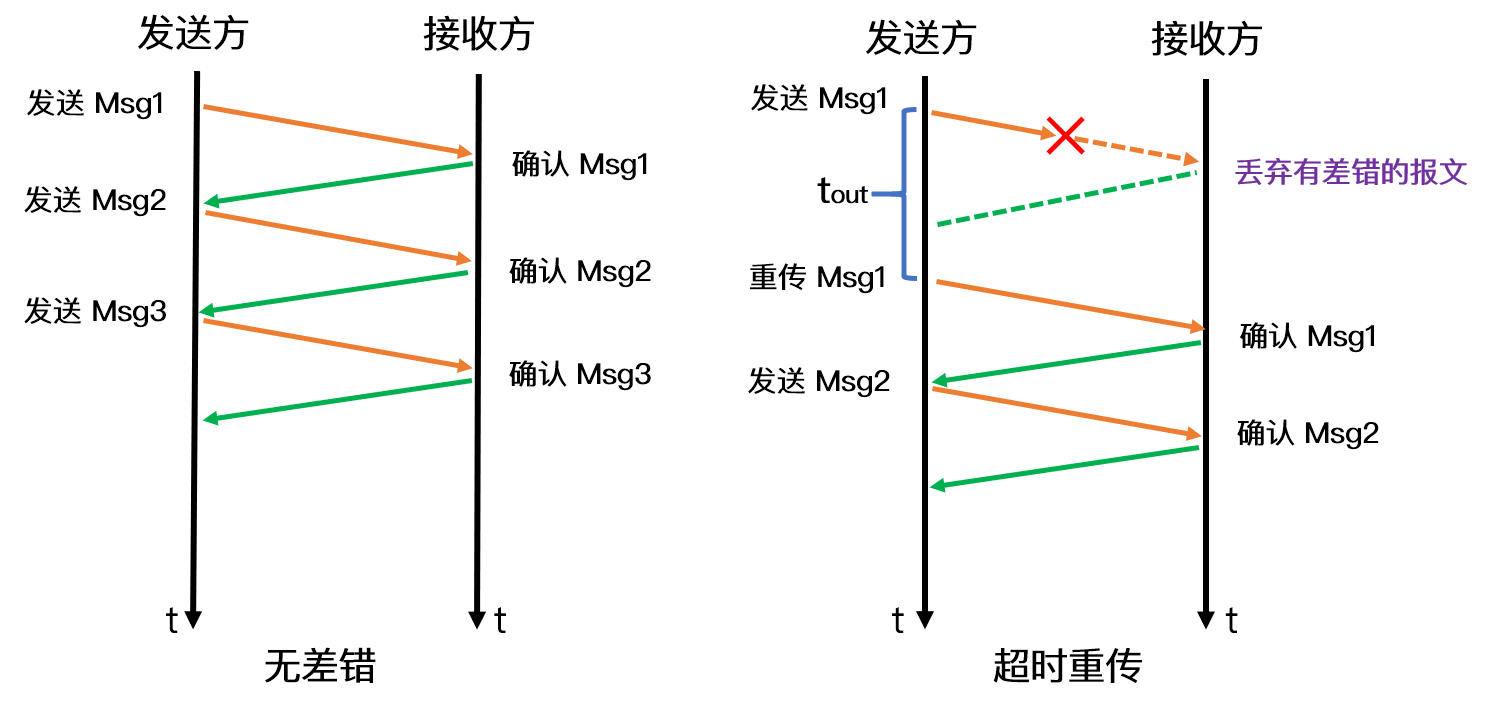
① 无差错传输
如上述左图所示,A 发送分组 Msg 1,发完就暂停发送,直到收到接收方确认收到 Msg 1 的报文后,继续发送 Msg 2,以此类推,该情形是通信中的一种理想状态。
② 出现差错
如上述右图所示,发送方发送的报文出现差错导致接收方不能正确接收数据,出现差错的情况主要分为两种:
- 发送方发送的 Msg 1 在中途丢失了,接收方完全没收到数据。
- 接收方收到 Msg 1 后检测出现了差错,直接丢弃 Msg 1。
上面两种情形,接收方都不会回任何消息给发送方,此时就会触发超时传输机制,即发送方在等待一段时间后仍然没有收到接收方的确认,就认为刚才发送的数据丢失了,因此重传前面发送过的数据。
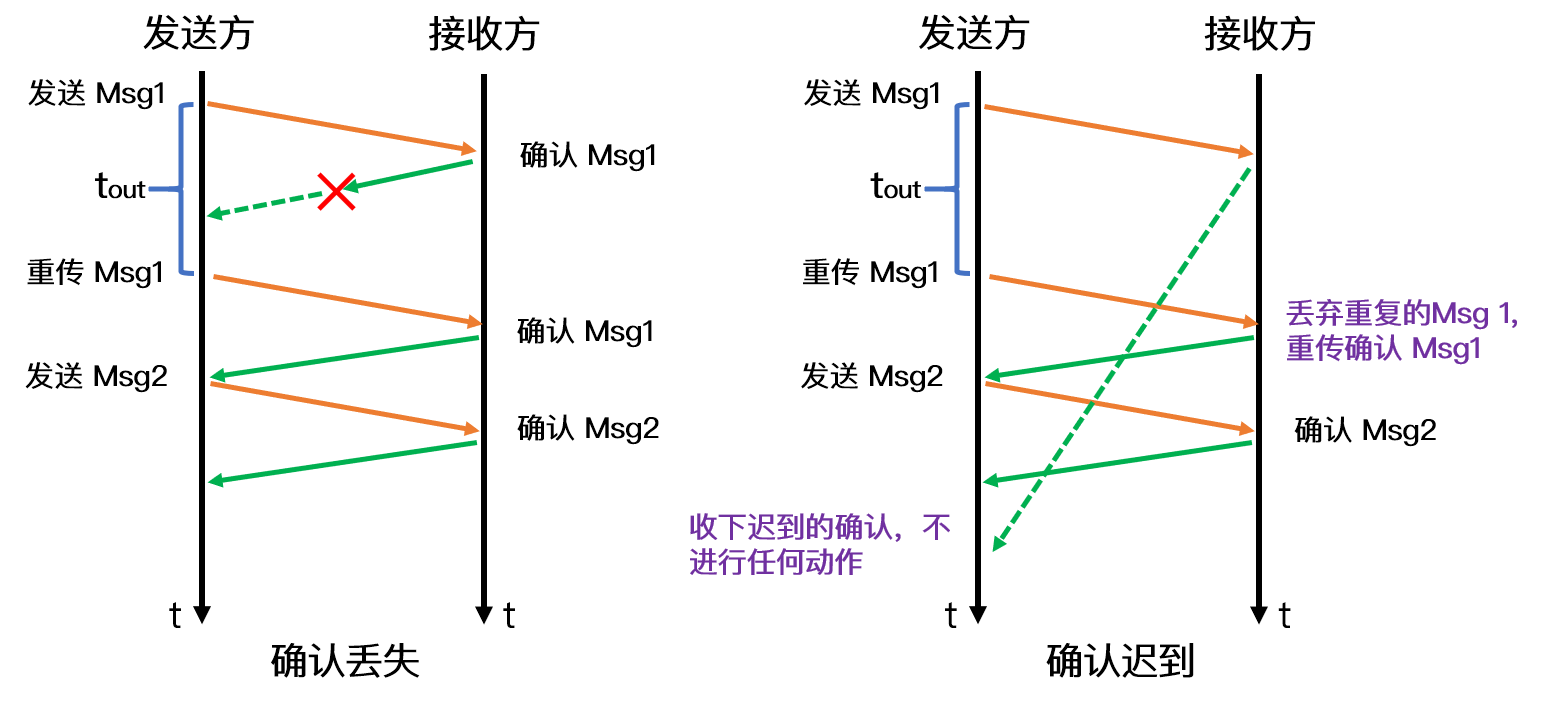
③ 确认丢失
当接收方回应的 Msg 1 确认报文在传输过程中丢失,发送方无法接收到确认报文。于是发送方等待一段时间后重传 Msg 1,接收方将收到重复的 Msg1 数据包,此时接收方会丢弃掉这个重复报文并向发送方再次发送 Msg1 的确认报文。
④ 确认迟到
当接收方回应的 Msg 1 确认报文由于网络各种原因导致发送方没有及时收到,此时发送方在超时重传机制的作用下再次发送了 Msg 数据包,接收方此时进行和确认丢失情形下相同的动作(丢弃重复的数据包并再次发送 Msg 1 确认报文)。发送方此时收到了接收方的确认数据包,于是继续进行数据发送。过了一段时间后,发送方收到了迟到的 Msg 1 确认包会直接丢弃。
上述四种情形即停止等待协议中所出现的所有可能情况。
TCP 最大连接数限制
- Client 最大 TCP 连接数
client 在每次发起 TCP 连接请求时,如果自己并不指定端口的话,系统会随机选择一个本地端口(local port),该端口是独占的,不能和其他 TCP 连接共享。TCP 端口的数据类型是 unsigned short,因此本地端口个数最大只有 65536,除了端口 0不能使用外,其他端口在空闲时都可以正常使用,这样可用端口最多有 65535 个。
- Server 最大 TCP 连接数
server 通常固定在某个本地端口上监听,等待 client 的连接请求。不考虑地址重用(Unix 的 SO_REUSEADDR 选项)的情况下,即使 server 端有多个 IP,本地监听端口也是独占的,因此 server 端 TCP 连接 4 元组中只有客户端的 IP 地址和端口号是可变的,因此最大 TCP 连接为 客户端 IP 数 × 客户端 port 数,对 IPV4,在不考虑 IP 地址分类的情况下,最大 TCP 连接数约为 2 的 32 次方(IP 数)× 2 的 16 次方(port 数),也就是 server 端单机最大 TCP 连接数约为 2 的 48 次方。
然而上面给出的是只是理论上的单机最大连接数,在实际环境中,受到明文规定(一些 IP 地址和端口具有特殊含义,没有对外开放)、机器资源、操作系统等的限制,特别是 sever 端,其最大并发 TCP 连接数远不能达到理论上限。对 server 端,通过增加内存、修改最大文件描述符个数等参数,单机最大并发 TCP 连接数超过 10 万 是没问题的。
TCP 流量控制与拥塞控制
- 流量控制
所谓流量控制就是让发送方的发送速率不要太快,让接收方来得及接收。如果接收方来不及接收发送方发送的数据,那么就会有分组丢失。在 TCP 中利用可变长的滑动窗口机制可以很方便的在 TCP 连接上实现对发送方的流量控制。主要的方式是接收方返回的 ACK 中会包含自己的接收窗口大小,以控制发送方此次发送的数据量大小(发送窗口大小)。
- 拥塞控制
在实际的网络通信系统中,除了发送方和接收方外,还有路由器,交换机等复杂的网络传输线路,此时就需要拥塞控制。拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况。常用的解决方法有:慢开始和拥塞避免、快重传和快恢复。
- 拥塞控制和流量控制的区别
拥塞控制往往是一种全局的,防止过多的数据注入到网络之中,而 TCP 连接的端点只要不能收到对方的确认信息,猜想在网络中发生了拥塞,但并不知道发生在何处,因此,流量控制往往指点对点通信量的控制,是端到端的问题。
如果接收方滑动窗口满了,发送方会怎么做
基于 TCP 流量控制中的滑动窗口协议,我们知道接收方返回给发送方的 ACK 包中会包含自己的接收窗口大小。
- 若接收窗口已满,此时接收方返回给发送方的接收窗口大小为 0,此时发送方会等待接收方发送的窗口大小直到变为非 0 为止。
- 然而,接收方回应的 ACK 包是存在丢失的可能的,为了防止双方一直等待而出现死锁情况,此时就需要坚持计时器来辅助发送方周期性地向接收方查询,以便发现窗口是否变大,当发现窗口大小变为非零时,发送方便继续发送数据。
什么是拥塞窗⼝?和发送窗⼝有什么关系呢?
