参考《算法竞赛进阶指南》 、AcWing题库
线段树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 class SegTree {public : struct Node { int l = 0 , r = 0 ; int sum = 0 ; }; vector<Node> tr; vector<int > a; int n; SegTree () {} SegTree (vector<int > &a) { n = a.size (); this ->a = a; tr.resize (n * 4 + 1 ); build (1 , 1 , n); } void pushup (Node &u, Node &ls, Node &rs) u.sum = ls.sum + rs.sum; } void pushup (int u) pushup (tr[u], tr[u << 1 ], tr[u << 1 | 1 ]); } void build (int u, int l, int r) tr[u] = {l, r}; if (l == r) { tr[u].sum = a[l - 1 ]; return ; } int mid = l + r >> 1 ; build (u << 1 , l, mid); build (u << 1 | 1 , mid + 1 , r); pushup (u); } void modify (int u, int x, int v) if (tr[u].l == tr[u].r) { tr[u].sum = v; return ; } int mid = tr[u].l + tr[u].r >> 1 ; if (x <= mid) modify (u << 1 , x, v); else modify (u << 1 | 1 , x, v); pushup (u); } Node ask (int u, int l, int r) { if (l <= tr[u].l && tr[u].r <= r) return tr[u]; int mid = tr[u].l + tr[u].r >> 1 ; if (r <= mid) return ask (u << 1 , l, r); if (l > mid) return ask (u << 1 | 1 , l, r); Node ans; auto left = ask (u << 1 , l, r); auto right = ask (u << 1 | 1 , l, r); pushup (ans, left, right); return ans; } };
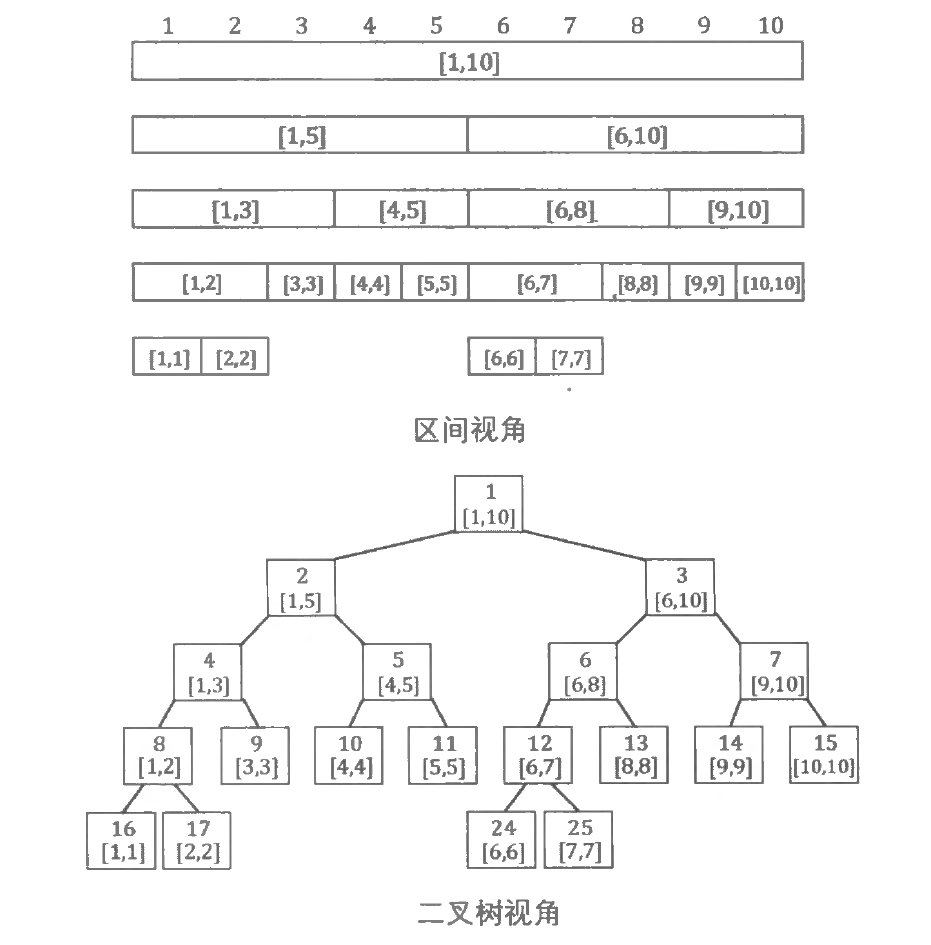
线段树 (Segment Tree) 是一种基于分治思想的二叉树结构, 用于在区间上进行信息统计。与按照二进制位 (2 的次幂) 进行区间划分的树状数组相比, 线段树是一种更加通用的结构:
线段树的每个节点都代表一个区间。
线段树具有唯一的根节点, 代表的区间是整个统计范围, 如 [ 1 , N ] [1, N] [ 1 , N ]
线段树的每个叶节点都代表一个长度为 1 的元区间 [ x , x ] [x, x] [ x , x ]
对于每个内部节点 [ l , r ] [l, r] [ l , r ] [ l , m i d ] [l, m i d] [ l , mi d ] [ m i d + 1 , r ] [m i d+1, r] [ mi d + 1 , r ] m i d = ( l + r ) / 2 mid=(l+r) / 2 mi d = ( l + r ) /2 。
上图展示了一棵线段树。可以发现, 除去树的最后一层, 整棵线段树一定是一棵完O ( log N ) \mathrm{O}(\log N) O ( log N ) “父子 2 倍” 节点编号 方法:
根节点编号为 1 。
编号为 x x x x ∗ 2 或 x < < 1 x * 2 \text{ 或 } x << 1 x ∗ 2 或 x << 1 x ∗ 2 + 1 或 x < < 1 ∣ 1 x * 2+1 \text{ 或 } x << 1 \;| \;1 x ∗ 2 + 1 或 x << 1 ∣ 1
这样一来, 我们就能简单地使用一个 struct 数组来保存线段树。当然, 树的最后一层节点在数组中保存的位置不是连续的, 直接空出数组中多余的位置即可。在理想情况下, N N N N + N / 2 + N / 4 + ⋯ + 2 + 1 = 2 N − 1 N+N / 2+N / 4+\cdots+2+1=2 N-1 N + N /2 + N /4 + ⋯ + 2 + 1 = 2 N − 1 保存线段树的数组长度要不小于 4 N 4 N 4 N 才能保证不会越界。
线段树的建树、pushup操作
线段树的基本用途是对序列进行维护, 支持查询与修改指令。给定一个长度为 N N N A A A [ 1 , N ] [1, N] [ 1 , N ] [ i , i ] [i, i] [ i , i ] A [ i ] A[i] A [ i ] dat ( l , r ) \operatorname{dat}(l, r) dat ( l , r ) max l ≤ i ≤ r { A [ i ] } \max _{l \leq i \leq r}\{A[i]\} max l ≤ i ≤ r { A [ i ]} dat ( l , r ) = max ( dat ( l , mid ) , dat ( mid + 1 , r ) ) \operatorname{dat}(l, \mathrm{r})=\max (\operatorname{dat}(l, \operatorname{mid}), \operatorname{dat}(\operatorname{mid}+1, r)) dat ( l , r ) = max ( dat ( l , mid ) , dat ( mid + 1 , r ))