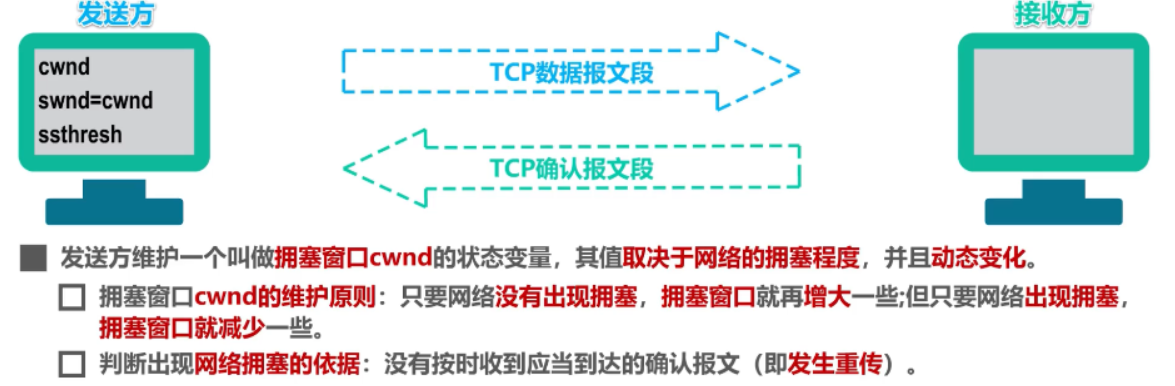
发送窗⼝ swnd 和接收窗⼝ rwnd 是约等于的关系,那么由于加⼊了拥塞窗⼝的概念后,此时发送窗⼝的值是 swnd = min(cwnd, rwnd),也就是拥塞窗⼝和接收窗⼝中的最小值。
TCP 拥塞控制采用的四种算法
慢开始
发送方维持一个拥塞窗口 cwnd ( congestion window ) 的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞。
发送方控制拥塞窗口的原则是:只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络中的分组数。
慢开始算法:当主机开始发送数据时,如果立即所大量数据字节注入到网络,那么就有可能引起网络拥塞,因为现在并不清楚网络的负荷情况。因此,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是说,由小到大逐渐增大拥塞窗口数值。通常在刚刚开始发送报文段时,先把拥塞窗口 cwnd 设置为一个最大报文段MSS的数值。而在每收到一个对新的报文段的确认后,把拥塞窗口增加至多一个MSS的数值。用这样的方法逐步增大发送方的拥塞窗口 cwnd ,可以使分组注入到网络的速率更加合理。
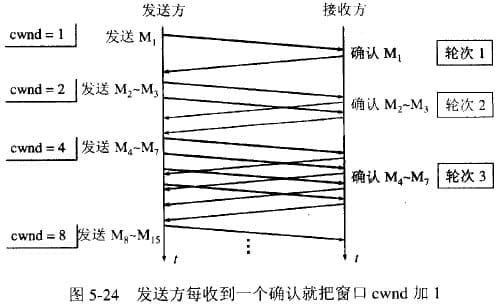
每经过一个传输轮次,拥塞窗口 cwnd 就加倍。一个传输轮次所经历的时间其实就是往返时间RTT。不过“传输轮次”更加强调:把拥塞窗口cwnd所允许发送的报文段都连续发送出去,并收到了对已发送的最后一个字节的确认。
另,慢开始的“慢”并不是指 cwnd 的增长速率慢,而是指在TCP开始发送报文段时先设置 cwnd=1,使得发送方在开始时只发送一个报文段(目的是试探一下网络的拥塞情况),然后再逐渐增大 cwnd。
为了防止拥塞窗口 cwnd 增长过大引起网络拥塞,还需要设置一个慢开始门限 ssthresh 状态变量。慢开始门限ssthresh的用法如下:
- 当 cwnd < ssthresh 时,使用上述的慢开始算法。
- 当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。
- 当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞控制避免算法。
拥塞避免
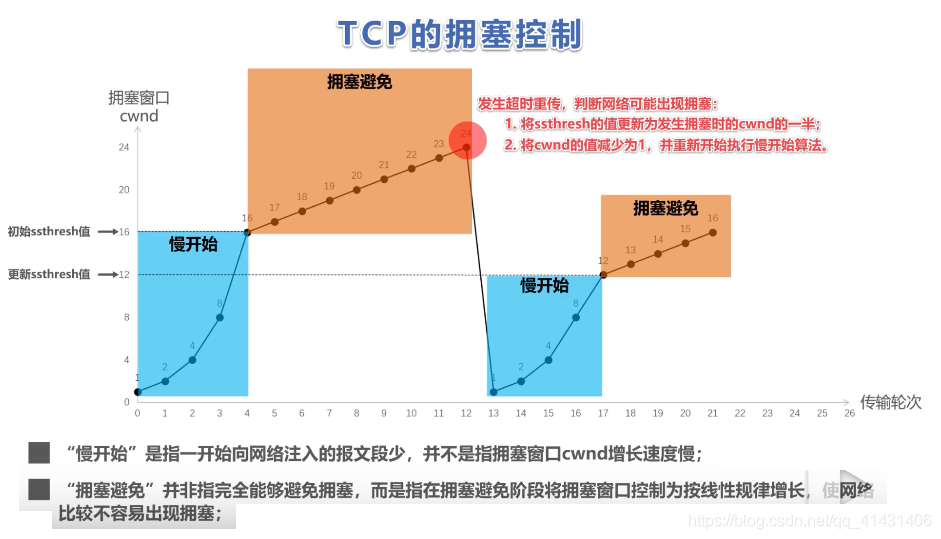
拥塞控制是为了让拥塞窗口 cwnd 缓慢地增大,即每经过一个往返时间 RTT (往返时间定义为发送方发送数据到收到确认报文所经历的时间)就把发送方的 cwnd 值加 1,通过让 cwnd 线性增长,防止很快就遇到网络拥塞状态。
当网络拥塞发生时,让新的慢开始门限值变为发生拥塞时候的值的一半, 并将拥塞窗口置为 1 , 然后再次重复两种算法(慢开始和拥塞避免), 这时一瞬间会将网络中的数据量大量降低。
快重传
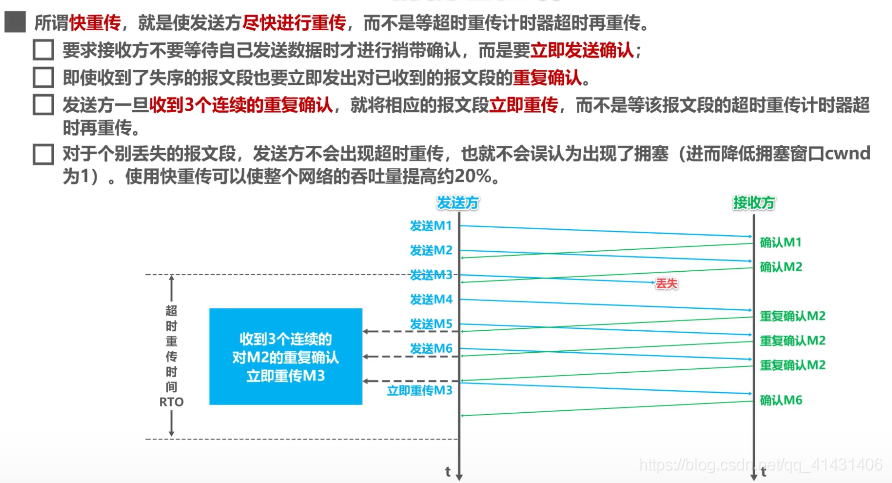
快恢复
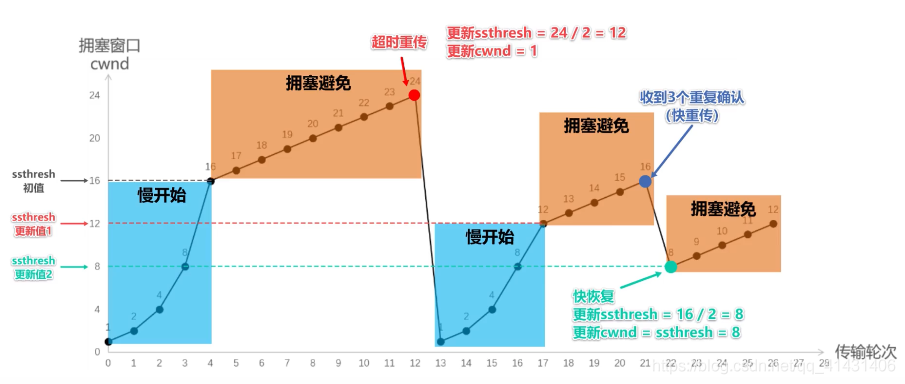
发送方一旦收到 3 个重复确认,就知道现在只是丟失了个别的报文段。于是不启动慢开始算法,而执行快恢复算法;
- 发送方将慢开始门限 ssthresh 值和拥塞窗口 cwnd 值调整为当前窗口的一半; 开始执行拥塞避免算法。
- 也有的快恢复实现是把快恢复开始时的拥塞窗口 cwnd 值再增大一些,即等于新的 ssthresh + 3。
- 既然发送方收到3个重复的确认,就表明有3个数据报文段已经离开了网络;