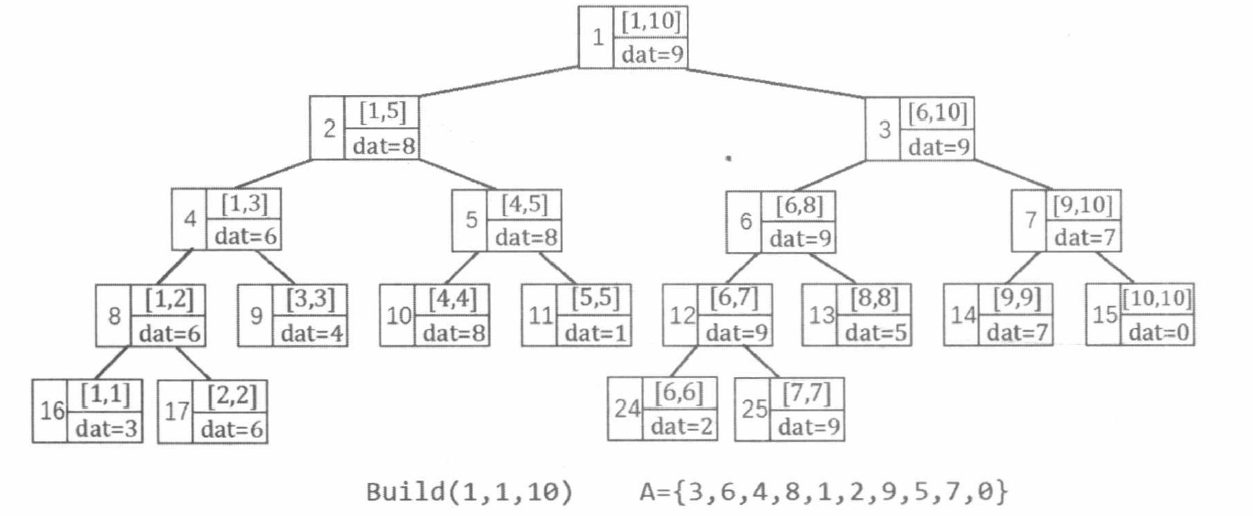
下面这段代码建立了一棵线段树并在每个节点上保存了对应区间的最大值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 struct Node { int l, r; int dat; } tr[SIZE * 4 ]; void pushup (Node &u, Node &l, Node &r) u.dat = max (l.dat, r.dat); } void pushup (int u) pushup (tr[u], tr[u << 1 ], tr[u << 1 | 1 ]); } void build (int u, int l, int r) tr[u] = {l, r}; if (l == r) { tr[u].dat = a[l]; return ; } int mid = l + r >> 1 ; build (u << 1 , l, mid); build (u << 1 | 1 , mid + 1 , r); pushup (u); } build (1 , 1 , n);
线段树的单点修改
单点修改是一条形如 “ C x v \mathrm{C} \;x \;v C x v A [ x ] A[x] A [ x ] v v v
在线段树中, 根节点 (编号为 1 的节点) 是执行各种指令的入口。我们需要从根节 点出发, 递归找到代表区间 [ x , x ] [x, x] [ x , x ] [ x , x ] [x, x] [ x , x ] O ( log N ) O(\log N) O ( log N )
1 2 3 4 5 6 7 8 9 10 11 12 13 void modify (int u, int x, int v) if (tr[u].l == tr[u].r) { tr[u].dat = v; return ; } int mid = tr[u].l + tr[u].r >> 1 ; if (x <= mid) modify (u << 1 , x, v); else modify (u << 1 | 1 , x, v); pushup (u); } change (1 , x, v);
线段树的区间查询
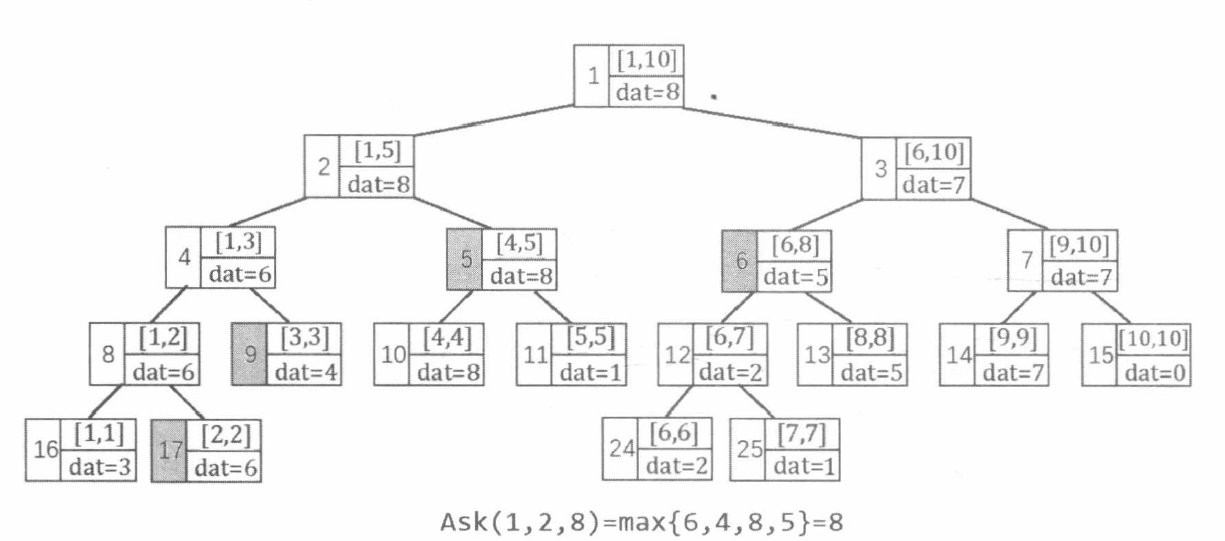
区间查询是一条形如 “ Q l r \mathrm{Q} \;l \;r Q l r A A A [ l , r ] [l, r] [ l , r ] max l ≤ i ≤ r { A [ i ] } \max _{l \leq i \leq r}\{A[i]\} max l ≤ i ≤ r { A [ i ]}
若 [ l , r ] [l, r] [ l , r ] d a t d a t d a t
若左子节点与 [ l , r ] [l, r] [ l , r ]
若右子节点与 [ l , r ] [l, r] [ l , r ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Node ask (int u, int l, int r) { if (l <= tr[u].l && r >= tr[u].r) return tr[u]; int mid = tr[u].l + tr[u].r >> 1 ; if (r <= mid) return ask (u << 1 , l, r); if (l > mid) return ask (u << 1 | 1 , l, r); auto left = ask (u << 1 , l, r); auto right = ask (u << 1 | 1 , l, r); Node ans; pushup (ans, left, right); return ans; }
1 2 3 4 5 6 7 8 9 10 11 int ask (int u, int l, int r) if (l <= tr[u].l && r >= tr[u].r) return tr[u].dat; int mid = tr[u].l + tr[u].r >> 1 ; int val = 0 ; if (l <= mid) val = max (val, ask (u << 1 , l, r)); if (r > mid) val = max (val, ask (u << 1 | 1 , l, r)); return val; } ask (1 , l, r);
该查询过程会把询问区间 [ l , r ] [l, r] [ l , r ] O ( log N ) O(\log N) O ( log N ) , 取它们的最大值作为答案。为什么是 O ( log N ) O(\log N) O ( log N ) [ p l , p r ] \left[p_{l}, p_{r}\right] [ p l , p r ] mid = ( p l + p r ) / 2 \operatorname{mid}=\left(p_{l}+p_{r}\right) / 2 mid = ( p l + p r ) /2