- 这3个报文段不再消耓网络资源而是停留在接收方的接收缓存中;
- 可见现在网络中不是堆积了报文段而是减少了 3 个报文段。因此可以适当把拥塞窗口扩大些。
TCP 粘包问题
为什么会发生TCP粘包和拆包?
- 发送方写入的数据大于套接字缓冲区的大小,此时将发生拆包。
- 发送方写入的数据小于套接字缓冲区大小,由于 TCP 默认使用 Nagle 算法,只有当收到一个确认后,才将分组发送给对端,当发送方收集了多个较小的分组,就会一起发送给对端,这将会发生粘包。
- 进行 MSS (最大报文长度)大小的 TCP 分段,当 TCP 报文的数据部分大于 MSS 的时候将发生拆包。
- 发送方发送的数据太快,接收方处理数据的速度赶不上发送端的速度,将发生粘包。
常见解决方法
- 在消息的头部添加消息长度字段,服务端获取消息头的时候解析消息长度,然后向后读取相应长度的内容。
- 固定消息数据的长度,服务端每次读取既定长度的内容作为一条完整消息,当消息不够长时,空位补上固定字符。但是该方法会浪费网络资源。
- 设置消息边界,也可以理解为分隔符,服务端从数据流中按消息边界分离出消息内容,一般使用换行符。
什么时候需要处理粘包问题?
- 当接收端同时收到多个分组,并且这些分组之间毫无关系时,需要处理粘包;而当多个分组属于同一数据的不同部分时,并不需要处理粘包问题。
TCP是面向字节流的一种传输协议,本身只有数据报文的说法。数据包是指应用层的一个完整数据。因为TCP不管你的应用层数据包有多大,反正发送缓冲区满了,就把字节全部发出去。这样接收方,可能收到的这次数据报文是不完整的应用层数据包,称为拆包。
-
单看传输层,TCP是「面向字节流」传输的,本身是没有「包」的概念的,接收方将接收的报文段(segment)的数据提取出来按序放置在缓存中。
-
但是从应用层的角度看是有「包」的概念的,例如 http/1.1中采用了「管道(pipeline)」的思想,即可以多个http数据流「复用」同一个TCP,因此各个http数据流之间是「纠缠」的,那么就需要在应用层进行处理,「区分不同」的数据流,自然就需要处理「粘包」的问题。
-
个人认为TCP层没有「包」的概念反映了TCP层对应用层「多数据流」的支持较弱,这恰恰导致了粘包问题。而这种弱势也导致了HTTP/3转向了QUIC,也就是基于UDP,自行实现更好的「多数据流复用/分用」。
TCP 报文包含哪些信息
TCP 报文是 TCP 传输的的数据单元,也叫做报文段,其报文格式如下图所示:
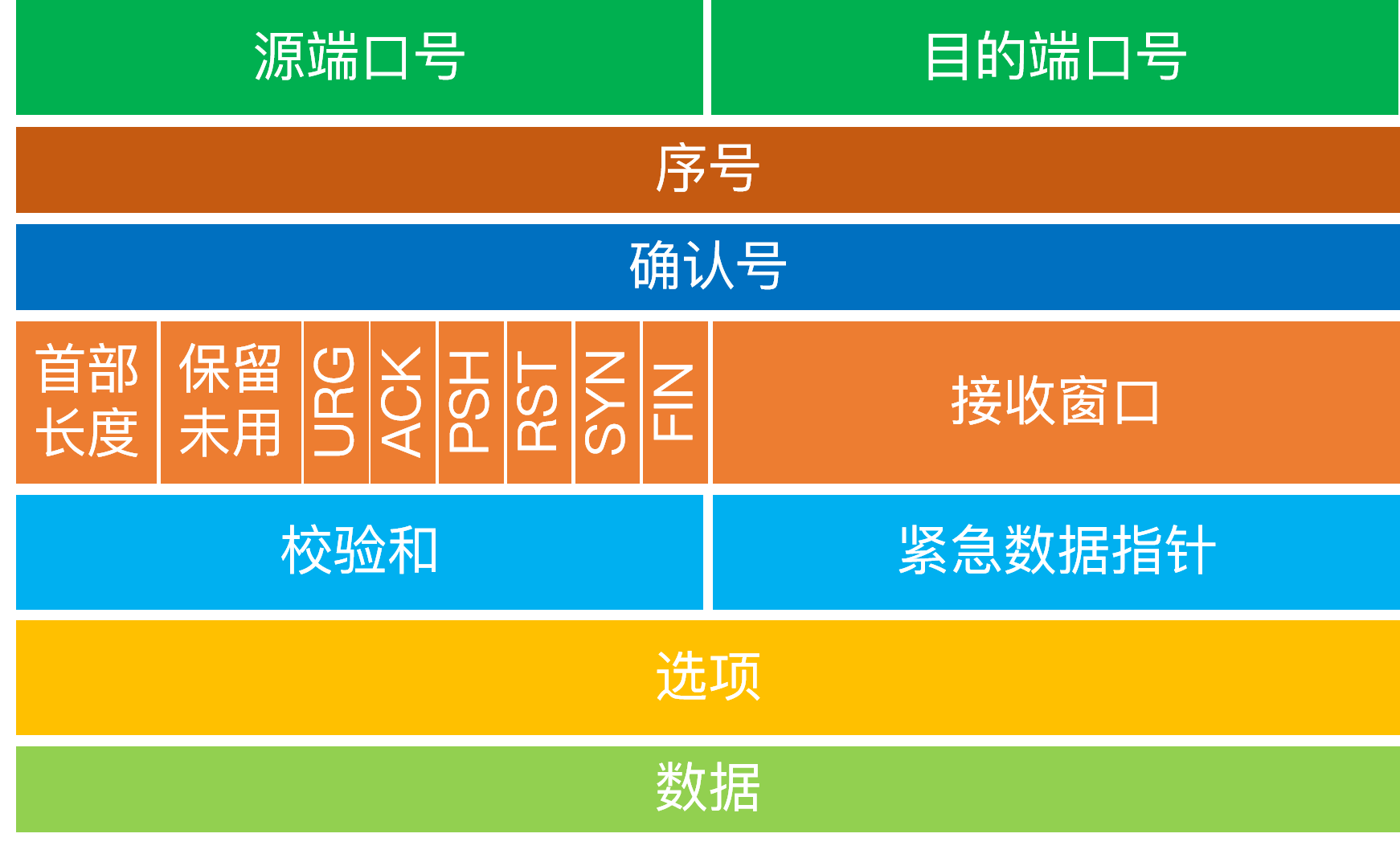
-
源端口和目的端口号:它用于多路复用/分解来自或送往上层应用的数据,其和 IP 数据报中的源 IP 与目的 IP 地址一同确定一条 TCP 连接。
-
序号和确认号字段:序号是本报文段发送的数据部分中第一个字节的编号,在 TCP 传送的流中,每一个字节一个序号。例如一个报文段的序号为 100,此报文段数据部分共有 100 个字节,则下一个报文段的序号为 200。序号确保了 TCP 传输的有序性。确认号,即 ACK,指明下一个想要收到的字节序号,发送 ACK 时表明当前序号之前的所有数据已经正确接收。这两个字段的主要目的是保证数据可靠传输。
-
首部长度:该字段指示了以 32 比特的字为单位的 TCP 的首部长度。其中固定字段长度为 20 字节,由于首部长度可能含有可选项内容,因此 TCP 报头的长度是不确定的,20 字节是 TCP 首部的最小长度。
-
保留:为将来用于新的用途而保留。
-