l ≤ p l ≤ p r ≤ r l \leq p_{l} \leq p_{r} \leq r l ≤ p l ≤ p r ≤ r p l ≤ l ≤ p r ≤ r p_{l} \leq l \leq p_{r} \leq r p l ≤ l ≤ p r ≤ r l l l l > m i d l>\mathrm{mid} l > mid l ≤ m i d l \leq m i d l ≤ mi d l ≤ p l ≤ r ≤ p r l \leq p_{l} \leq r \leq p_{r} l ≤ p l ≤ r ≤ p r r r r p l ≤ l ≤ r ≤ p r p_{l} \leq l \leq r \leq p_{r} p l ≤ l ≤ r ≤ p r l l l r r r l , r l, r l , r m i d m i d mi d l , r l, r l , r m i d m i d mi d
也就是说, 只有情况 4(2) 会真正产生对左右两棵子树的递归。请读者思考, 这种 情况至多发生一次, 之后在子节点上就会变成情况 2 或 3 。因此, 上述查询过程的时间复杂度为 O ( 2 log N ) = O ( log N ) O(2 \log N)=O(\log N) O ( 2 log N ) = O ( log N ) l , r l, r l , r
至此, 线段树已经能够像 倍增 节的 ST 算法一样处理区间最值问题, 并且还支持 动态修改某个数的值。同时, 线段树也已经能支持上一节中树状数组的单点增加与查询前缀和指令。在讨论区间修改之前, 我们先来通过几道例题加深对线段树的印象。
例题
给定一个正整数数列 a 1 , a 2 , … , a n a_1,a_2,…,a_n a 1 , a 2 , … , a n 0 ∼ p − 1 0 \sim p-1 0 ∼ p − 1
可以对这列数进行两种操作:
添加操作:向序列后添加一个数,序列长度变成 n + 1 n+1 n + 1
询问操作:询问这个序列中最后 L L L
程序运行的最开始,整数序列为空。
一共要对整数序列进行 m m m
写一个程序,读入操作的序列,并输出询问操作的答案。
输入格式
第一行有两个正整数 m , p m,p m , p
接下来 m m m
如果该行的内容是 Q L,则表示这个操作是询问序列中最后 L L L
如果是 A t,则表示向序列后面加一个数,加入的数是 ( t + a ) m o d p (t+a)\ mod\ p ( t + a ) m o d p t t t a a a a = 0 a=0 a = 0
第一个操作一定是添加操作。对于询问操作,L > 0 L>0 L > 0
输出格式
对于每一个询问操作,输出一行。该行只有一个数,即序列中最后 L L L
数据范围
1 ≤ m ≤ 2 × 1 0 5 1 \le m \le 2 \times 10^5 1 ≤ m ≤ 2 × 1 0 5 1 ≤ p ≤ 2 × 1 0 9 1 \le p \le 2 \times 10^9 1 ≤ p ≤ 2 × 1 0 9 0 ≤ t < p 0 \le t < p 0 ≤ t < p
输入样例:
1 2 3 4 5 6 7 8 9 10 11 10 100 A 97 Q 1 Q 1 A 17 Q 2 A 63 Q 1 Q 1 Q 3 A 99
输出样例:
样例解释
最后的序列是 97 , 14 , 60 , 96 97,14,60,96 97 , 14 , 60 , 96
算法分析
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <iostream> using namespace std;using LL = long long ;const int N = 2e5 + 10 ;int m, p;struct Node { int l, r; int dat; } tr[N * 4 ]; void pushup (int u) tr[u].dat = max (tr[u << 1 ].dat, tr[u << 1 | 1 ].dat); } void build (int u, int l, int r) tr[u] = {l, r}; if (l == r) return ; int mid = l + r >> 1 ; build (u << 1 , l, mid); build (u << 1 | 1 , mid + 1 , r); } int ask (int u, int l, int r) if (l <= tr[u].l && r >= tr[u].r) return tr[u].dat; int mid = tr[u].l + tr[u].r >> 1 ; int val = 0 ; if (l <= mid) val = ask (u << 1 , l, r); if (r > mid) val = max (val, ask (u << 1 | 1 , l, r)); return val; } void modify (int u, int x, int v) if (tr[u].l == tr[u].r) { tr[u].dat = v; } else { int mid = tr[u].l + tr[u].r >> 1 ; if (x <= mid) modify (u << 1 , x, v); else modify (u << 1 | 1 , x, v); pushup (u); } } int main () int n = 0 , last = 0 ; cin >> m >> p; build (1 , 1 , m); int x; char op; while (m--) { cin >> op >> x; if (op == 'Q' ) { last = ask (1 , n - x + 1 , n); cout << last << endl; } else { modify (1 , ++n, ((LL)last + x) % p); } } }