控制位:URG 表示紧急指针标志,该位为 1 时表示紧急指针有效,为 0 则忽略;ACK 为确认序号标志,即相应报文段包括一个对已被成功接收报文段的确认;PSH 为 push 标志,当该位为 1 时,则指示接收方在接收到该报文段以后,应尽快将这个报文段交给应用程序,而不是在缓冲区排队; RST 为重置连接标志,当出现错误连接时,使用此标志来拒绝非法的请求;SYN 为同步序号,在连接的建立过程中使用,例如三次握手时,发送方发送 SYN 包表示请求建立连接;FIN 为 finish 标志,用于释放连接,为 1 时表示发送方已经没有数据发送了,即关闭本方数据流。
-
接收窗口:主要用于 TCP 流量控制。该字段用来告诉发送方其窗口(缓冲区)大小,以此控制发送速率,从而达到流量控制的目的。
-
校验和:奇偶校验,此校验和是对整个 TCP 报文段,包括 TCP 头部和 数据部分。该校验和是一个端到端的校验和,由发送端计算和存储,并由接收端进行验证,主要目的是检验数据是否发生改动,若检测出差错,接收方会丢弃该 TCP 报文。
-
紧急数据指针:紧急数据用于告知紧急数据所在的位置,在URG标志位为 1 时才有效。当紧急数据存在时,TCP 必须通知接收方的上层实体,接收方会对紧急模式采取相应的处理。
-
选项:该字段一般为空,可根据首部长度进行推算。主要有以下作用:
- TCP 连接初始化时,通信双方确认最大报文长度。
- 在高速数据传输时,可使用该选项协商窗口扩大因子。
- 作为时间戳时,提供一个 较为精准的 RTT。
-
数据:TCP 报文中的数据部分也是可选的,例如在 TCP 三次握手和四次挥手过程中,通信双方交换的报文只包含头部信息,数据部分为空,只有当连接成功建立后,TCP 包才真正携带数据。
UDP 报文格式:
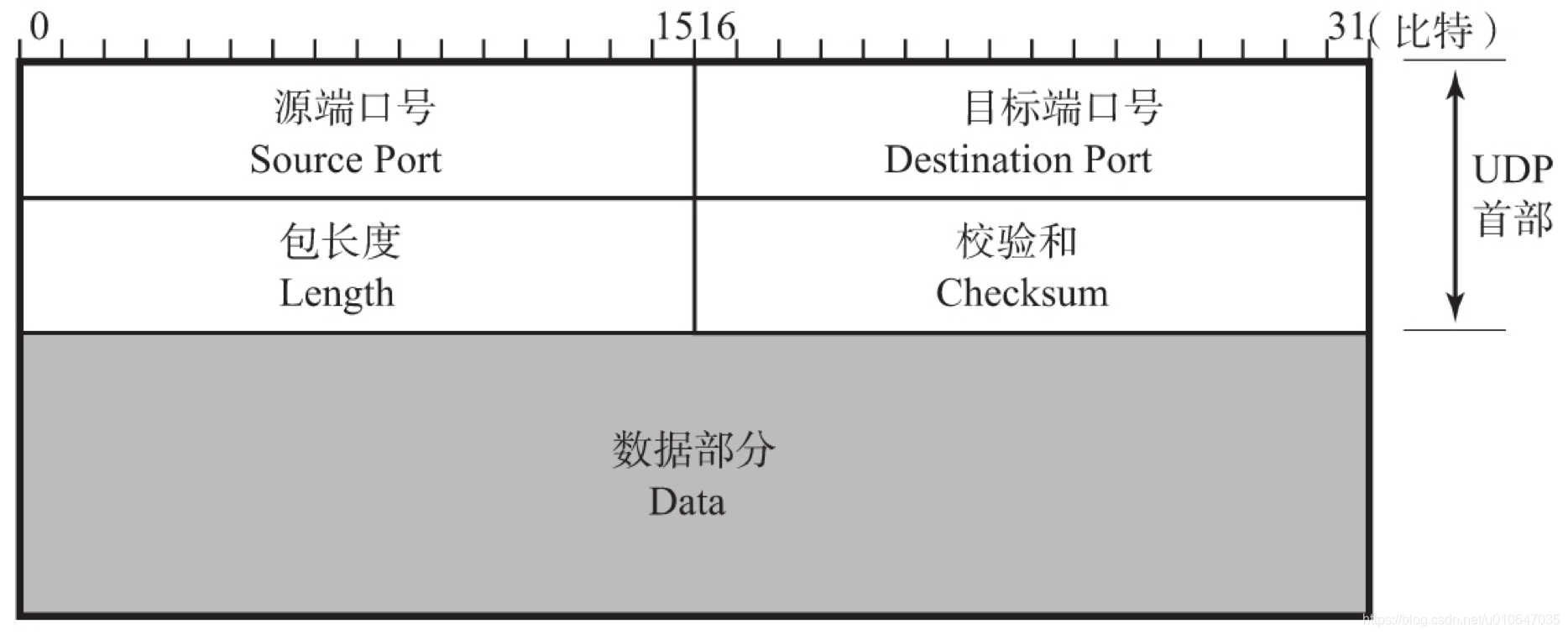
SYN FLOOD 是什么
SYN Flood 是种典型的 DoS(拒绝服务)攻击,其目的是通过消耗服务器所有可用资源,使服务器无法用于处理合法请求。通过重复发送初始连接请求(SYN)数据包,攻击者能够压倒目标服务器上的所有可用端口,导致目标设备根本不响应合法请求。
SYN- Flood 攻击是网络上最为常见的 DDoS 攻击,也是最为经典的拒绝服务攻击,SYN- Flood 攻击会造成可用 TCP 连接队列很快阻塞,系统资源急剧下降,致使服务不可用,危害巨大。
一、syn_flood攻击原理是什么?
syn_flood 攻击利用了 TCP 协议实现上的一个缺陷,通过向网络服务所在端口发送大量的伪造源地址的攻击报文,就可能造成目标服务器中的半开连接队列被占满,从而阻止其他合法用户进行访问。这种攻击早在1996年就被发现,但至今仍然显示出强大的生命力。很多操作系统,甚至防火墙、路由器都无法有效地防御这种攻击,而且由于它可以方便地伪造源地址,追查起来非常困难。
客户端发起连接的报文即为syn报文。当攻击者发送大量的伪造 IP 端口的 syn 报文时,服务端接收到 syn 报文后,新建一共表项插入到半连接队列,并发送 syn_ack 。但由于这些 syn 报文都是伪造的,发出去的 syn_ack报文将没有回应。TCP 是可靠协议,这时就会重传报文,默认重试次数为 5 次,重试的间隔时间从1s开始每次都番倍,分别为1s + 2s + 4s + 8s +16s = 31s ,第 5 次发出后还要等 32s 才知道第 5 次也超时了,所以一共是31 + 32 = 63s 。
也就是说一个假的 syn 报文,会占用 TCP 准备队列 63s 之久,而半连接队列默认为 1024,系统默认不同,可 cat /proc/sys/net/ipv4/tcp\_max\_syn\_backlog c 查看。也就是说在没有任何防护的情况下,每秒发送 200 个伪造 syn 包,就足够撑爆半连接队列,从而使真正的连接无法建立,无法响应正常请求。
一台普通的每秒就可以轻松伪造 100w 个 syn 包。因此即使把队列大小调大最大也无济于事。
二、如何防范 syn_flood 攻击?