给定长度为 N N N A A A M M M
1 x y,查询区间 [ x , y ] [x,y] [ x , y ] max x ≤ l ≤ r ≤ y \max_{x \le l \le r \le y} max x ≤ l ≤ r ≤ y ∑ i = l r A [ i ] \sum\limits^r_{i=l} A[i] i = l ∑ r A [ i ] 2 x y,把 A [ x ] A[x] A [ x ] y y y
对于每个查询指令,输出一个整数表示答案。
输入格式
第一行两个整数 N , M N,M N , M
第二行 N N N A [ i ] A[i] A [ i ]
接下来 M M M 3 3 3 k , x , y k,x,y k , x , y k = 1 k=1 k = 1 x > y x>y x > y x , y x,y x , y k = 2 k=2 k = 2
输出格式
对于每个查询指令输出一个整数表示答案。
每个答案占一行。
数据范围
N ≤ 500000 , M ≤ 100000 N \le 500000, M \le 100000 N ≤ 500000 , M ≤ 100000 − 1000 ≤ A [ i ] ≤ 1000 -1000 \le A[i] \le 1000 − 1000 ≤ A [ i ] ≤ 1000
输入样例:
1 2 3 4 5 5 3 1 2 -3 4 5 1 2 3 2 2 -1 1 3 2
输出样例:
算法分析
在线段树上的每个节点上, 除了区间端点外, 再维护 4 个信息: 区间和 sum, 区 间最大连续子段和 dat, 紧靠左端的最大连续子段和 1 m a x 1 \mathrm{max} 1 max
1 2 3 4 t[p].sum = t[2 * p].sum + t[2 * p + 1 ].sum; t[p].lmax = max (t[2 * p].lmax, t[2 * p].sum + t[2 * p + 1 ].lmax); t[p].rmax = max (t[2 * p + 1 ].rmax, t[2 * p + 1 ].sum + t[2 * p].rmax); t[p].dat = max ({t[2 * p].dat, t[2 * p + 1 ].dat, t[2 * p].rmax + t[2 * p + 1 ].lmax});
从这道题目我们也可以看出, 线段树作为一种比较通用的数据结构, 能够维护各式各样的信息, 前提是这些信息容易按照区间进行划分与合并 (又称满足区间可加性)。 我们只需要在父子传递信息和更新答案时稍作变化即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include <cstdio> #include <iostream> #include <algorithm> using namespace std;const int N = 500006 , INF = 0x3f3f3f3f ;int n, m, a[N];struct T { int l, r, s, lx, rx, ans; } t[N*4 ]; void build (int p, int l, int r) t[p].l = l; t[p].r = r; if (l == r) { t[p].s = t[p].lx = t[p].rx = t[p].ans = a[l]; return ; } int mid = (l + r) >> 1 ; build (p << 1 , l, mid); build (p << 1 | 1 , mid + 1 , r); t[p].s = t[p<<1 ].s + t[p<<1 |1 ].s; t[p].lx = max (t[p<<1 ].lx, t[p<<1 ].s + t[p<<1 |1 ].lx); t[p].rx = max (t[p<<1 |1 ].rx, t[p<<1 ].rx + t[p<<1 |1 ].s); t[p].ans = max (max (t[p<<1 ].ans, t[p<<1 |1 ].ans), t[p<<1 ].rx + t[p<<1 |1 ].lx); } void change (int p, int x, int y) if (t[p].l == t[p].r) { t[p].s = t[p].lx = t[p].rx = t[p].ans = y; return ; } int mid = (t[p].l + t[p].r) >> 1 ; if (x <= mid) change (p << 1 , x, y); else change (p << 1 | 1 , x, y); t[p].s = t[p<<1 ].s + t[p<<1 |1 ].s; t[p].lx = max (t[p<<1 ].lx, t[p<<1 ].s + t[p<<1 |1 ].lx); t[p].rx = max (t[p<<1 |1 ].rx, t[p<<1 ].rx + t[p<<1 |1 ].s); t[p].ans = max (max (t[p<<1 ].ans, t[p<<1 |1 ].ans), t[p<<1 ].rx + t[p<<1 |1 ].lx); } T ask (int p, int l, int r) { if (l <= t[p].l && r >= t[p].r) return t[p]; T a, b, ans; a.s = a.lx = a.rx = a.ans = b.s = b.lx = b.rx = b.ans = -INF; ans.s = 0 ; int mid = (t[p].l + t[p].r) >> 1 ; if (l <= mid) { a = ask (p << 1 , l, r); ans.s += a.s; } if (r > mid) { b = ask (p << 1 | 1 , l, r); ans.s += b.s; } ans.ans = max (max (a.ans, b.ans), a.rx + b.lx); ans.lx = max (a.lx, a.s + b.lx); ans.rx = max (b.rx, b.s + a.rx); if (l > mid) ans.lx = max (ans.lx, b.lx); if (r <= mid) ans.rx = max (ans.rx, a.rx); return ans; } int main () cin >> n >> m; for (int i = 1 ; i <= n; i++) scanf ("%d" , &a[i]); build (1 , 1 , n); while (m--) { int t, x, y; scanf ("%d %d %d" , &t, &x, &y); if (t == 1 ) { if (x > y) swap (x, y); cout << ask (1 , x, y).ans << endl; } else change (1 , x, y); } return 0 ; }
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 #include <iostream> #include <algorithm> using namespace std;const int N = 5e5 + 10 ;int n, m;int a[N];struct Node { int l, r; int tsum; int lmax, rmax; int sum; } tr[4 * N]; void pushup (Node &u, Node &l, Node &r) u.sum = l.sum + r.sum; u.lmax = max (l.lmax, l.sum + r.lmax); u.rmax = max (r.rmax, r.sum + l.rmax); u.tsum = max ({l.tsum, r.tsum, l.rmax + r.lmax}); } void pushup (int u) pushup (tr[u], tr[u << 1 ], tr[u << 1 | 1 ]); } void build (int u, int l, int r) tr[u] = {l, r}; if (l == r) { tr[u] = {l, r, a[l], a[l], a[l], a[l]}; return ; } int mid = l + r >> 1 ; build (u << 1 , l, mid); build (u << 1 | 1 , mid + 1 , r); pushup (u); } void modify (int u, int x, int v) if (tr[u].l == tr[u].r) { tr[u] = {x, x, v, v, v, v}; return ; } int mid = tr[u].l + tr[u].r >> 1 ; if (x <= mid) modify (u << 1 , x, v); else modify (u << 1 | 1 , x, v); pushup (u); } Node ask (int u, int l, int r) { if (l <= tr[u].l && r >= tr[u].r) return tr[u]; int mid = tr[u].l + tr[u].r >> 1 ; if (r <= mid) return ask (u << 1 , l, r); if (l > mid) return ask (u << 1 | 1 , l, r); auto left = ask (u << 1 , l, r); auto right = ask (u << 1 | 1 , l, r); Node ans; pushup (ans, left, right); return ans; } int main () cin.tie (0 ); ios::sync_with_stdio (false ); cin >> n >> m; for (int i = 1 ; i <= n; ++i) cin >> a[i]; build (1 , 1 , n); int k, x, y; while (m--) { cin >> k >> x >> y; if (k == 1 ) { if (x > y) swap (x, y); cout << ask (1 , x, y).tsum << endl; } else { modify (1 , x, y); } } }
给定一个长度为 N N N A A A M M M
C l r d,表示把 A [ l ] , A [ l + 1 ] , … , A [ r ] A[l],A[l+1],…,A[r] A [ l ] , A [ l + 1 ] , … , A [ r ] d d d Q l r,表示询问 A [ l ] , A [ l + 1 ] , … , A [ r ] A[l],A[l+1],…,A[r] A [ l ] , A [ l + 1 ] , … , A [ r ] G C D GCD GC D
对于每个询问,输出一个整数表示答案。
输入格式
第一行两个整数 N , M N,M N , M
第二行 N N N A [ i ] A[i] A [ i ]
接下来 M M M M M M
输出格式
对于每个询问,输出一个整数表示答案。
每个答案占一行。
数据范围
N ≤ 500000 , M ≤ 100000 N \le 500000, M \le 100000 N ≤ 500000 , M ≤ 100000 1 ≤ A [ i ] ≤ 1 0 18 1 \le A[i] \le 10^{18} 1 ≤ A [ i ] ≤ 1 0 18 ∣ d ∣ ≤ 1 0 18 |d| \le 10^{18} ∣ d ∣ ≤ 1 0 18
输入样例:
1 2 3 4 5 6 7 5 5 1 3 5 7 9 Q 1 5 C 1 5 1 Q 1 5 C 3 3 6 Q 2 4
输出样例:
算法分析
根据 “《九章算术》之更相减损术” , 我们知道 gcd ( x , y ) = gcd ( x , y − x ) \operatorname{gcd}(x, y)=\operatorname{gcd}(x, y-x) gcd ( x , y ) = gcd ( x , y − x ) gcd ( x , y , z ) = gcd ( x , y − x , z − y ) \operatorname{gcd}(x, y, z)=\operatorname{gcd}(x, y-x, z-y) gcd ( x , y , z ) = gcd ( x , y − x , z − y )
因此, 我们可以构造一个长度为 N N N B B B B [ i ] = A [ i ] − A [ i − 1 ] , B [ 1 ] B[i]=A[i]-A[i-1], B[1] B [ i ] = A [ i ] − A [ i − 1 ] , B [ 1 ] B B B A A A 差分序列 。用线段树维护序列 B B B
这样一来, 询问 “ Q l r \mathrm{Q} \;l \;r Q l r gcd ( A [ l ] , ask ( 1 , l + 1 , r ) ) \operatorname{gcd}(A[l], \operatorname{ask}(1, l+1, r)) gcd ( A [ l ] , ask ( 1 , l + 1 , r ))
在指令 “ C l r d \mathrm{C} \;l \;r \;d C l r d B [ l ] B[l] B [ l ] d , B [ r + 1 ] d, B[r+1] d , B [ r + 1 ] d d d B B B A A A A A A
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 #include <cmath> #include <cstring> #include <iostream> #define ll long long using namespace std;const int N = 500006 ;int n, m;ll a[N], b[N], c[N]; struct T { int l, r; ll ans; } t[N*4 ]; ll gcd (ll x, ll y) { return y ? gcd (y, x % y) : x; } void build (int p, int l, int r) t[p].l = l; t[p].r = r; if (l == r) { t[p].ans = b[l]; return ; } int mid = (l + r) >> 1 ; build (p << 1 , l, mid); build (p << 1 | 1 , mid + 1 , r); t[p].ans = gcd (t[p<<1 ].ans, t[p<<1 |1 ].ans); } void change_add (int p, int x, ll v) if (t[p].l == t[p].r) { t[p].ans += v; return ; } int mid = (t[p].l + t[p].r) >> 1 ; if (x <= mid) change_add (p << 1 , x, v); else change_add (p << 1 | 1 , x, v); t[p].ans = gcd (t[p<<1 ].ans, t[p<<1 |1 ].ans); } ll ask_t (int p, int l, int r) { if (l <= t[p].l && r >= t[p].r) return t[p].ans; int mid = (t[p].l + t[p].r) >> 1 ; ll ans = 0 ; if (l <= mid) ans = gcd (ans, ask_t (p << 1 , l, r)); if (r > mid) ans = gcd (ans, ask_t (p << 1 | 1 , l, r)); return abs (ans); } void add (int x, ll y) while (x <= n) { c[x] += y; x += x & -x; } } ll ask_c (int x) { ll ans = 0 ; while (x) { ans += c[x]; x -= x & -x; } return ans; } int main () cin >> n >> m; b[0 ] = 0 ; memset (c, 0 , sizeof for (int i = 1 ; i <= n; i++) { cin >> a[i]; b[i] = a[i] - a[i-1 ]; } build (1 , 1 , n); while (m--) { char ch; cin >> ch; int l, r; cin >> l >> r; if (ch == 'C' ) { ll d; cin >> d; change_add (1 , l, d); add (l, d); if (r + 1 <= n) { change_add (1 , r + 1 , -d); add (r + 1 , -d); } } else cout << gcd (a[l] + ask_c (l), ask_t (1 , l + 1 , r)) << endl; } return 0 ; }
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <iostream> using namespace std;using LL = long long ;const int N = 500010 ;int n, m;LL a[N]; struct Node { int l, r; LL val; LL sum, d; } tr[4 * N]; LL gcd (LL a, LL b) { return b ? gcd (b, a % b) : a; } void pushup (Node &u, Node &l, Node &r) u.sum = l.sum + r.sum; u.d = gcd (l.d, r.d); } void pushup (int u) pushup (tr[u], tr[u << 1 ], tr[u << 1 | 1 ]); } void build (int u, int l, int r) tr[u] = {l, r}; if (l == r) { LL b = a[r] - a[r - 1 ]; tr[u] = {l, r, b, b, b}; return ; } int mid = l + r >> 1 ; build (u << 1 , l, mid); build (u << 1 | 1 , mid + 1 , r); pushup (u); } void modify (int u, int x, LL v) if (tr[u].l == tr[u].r) { LL t = tr[u].val + v; tr[u] = {x, x, t, t, t}; return ; } int mid = tr[u].l + tr[u].r >> 1 ; if (x <= mid) modify (u << 1 , x, v); else modify (u << 1 | 1 , x, v); pushup (u); } Node ask (int u, int l, int r) { if (l <= tr[u].l && r >= tr[u].r) return tr[u]; int mid = tr[u].l + tr[u].r >> 1 ; if (r <= mid) return ask (u << 1 , l, r); if (l > mid) return ask (u << 1 | 1 , l, r); auto left = ask (u << 1 , l, r); auto right = ask (u << 1 | 1 , l, r); Node ans; pushup (ans, left, right); return ans; } int main () cin.tie (0 ); ios::sync_with_stdio (false ); cin >> n >> m; for (int i = 1 ; i <= n; ++i) cin >> a[i]; build (1 , 1 , n); char op; int l, r; while (m--) { cin >> op >> l >> r; if (op == 'C' ) { LL d; cin >> d; modify (1 , l, d); if (r + 1 <= n) modify (1 , r + 1 , -d); } else { auto left = ask (1 , 1 , l); Node right ({0 , 0 , 0 , 0 , 0 }) ; if (l + 1 <= r) right = ask (1 , l + 1 , r); cout << abs (gcd (left.sum, right.d)) << endl; } } }
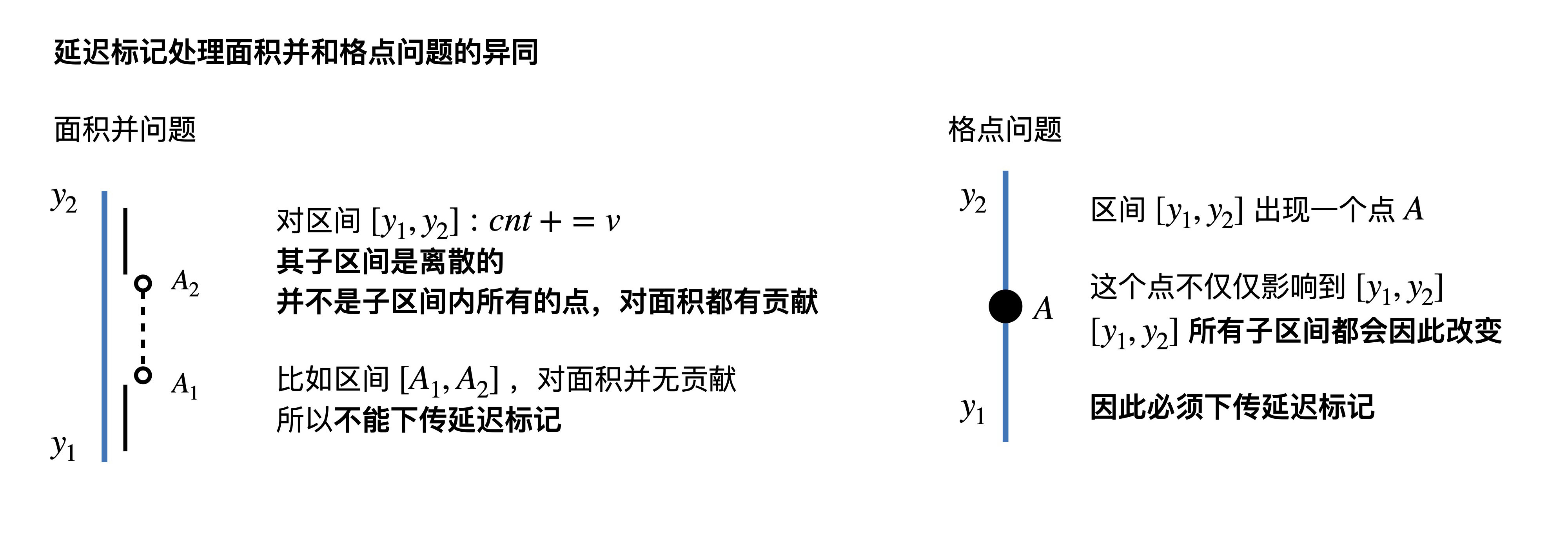
区间修改延迟标记、pushdown操作