针对 syn_flood 攻击有2种比较通用的防范机制:
1. cookie源认证:
原理是 syn 报文首先由 DDOS 防护系统来响应 syn_ack 。带上特定的 sequence number (记为cookie)。真实的客户端会返回一个 ack 并且 Acknowledgment number 为 cookie+1。 而伪造的客户端,将不会作出响应。这样我们就可以知道那些 IP 对应的客户端是真实的,将真实客户端 IP 加入白名单。下次访问直接通过,而其他伪造的 syn 报文就被拦截。防护示意图如下:
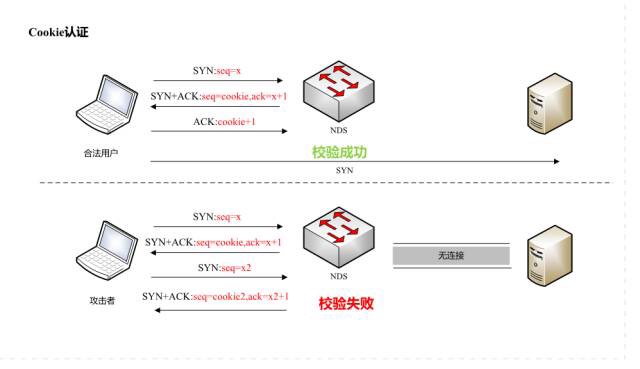
2.reset认证:
Reset 认证利用的是 TCP 协议的可靠性,也是首先由 DDOS 防护系统来响应 syn 。防护设备收到 syn 后响应syn_ack , 将 Acknowledgement number (确认号) 设为特定值(记为 cookie )。当真实客户端收到这个报文时,发现确认号不正确,将发送 reset 报文,并且 sequence number 为 cookie + 1。
而伪造的源,将不会有任何回应。这样我们就可以将真实的客户端IP加入白名单。
通常在实际应用中还会结合首包丢弃的方式结合源认证一起使用,首包丢弃原理为:在 DDOS 防护设备收到 syn 报文后,记录 5 元组,然后丢弃。正常用户将重传 syn 报文,防护设备在收到报文命中 5 元组,并且在规定时间内,则转发。当重传 syn 报文到达一定阀值时,在启用上述的源认证。这样就能减少反射 syn_ack 报文的数量,缓解网络拥堵,同时对防护不产生影响。
为什么服务端易受到 SYN 攻击
在 TCP 建立连接的过程中,因为服务端不确定自己发给客户端的 SYN-ACK 消息或客户端反馈的 ACK 消息是否会丢在半路,所以会给每个待完成的半开连接状态设一个定时器,如果超过时间还没有收到客户端的 ACK 消息,则重新发送一次 SYN-ACK 消息给客户端,直到重试超过一定次数时才会放弃。
服务端为了维持半开连接状态,需要分配内核资源维护半开连接。当攻击者伪造海量的虚假 IP 向服务端发送 SYN 包时,就形成了 SYN FLOOD 攻击。攻击者故意不响应 ACK 消息,导致服务端被大量注定不能完成的半连接占据,直到资源耗尽,停止响应正常的连接请求。
解决方法:
- 直接的方法是提高 TCP 端口容量的同时减少半开连接的资源占用时间,然而该方法只是稍稍提高了防御能力;
- 部署能够辨别恶意 IP 的路由器,将伪造 IP 地址的发送方发送的 SYN 消息过滤掉,该方案作用一般不是太大;
上述两种方法虽然在一定程度上能够提高服务器的防御能力,但是没有从根本上解决服务器资源消耗殆尽的问题,而以下几种方法的出发点都是在发送方发送确认回复后才开始分配传输资源,从而避免服务器资源消耗殆尽。
-
SYN Cache:该方法首先构造一个全局 Hash Table,用来缓存系统当前所有的半开连接信息。在 Hash Table 中的每个桶的容量大小是有限制的,当桶满时,会主动丢掉早来的信息。当服务端收到一个 SYN 消息后,会通过一个映射函数生成一个相应的 Key 值,使得当前半连接信息存入相应的桶中。当收到客户端正确的确认报文后,服务端才开始分配传输资源块,并将相应的半开连接信息从表中删除。和服务器传输资源相比,维护表的开销要小得多。
-
SYN Cookies:该方案原理和 HTTP Cookies 技术类似,服务端通过特定的算法将半开连接信息编码成序列号或者时间戳,用作服务端给客户端的消息编号,随 SYN-ACK 消息一同返回给连接发起方,这样在连接建立完成前服务端不保存任何信息,直到发送方发送 ACK 确认报文并且服务端成功验证编码信息后,服务端才开始分配传输资源。若请求方是攻击者,则不会向服务端会 ACK 消息,由于未成功建立连接,因此服务端并没有花费任何额外的开销。
然而该方案也存在一些缺点,由于服务端并不保存半开连接状态,因此也就丧失了超时重传的能力,这在一定程度上降低了正常用户的连接成功率。此外,客户端发送给服务端的确认报文存在传输丢失的可能,当 ACK 确认报文丢失时,服务端和客户端会对连接的成功与否产生歧义,此时就需要上层应用采取相应的策略进行处理了。
- SYN Proxy:在客户端和服务器之间部署一个代理服务器,类似于防火墙的作用。通过代理服务器与客户端进行建立连接的过程,之后代理服务器充当客户端将成功建立连接的客户端信息发送给服务器。这种方法基本不消耗服务器的资源,但是建立连接的时间变长了(总共需要 6 次握手)。
高并发服务器客户端主动关闭连接和服务端主动关闭连接的区别
以下是针对 TCP 服务来说的:
- 服务端主动关闭连接
在高并发场景下,当服务端主动关闭连接时,此时服务器上就会有大量的连接处于 TIME-WAIT 状态
- 客户端主动关闭连接
当客户端主动关闭连接时,我们并不需要关心 TIME-WAIT 状态过多造成的问题,但是需要关注服务端保持大量的 CLOSE-WAIT 状态时会产生的问题
无论是客户端还是服务器主动关闭连接,从本质上来说,在高并发场景下主要关心的就是服务端的资源占用问题,而这也是采用 TCP 传输协议必须要面对的问题,其问题解决的出发点也是如何处理好服务质量和资源消耗之间的关系。
网络层
IP 协议的定义和作用
IP 协议(Internet Protocol)又称互联网协议,是支持网间互联的数据包协议。该协议工作在网络层,主要目的就是为了提高网络的可扩展性,和传输层 TCP 相比,IP 协议提供一种无连接/不可靠、尽力而为的数据包传输服务,其与 TCP 协议(传输控制协议)一起构成了 TCP/IP 协议族的核心。IP 协议主要有以下几个作用:
- 寻址和路由:在 IP 数据报中会携带源 IP 地址和目的 IP 地址来标识该数据包的源主机和目的主机。IP 数据报在传输过程中,每个中间节点(IP 网关、路由器)只根据网络地址进行转发,如果中间节点是路由器,则路由器会根据路由表选择合适的路径。IP 协议根据路由选择协议提供的路由信息对 IP 数据报进行转发,直至抵达目的主机。
- 分段与重组:IP 数据包在传输过程中可能会经过不同的网络,在不同的网络中数据包的最大长度限制是不同的,IP 协议通过给每个 IP 数据包分配一个标识符以及分段与组装的相关信息,使得数据包在不同的网络中能够传输,被分段后的 IP 数据报可以独立地在网络中进行转发,在到达目的主机后由目的主机完成重组工作,恢复出原来的 IP 数据包。
域名和 IP 的关系,一个 IP 可以对应多个域名吗
整个互联网是一个单一的、抽象的网络。互联网上每一台主机或者路由器在连入互联网时需要被分配一个唯一的标识符,即 IP 地址,在 IPv4 协议下,这个标识符是一个 32 位无符号二进制数。互联网上和一个设备通信时,需要知道其 IP 地址。互联网最常见的应用之一是向某个特定主机请求一些服务,例如请求某个网页的信息,请求某个邮件服务器的服务。然而,数字 IP 地址不方便人们记忆和描述。为此,域名系统(Domain Name System,DNS)被开发和应用,使得人们可以方便地将一串便于记忆和描述的字符串,称为域名,利用 DNS 自动转换为 IP 地址。互联网上分布运行着许多域名服务器,其他互联网上的设备可以向他们询问域名对应的 IP 地址是什么,此即域名解析。网站的运营者可以在域名注册商处注册域名,使其指向自己的网站服务器的 IP 地址,使得这一域名被其他互联网上的用户使用。
在最简单的情形下,一个域名只对应一个 IP 地址,一个 IP 地址只对应一个域名。
实际中,根据需求,多个域名可以被解析为同一个 IP 地址。例如具有一个 IP 地址的服务器上的运营的网站,为了推广自己给自己注册了许多朗朗上口的域名;或者提前注册多个类似域名,防止被竞争者不当利用;或者一个网站历史上使用了另一个域名,现在多个域名同时可用,并被解析到同一个 IP 地址。
此外,相对少见地,一个域名可能会被解析出多个 IP 地址。例如,这个网站为了平衡负载,在多个服务器上提供了同一类服务。这可能表现为:不同时间,同一个域名被解析为不同的 IP;一个域名解析的结果可能有若干备选 IP;一个域名不同的网络服务提供商的网络中会被解析出不同的 IP。
示例:如图,在实现了 Posix 的计算机系统上,nslookup 命令可以用于解析域名。运行 nslookup www.baidu.com 可能会返回多个 IP 地址,而查询 www.baidu.com 和 www.a.shifen.com 的 IP 地址包含了重复的 IP 地址条目。
参考资料:RFC 791,RFC 1034,1035。
IPV4 地址不够如何解决
- DHCP:动态主机配置协议。动态分配 IP 地址,只给接入网络的设备分配IP地址,因此同一个 MAC 地址的设备,每次接入互联网时,得到的IP地址不一定是相同的,该协议使得空闲的 IP 地址可以得到充分利用。
- CIDR:无类别域间路由。CIDR 消除了传统的 A 类、B 类、C 类地址以及划分子网的概念,因而更加有效的分配 IPv4 的地址空间,但无法从根本上解决地址耗尽问题。
- NAT:网络地址转换协议。我们知道属于不同局域网的主机可以使用相同的 IP 地址,从而一定程度上缓解了 IP 资源枯竭的问题。然而主机在局域网中使用的 IP 地址是不能在公网中使用的,当局域网主机想要与公网进行通信时, NAT 方法可以将该主机 IP 地址转换成全球 IP 地址。该协议能够有效解决 IP 地址不足的问题。
- IPv6 :作为接替 IPv4 的下一代互联网协议,其可以实现 2 的 128 次方个地址,而这个数量级,即使是给地球上每一颗沙子都分配一个IP地址,该协议能够从根本上解决 IPv4 地址不够用的问题。
路由器的分组转发流程
① 从 IP 数据包中提取出目的主机的 IP 地址,找到其所在的网络;
② 判断目的 IP 地址所在的网络是否与本路由器直接相连,如果是,则不需要经过其它路由器直接交付,否则执行 ③;
③ 检查路由表中是否有目的 IP 地址的特定主机路由。如果有,则按照路由表传送到下一跳路由器中,否则执行 ④;
④ 逐条检查路由表,使用每一行的子网掩码与目的IP匹配。若找到匹配路由,则按照路由表转发到下一跳路由器中,否则执行步骤 ⑤;
⑤ 若路由表中设置有默认路由,则按照默认路由转发到默认路由器中,否则执行步骤 ⑥;
⑥ 无法找到合适路由,向源主机报错。
-
路由表的结构:
常规的路由表包括"目标地址"、“子网掩码”、“网关”、“接口”、“跃点数”。-
目标地址(Network Destination):数据包最终希望被送达的地址;
-
子网掩码(Netmask):和地址实际的子网掩码并不一定相同,它的真正意义是用来表示 “在匹配网络包目标地址时需要比对的比特数”。
-
网关(GateWay):它表示目标地址对应的下一跳路由的IP地址,也就是说——把包发送到"网关"所对应的路由器,它知道下一步要把包发往哪里。当"网关"中的内容为空时,表示 IP 头中的 IP 地址就是要转发的目的地址,而不需要再转发到下一个路由器。
-
接口(Interface):存储着一个 IP 地址,当匹配到该条路由时,就会使用该IP地址对应的接口将数据包发送到"网关"对应的IP地址。
-
-
最长匹配原则:
当匹配到多条目标地址时,路由器优先选择网络号比特数最长的地址。上文中的3⃣️4⃣️两点就是该规则下的两种极端情况。对于目的IP地址对应的特定主机路由,它在路由表中的"子网掩码"为"255.255.255.255",相当于具有最长"网络号",所以会被最优先匹配;而默认路由在表中的"子网掩码"是"0.0.0.0",它表示需要匹配的网络号比特数为 0,所以一切目标 IP 都可以与默认路由对应的地址匹配上。 -
当无法找到合适路由时,路由器丢弃这个包,并通过 ICMP 消息告知对方。
路由器和交换机的区别
- 交换机:交换机用于局域网,利用主机的物理地址(MAC 地址)确定数据转发的目的地址,它工作于数据链路层。
- 路由器:路由器通过数据包中的目的 IP 地址识别不同的网络从而确定数据转发的目的地址,网络号是唯一的。路由器根据路由选择协议和路由表信息从而确定数据的转发路径,直到到达目的网络,它工作于网络层。
ICMP 协议概念/作用
ICMP(Internet Control Message Protocol)是因特网控制报文协议,主要是实现 IP 协议中未实现的部分功能,是一种网络层协议。该协议并不传输数据,只传输控制信息来辅助网络层通信。其主要的功能是验证网络是否畅通(确认接收方是否成功接收到 IP 数据包)以及辅助 IP 协议实现可靠传输(若发生 IP 丢包,ICMP 会通知发送方 IP 数据包被丢弃的原因,之后发送方会进行相应的处理)。

ICMP 的应用
- Ping
Ping(Packet Internet Groper),即因特网包探测器,是一种工作在网络层的服务命令,主要用于测试网络连接量。本地主机通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 响应报文,Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率从而推断网络是否通畅、运行是否正常等。
- TraceRoute
TraceRoute 是 ICMP 的另一个应用,其主要用来跟踪一个分组从源点耗费最少 TTL 到达目的地的路径。TraceRoute 通过逐渐增大 TTL 值并重复发送数据报来实现其功能,首先,TraceRoute 会发送一个 TTL 为 1 的 IP 数据报到目的地,当路径上的第一个路由器收到这个数据报时,它将 TTL 的值减 1,此时 TTL = 0,所以路由器会将这个数据报丢掉,并返回一个差错报告报文,之后源主机会接着发送一个 TTL 为 2 的数据报,并重复此过程,直到数据报能够刚好到达目的主机。此时 TTL = 0,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文,之后源主机便知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
两台电脑连起来后 ping 不通,你觉得可能存在哪些问题?
- 首先看网络是否连接正常,检查网卡驱动是否正确安装。
- 局域网设置问题,检查 IP 地址是否设置正确。
- 看是否被防火墙阻拦(有些设置中防火墙会对 ICMP 报文进行过滤),如果是的话,尝试关闭防火墙 。
- 看是否被第三方软件拦截。
- 两台设备间的网络延迟是否过大(例如路由设置不合理),导致 ICMP 报文无法在规定的时间内收到。
ARP 地址解析协议的原理和地址解析过程
ARP(Address Resolution Protocol)是地址解析协议的缩写,该协议提供根据 IP 地址获取物理地址的功能,它工作在第二层,是一个数据链路层协议(TCP/IP中属于网络层),其在本层和物理层进行联系,同时向上层提供服务。当通过以太网发送 IP 数据包时,需要先封装 32 位的 IP 地址和 48位 MAC 地址。在局域网中两台主机进行通信时需要依靠各自的物理地址进行标识,但由于发送方只知道目标 IP 地址,不知道其 MAC 地址,因此需要使用地址解析协议。 ARP 协议的解析过程如下:
① 首先,每个主机都会在自己的 ARP 缓冲区中建立一个 ARP 列表,以表示 IP 地址和 MAC 地址之间的对应关系;
② 当源主机要发送数据时,首先检查 ARP 列表中是否有 IP 地址对应的目的主机 MAC 地址,如果存在,则可以直接发送数据,否则就向同一子网的所有主机发送 ARP 数据包。该数据包包括的内容有源主机的 IP 地址和 MAC 地址,以及目的主机的 IP 地址。
③ 当本网络中的所有主机收到该 ARP 数据包时,首先检查数据包中的 目的主机IP 地址是否是自己的 IP 地址,如果不是,则忽略该数据包,如果是,则首先从数据包中取出源主机的 IP 和 MAC 地址写入到 ARP 列表中,如果已经存在,则覆盖,然后将自己的 MAC 地址写入 ARP 响应包中,告诉源主机自己是它想要找的 MAC 地址。
④ 源主机收到 ARP 响应包后。将目的主机的 IP 和 MAC 地址写入 ARP 列表,并利用此信息发送数据。如果源主机一直没有收到 ARP 响应数据包,表示 ARP 查询失败。
使用ARP的4种情况:
- 发送方是主机,要把 IP 数据报发送到本网络上的另一个主机。这时用 ARP 找到目的主机的硬件地址。
- 发送方是主机,要把 IP 数据报发送到另一个网络上的一个主机。这时用 ARP 找到本网络上的一个路由器的硬件地址。剩下的工作由这个路由器来完成。
- 发送方是路由器,要把 IP 数据报转发到本网络上的一个主机。这时用 ARP 找到目的主机的硬件地址。
- 发送方是路由器,要把 IP 数据报转发到另一个网络上的一个主机。这时用 ARP 找到本网络上另一个路由器的硬件地址。剩下的工作由这个路由器来完成。
网络地址转换 NAT
NAT(Network Address Translation),即网络地址转换,它是一种把内部私有网络地址翻译成公有网络 IP 地址的技术。该技术不仅能解决 IP 地址不足的问题,而且还能隐藏和保护网络内部主机,从而避免来自外部网络的攻击。
NAT 的实现方式主要有三种:
- 静态转换:内部私有 IP 地址和公有 IP 地址是一对一的关系,并且不会发生改变。通过静态转换,可以实现外部网络对内部网络特定设备的访问,这种方式原理简单,但当某一共有 IP 地址被占用时,跟这个 IP 绑定的内部主机将无法访问 Internet。
- 动态转换:采用动态转换的方式时,私有 IP 地址每次转化成的公有 IP 地址是不唯一的。当私有 IP 地址被授权访问 Internet 时会被随机转换成一个合法的公有 IP 地址。当 ISP 通过的合法 IP 地址数量略少于网络内部计算机数量时,可以采用这种方式。
- 端口多路复用:该方式将外出数据包的源端口进行端口转换,通过端口多路复用的方式,实现内部网络所有主机共享一个合法的外部 IP 地址进行 Internet 访问,从而最大限度地节约 IP 地址资源。同时,该方案可以隐藏内部网络中的主机,从而有效避免来自 Internet 的攻击。


TTL 是什么?有什么作用
TTL 是指生存时间,简单来说,它表示了数据包在网络中的时间。每经过一个路由器后 TTL 就减一,这样 TTL 最终会减为 0 ,当 TTL 为 0 时,则将数据包丢弃。通过设置 TTL 可以避免这两个路由器之间形成环导致数据包在环路上死转的情况,由于有了 TTL ,当 TTL 为 0 时,数据包就会被抛弃。
运输层协议和网络层协议的区别
网络层协议:主机间的逻辑通信;无连接不可靠;
传输层协议:进程间的逻辑通信;其中 TCP 面向连接可靠;
DHCP 动态主机配置协议

数据链路层
MAC 地址和 IP 地址分别有什么作用
- MAC 地址是数据链路层和物理层使用的地址,是写在网卡上的物理地址。MAC 地址用来定义网络设备的位置。
- IP 地址是网络层和以上各层使用的地址,是一种逻辑地址。IP 地址用来区别网络上的计算机。
为什么有了 MAC 地址还需要 IP 地址
如果我们只使用 MAC 地址进行寻址的话,我们需要路由器记住每个 MAC 地址属于哪一个子网,不然每一次路由器收到数据包时都要满世界寻找目的 MAC 地址。而我们知道 MAC 地址的长度为 48 位,也就是说最多总共有 2 的 48 次方个 MAC 地址,这就意味着每个路由器需要 256 T 的内存,这显然是不现实的。
和 MAC 地址不同,IP 地址是和地域相关的,在一个子网中的设备,我们给其分配的 IP 地址前缀都是一样的,这样路由器就能根据 IP 地址的前缀知道这个设备属于哪个子网,剩下的寻址就交给子网内部实现,从而大大减少了路由器所需要的内存。
为什么有了 IP 地址还需要 MAC 地址
只有当设备连入网络时,才能根据他进入了哪个子网来为其分配 IP 地址,在设备还没有 IP 地址的时候或者在分配 IP 地址的过程中,我们需要 MAC 地址来区分不同的设备。
私网地址和公网地址之间进行转换:同一个局域网内的两个私网地址,经过转换之后外面看到的一样吗
当采用静态或者动态转换时,由于一个私网 IP 地址对应一个公网地址,因此经过转换之后的公网 IP 地址是不同的;而采用端口复用方式的话,在一个子网中的所有地址都采用一个公网地址,但是使用的端口是不同的。
NAT(网络地址转换)有三种方法:静态转换、动态转换、端口复用。
- 静态转换:私网地址转换为固定公网地址,当公网地址被占用,则相应设备无法联网。
- 动态转换:私网地址转换为不固定的公网地址,避免了公网地址被占用的问题。
- 端口复用:私网地址通过同一个公网地址的不同端口传输。这样隐藏了内部网络中的主机,避免了根据地址的攻击。同时节约了 IP 地址资源。
以太网中的 CSMA/CD 协议
CSMA/CD 为载波侦听多路访问/冲突检测,是像以太网这种广播网络采用的一种机制,我们知道在以太网中多台主机在同一个信道中进行数据传输,CSMA/CD 很好的解决了共享信道通信中出现的问题,它的工作原理主要包括两个部分:
- 载波监听:当使用 CSMA/CD 协议时,总线上的各个节点都在监听信道上是否有信号在传输,如果有的话,表明信道处于忙碌状态,继续保持监听,直到信道空闲为止。如果发现信道是空闲的,就立即发送数据。
- 冲突检测:当两个或两个以上节点同时监听到信道空闲,便开始发送数据,此时就会发生碰撞(数据的传输延迟也可能引发碰撞)。当两个帧发生冲突时,数据帧就会破坏而失去了继续传输的意义。在数据的发送过程中,以太网是一直在监听信道的,当检测到当前信道冲突,就立即停止这次传输,避免造成网络资源浪费,同时向信道发送一个「冲突」信号,确保其它节点也发现该冲突。之后采用一种二进制退避策略让待发送数据的节点随机退避一段时间之后重新。
数据链路层上的三个基本问题
- 封装成帧:将网络层传下来的分组前后分别添加首部和尾部,这样就构成了帧。首部和尾部的一个重要作用是帧定界,也携带了一些必要的控制信息,对于每种数据链路层协议都规定了帧的数据部分的最大长度。
- 透明传输:帧使用首部和尾部进行定界,如果帧的数据部分含有和首部和尾部相同的内容, 那么帧的开始和结束的位置就会判断错,因此需要在数据部分中出现有歧义的内容前边插入转义字符,如果数据部分出现转义字符,则在该转义字符前再加一个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在。
- 差错检测:目前数据链路层广泛使用循环冗余检验(CRC)来检查数据传输过程中是否产生比特差错。
PPP 协议
互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP(点对点)协议是用户计算机和 ISP 进行通信时所使用的数据链路层协议。点对点协议为点对点连接上传输多协议数据包提供了一个标准方法。该协议设计的目的主要是用来通过拨号或专线方式建立点对点连接发送数据,使其成为各种主机、网桥和路由器之间简单连接的一种解决方案。
PPP 协议具有以下特点:
- PPP 协议具有动态分配 IP 地址的能力,其允许在连接时刻协商 IP 地址。
- PPP 支持多种网络协议,例如 TCP/IP、NETBEUI 等。
- PPP 具有差错检测能力,但不具备纠错能力,所以 PPP 是不可靠传输协议。
- 无重传的机制,网络开销小,速度快。
- PPP 具有身份验证的功能。
为什么 PPP 协议不使用序号和确认机制
- IETF 在设计因特网体系结构时把其中最复杂的部分放在 TCP 协议中,而网际协议 IP 则相对比较简单,它提供的是不可靠的数据包服务,在这种情况下,数据链路层没有必要提供比 IP 协议更多的功能。若使用能够实现可靠传输的数据链路层协议,则开销就要增大,这在数据链路层出现差错概率不大时是得不偿失的。
- 即使数据链路层实现了可靠传输,但其也不能保证网络层的传输也是可靠的,当数据帧在路由器中从数据链路层上升到网络层后,仍有可能因为网络层拥塞而被丢弃。
- PPP 协议在帧格式中有帧检验序列,对每一个收到的帧,PPP 都会进行差错检测,若发现差错,则丢弃该帧。
物理层
物理层主要做什么事情
作为 OSI 参考模型最低的一层,物理层是整个开放系统的基础,该层利用传输介质为通信的两端建立、管理和释放物理连接,实现比特流的透明传输。物理层考虑的是怎样才能在连接各种计算机的传输媒体上传输数据比特流,其尽可能地屏蔽掉不同种类传输媒体和通信手段的差异,使物理层上面的数据链路层感觉不到这些差异,这样就可以使数据链路层只考虑完成本层的协议和服务,而不必考虑网络的具体传输媒体和通信手段是什么。
主机之间的通信方式
- 单工通信:也叫单向通信,发送方和接收方是固定的,消息只能单向传输。例如采集气象数据、家庭电费,网费等数据收集系统,或者打印机等应用主要采用单工通信。
- 半双工通信:也叫双向交替通信,通信双方都可以发送消息,但同一时刻同一信道只允许单方向发送数据。例如传统的对讲机使用的就是半双工通信。
- 全双工通信:也叫双向同时通信,全双工通信允许通信双方同时在两个方向上传输,其要求通信双方都具有独立的发送和接收数据的能力。例如平时我们打电话,自己说话的同时也能听到对面的声音。
通道复用技术
- 频分复用(FDM,Frequency Division Multiplexing)
频分复用将传输信道的总带宽按频率划分为若干个子频带或子信道,每个子信道传输一路信号。用户分到一定的频带后,在数据传输的过程中自始至终地占用这个频带。由于每个用户所分到的频带不同,使得传输信道在同一时刻能够支持不同用户进行数据传输,从而实现复用。除了传统意义上的 FDM 外,目前正交频分复用(OFDM)已在高速通信系统中得到广泛应用。
- 时分复用(TDM,Time Division Multiplexing)
顾名思义,时分复用将信道传输信息的时间划分为若干个时间片,每一个时分复用的用户在每一个 TDM 帧中占用固定时隙进行数据传输。用户所分配到的时隙是固定的,所以时分复用有时也叫做同步时分复用。这种分配方式能够便于调节控制,但是也存在缺点,当某个信道空闲时,其他繁忙的信道无法占用该空闲信道,因此会降低信道利用率。
- 波分复用(WDM,Wavelength Division Multiplexing)
在光通信领域通常按照波长而不是频率来命名,因为光的频率和波长具有单一对应关系,因此 WDM 本质上也是 FDM,光通信系统中,通常由光来运载信号进行传输,WDM 是在一条光纤上传输多个波长光信号,其将 1 根光纤看做多条「虚拟」光纤,每条「虚拟」光纤工作在不同的波长上,从而极大地提高了光纤的传输容量。
- 码分复用(CDM,Code Division Multiplexing)
码分复用是靠不同的编码来区分各路原始信号的一种复用方式,不同的用户使用相互正交的码字携带信息。由于码组相互正交,因此接收方能够有效区分不同的用户数据,从而实现每一个用户可以在同样的时间在同样的频带进行数据传输,频谱资源利用率高。其主要和各种多址接入技术相结合从而产生各种接入技术,包括无线和优先接入。
几种常用的宽带接入技术
我们一般将速率超过 1 Mbps 的接入称为宽带接入,目前常用的宽带接入技术主要包括:ADSL 和 FTTx + LAN。
- ADSL
ADSL 全称为非对称用户数字环路,是铜线宽带接入技术的一种。其非对称体现在用户上行和下行的传输速率不相等,一般上行速率较低,下行速率高。这种接入技术适用于有宽带业务需求的家庭用户或者中小型商务用户等。
- FTTx + LAN
其中 FTTx 英文翻译为 Fiber To The X,这里的 X 指任何地方,我们可以理解为光纤可以接入到任何地方,而 LAN 指的是局域网。FTTx + LAN 是一种在接入网全部或部分采用光纤传输介质,构成光纤用户线路,从而实现用户高速上网的接入技术,其中用户速率可达 20 Mbps。这种接入技术投资规模小,网络拓展性强,网络可靠稳定,使得其应用广泛,目前是城市汇总较为普及的一种宽带接入技术。
其它还有 光纤同轴混合网(HFC)、光接入技术(有源和无源光纤系统)和无线接入技术等等。
计算机网络中的安全
网络安全攻击主要分为被动攻击和主动攻击两类:
- 被动攻击:攻击者窃听和监听数据传输,从而获取到传输的数据信息,被动攻击主要有两种形式:消息内容泄露攻击和流量分析攻击。由于攻击者并没有修改数据,使得这种攻击类型是很难被检测到的。
- 主动攻击:攻击者修改传输的数据流或者故意添加错误的数据流,例如假冒用户身份从而得到一些权限,进行权限攻击,除此之外,还有重放、改写和拒绝服务等主动攻击的方式。
ARP 攻击
在 ARP 的解析过程中,局域网上的任何一台主机如果接收到一个 ARP 应答报文,并不会去检测这个报文的真实性,而是直接记入自己的 ARP 缓存表中。并且这个 ARP 表是可以被更改的,当表中的某一列长时间不适使用,就会被删除。ARP 攻击就是利用了这一点,攻击者疯狂发送 ARP 报文,其源 MAC 地址为攻击者的 MAC 地址,而源 IP 地址为被攻击者的 IP 地址。通过不断发送这些伪造的 ARP 报文,让网络内部的所有主机和网关的 ARP 表中被攻击者的 IP 地址所对应的 MAC 地址为攻击者的 MAC 地址。这样所有发送给被攻击者的信息都会发送到攻击者的主机上,从而产生 ARP 欺骗。通常可以把 ARP 欺骗分为以下几种:
- 洪泛攻击
攻击者恶意向局域网中的网关、路由器和交换机等发送大量 ARP 报文,设备的 CPU 忙于处理 ARP 协议,而导致难以响应正常的服务请求。其表现通常为:网络中断或者网速很慢。
- 欺骗主机
这种攻击方式也叫仿冒网关攻击。攻击者通过 ARP 欺骗使得网络内部被攻击主机发送给网关的信息实际上都发送给了攻击者,主机更新的 ARP 表中对应的 MAC 地址为攻击者的 MAC。当用户主机向网关发送重要信息时,该攻击方式使得用户的数据存在被窃取的风险。
- 欺骗网关
该攻击方式和欺骗主机的攻击方式类似,不过这种攻击的欺骗对象是局域网的网关,当局域网中的主机向网关发送数据时,网关会把数据发送给攻击者,这样攻击者就会源源不断地获得局域网中用户的信息。该攻击方式同样会造成用户数据外泄。
- 中间人攻击
攻击者同时欺骗网关和主机,局域网的网关和主机发送的数据最后都会到达攻击者这边。这样,网关和用户的数据就会泄露。
- IP 地址冲突
攻击者对局域网中的主机进行扫描,然后根据物理主机的 MAC 地址进行攻击,导致局域网内的主机产生 IP 冲突,使得用户的网络无法正常使用。
对称加密和非对称的区别,非对称加密有哪些
- 加密和解密的过程不同:对称加密和解密过程使用同一个密钥;非对称加密中加密和解密采用公钥和私钥两个密钥,一般使用公钥进行加密,使用私钥进行解密。
- 加密和解密的速度不同:对称加密和解密速度较快,当数据量比较大时适合使用;非对称加密和解密时间较长,速度相对较慢,适合少量数据传输的场景。
- 传输的安全性不同:采用对称加密方式进行通信时,收发双方在数据传送前需要协定好密钥,而这个密钥还有可能被第三方窃听到的,一旦密钥泄漏,之后的通信就完全暴漏给攻击者了;非对称加密采用公钥加密和私钥解密的方式,其中私钥是基于不同的算法生成的随机数,公钥可以通过私钥通过一定的算法推导得出,并且私钥到公钥的推导过程是不可逆的,也就是说公钥无法反推导出私钥,即使攻击者窃听到传输的公钥,也无法正确解出数据,所以安全性较高。
常见的非对称加密算法主要有:RSA、Elgamal、背包算法、Rabin、D-H 算法等等。
AES 的过程
AES(Advanced Encryption Standard)即密码学的高级加密标准,也叫做 Rijndeal 加密法,是为最为常见的一种对称加密算法,和传统的对称加密算法大致的流程类似,在发送端需要采用加密算法对明文进行加密,在接收端需要采用与加密算法相同的算法进行解密,不同的是, AES 采用分组加密的方式,将明文分成一组一组的,每组长度相等,每次加密一组数据,直到加密完整个明文。在 AES 标准中,分组长度固定为 128 位,即每个分组为 16 个字节(每个字节有 8 位)。而密钥的长度可以是 128 位,192 位或者 256 位。并且密钥的长度不同,推荐加密的轮数也不同。
我们以 128 位密钥为例(加密轮次为 10),已知明文首先需要分组,每一组大小为16个字节并形成 4 × 4 的状态矩阵(矩阵中的每一个元素代表一个字节)。类似地,128 位密钥同样用 4 × 4 的字节矩阵表示,矩阵中的每一列称为 1 个 32 位的比特字。通过密钥编排函数该密钥矩阵被扩展成一个由 44 个字组成的序列,该序列的前四个字是原始密钥,用于 AES 的初始密钥加过程,后面 40 个字分为 10 组,每组 4 个字分别用于 10 轮加密运算中的轮密钥加。在每轮加密过程中主要包括四个步骤:
① 字节代换:AES 的字节代换其实是一个简易的查表操作,在 AES 中定义了一个 S-box 和一个逆 S-box,我们可以将其简单地理解为两个映射表,在做字节代换时,状态矩阵中的每一个元素(字节)的高四位作为行值,低四位作为列值,取出 S-box 或者逆 S-box 中对应的行或者列作为输出。
② 行位移:顾名思义,就是对状态矩阵的每一行进行位移操作,其中状态矩阵的第 0 行左移 0 位,第 1 行左移 1 位,以此类推。
③ 列混合:列混合变换是通过矩阵相乘来实现的,经唯一后的状态矩阵与固定的矩阵相乘,从而得到混淆后的状态矩阵。其中矩阵相乘中涉及到的加法等价于两个字节的异或运算,而乘法相对复杂一些,对于状态矩阵中的每一个 8 位二进制数来说,首先将其与 00000010 相乘,其等效为将 8 位二进制数左移一位,若原二进制数的最高位是 1 的话再将左移后的数与 00011011 进行异或运算。
④ 轮密相加:在开始时我们提到,128 位密钥通过密钥编排函数被扩展成 44 个字组成的序列,其中前 4 个字用于加密过程开始时对原始明文矩阵进行异或运算,而后 40 个字中每四个一组在每一轮中与状态矩阵进行异或运算(共计 10 轮)。
上述过程即为 AES 加密算法的主要流程,在我们的例子中,上述过程需要经过 10 轮迭代。而 AES 的解密过程的各个步骤和加密过程是一样的,只是用逆变换取代原来的变换。
RSA 和 AES 算法有什么区别
- RSA
采用非对称加密的方式,采用公钥进行加密,私钥解密的形式。其私钥长度一般较长,除此之外,由于需要大数的乘幂求模等运算,其运算速度较慢,不适合大量数据文件加密。
- AES
采用对称加密的方式,其密钥长度最长只有 256 个比特,加密和解密速度较快,易于硬件实现。由于是对称加密,通信双方在进行数据传输前需要获知加密密钥。
基于上述两种算法的特点,一般使用 RSA 传输密钥给对方,之后使用 AES 进行加密通信。
DDoS 有哪些,如何防范
DDoS 为分布式拒绝服务攻击,是指处于不同位置的多个攻击者同时向一个或数个目标发动攻击,或者一个攻击者控制了不同位置上的多台机器并利用这些机器对受害者同时实施攻击。和单一的 DoS 攻击相比,DDoS 是借助数百台或者数千台已被入侵并添加了攻击进程的主机一起发起网络攻击。
DDoS 攻击主要有两种形式:流量攻击和资源耗尽攻击。前者主要针对网络带宽,攻击者和已受害主机同时发起大量攻击导致网络带宽被阻塞,从而淹没合法的网络数据包;后者主要针对服务器进行攻击,大量的攻击包会使得服务器资源耗尽或者 CPU 被内核应用程序占满从而无法提供网络服务。
常见的 DDos 攻击主要有:TCP 洪水攻击(SYN Flood)、放射性攻击(DrDos)、CC 攻击(HTTP Flood)等。
针对 DDoS 中的流量攻击,最直接的方法是增加带宽,理论上只要带宽大于攻击流量就可以了,但是这种方法成本非常高。在有充足网络带宽的前提下,我们应尽量提升路由器、网卡、交换机等硬件设施的配置。
针对资源耗尽攻击,我们可以升级主机服务器硬件,在网络带宽得到保证的前提下,使得服务器能有效对抗海量的 SYN 攻击包。我们也可以安装专业的抗 DDoS 防火墙,从而对抗 SYN Flood等流量型攻击。此外,负载均衡,CDN 等技术都能够有效对抗 DDoS 攻击