在线段树的 “区间查询” 指令中, 每当遇到被询问区间 [ l , r ] [l, r] [ l , r ] [ l , r ] [l, r] [ l , r ] O ( log N ) O(\log N) O ( log N ) O ( log N ) O(\log N) O ( log N ) [ l , r ] [l, r] [ l , r ] O ( N ) O(N) O ( N )
试想, 如果我们在一次修改指令中发现节点 p p p [ p l , p r ] \left[p_{l}, p_{r}\right] [ p l , p r ] [ l , r ] [l, r] [ l , r ] p p p [ l , r ] [l, r] [ l , r ] p p p
换言之, 我们在执行修改指令时, 同样可以在 l ≤ p l ≤ p r ≤ r l \leq p_{l} \leq p_{r} \leq r l ≤ p l ≤ p r ≤ r p p p 该节点曾经被修改, 但其子节点尚未被更新 ”。
如果在后续的指令中, 需要从节点 p p p , 我们再检查 p p p p p p p p p p p p
也就是说, 除了在修改指令中直接划分成的 O ( log N ) O(\log N) O ( log N ) O ( log N ) O(\log N) O ( log N )
有一种称为 “标记永久化” 的技巧, 可以不下传标记, 而是在查询时累计递归经过的所有标记产生的影 响。这种做法局限性非常大, 对线段树维护的信息和标记的性质有特殊要求, 仅在二维线段树和可持久化 线段树难以下传标记的情况下有所应用, 超出了我们的讨论范围。
给定一个长度为 N N N A A A M M M
C l r d,表示把 A [ l ] , A [ l + 1 ] , … , A [ r ] A[l],A[l+1],…,A[r] A [ l ] , A [ l + 1 ] , … , A [ r ] d d d Q l r,表示询问数列中第 l ∼ r l \sim r l ∼ r
对于每个询问,输出一个整数表示答案。
输入格式
第一行两个整数 N , M N,M N , M
第二行 N N N A [ i ] A[i] A [ i ]
接下来 M M M M M M
输出格式
对于每个询问,输出一个整数表示答案。
每个答案占一行。
数据范围
1 ≤ N , M ≤ 1 0 5 1 \le N,M \le 10^5 1 ≤ N , M ≤ 1 0 5 ∣ d ∣ ≤ 10000 |d| \le 10000 ∣ d ∣ ≤ 10000 ∣ A [ i ] ∣ ≤ 1 0 9 |A[i]| \le 10^9 ∣ A [ i ] ∣ ≤ 1 0 9
输入样例:
1 2 3 4 5 6 7 10 5 1 2 3 4 5 6 7 8 9 10 Q 4 4 Q 1 10 Q 2 4 C 3 6 3 Q 2 4
输出样例:
算法分析
在上一节中我们用树状数组解决了该问题, 本节我们改用线段树来求解。除了左右端点 l , r l, r l , r s u m sum s u m a d d a d d a dd s p r e a d spread s p re a d
需要指出的是, 延迟标记的含义为 “该节点曾经被修改, 但其子节点尚未被更新”, 即延迟标记标识的是子节点等待更新的情况 。因此,一个节点被打上 “延迟标记” 的同时, 它自身保存的信息应该已经被修改完毕。读者在编写代码时, 一定要注意 “更新信息”与 “打标记” 之间的关系, 避免出现错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 #include <algorithm> #include <cstdio> #include <cstring> #include <iostream> using namespace std;const int SIZE = 100010 ;struct SegmentTree { int l, r; long long sum, add; #define l(x) tree[x].l #define r(x) tree[x].r #define sum(x) tree[x].sum #define add(x) tree[x].add } tree[SIZE * 4 ]; int a[SIZE], n, m;void build (int p, int l, int r) l (p) = l, r (p) = r; if (l == r) { sum (p) = a[l]; return ; } int mid = (l + r) / 2 ; build (p * 2 , l, mid); build (p * 2 + 1 , mid + 1 , r); sum (p) = sum (p * 2 ) + sum (p * 2 + 1 ); } void spread (int p) if (add (p)) { sum (p * 2 ) += add (p) * (r (p * 2 ) - l (p * 2 ) + 1 ); sum (p * 2 + 1 ) += add (p) * (r (p * 2 + 1 ) - l (p * 2 + 1 ) + 1 ); add (p * 2 ) += add (p); add (p * 2 + 1 ) += add (p); add (p) = 0 ; } } void change (int p, int l, int r, int z) if (l <= l (p) && r >= r (p)) { sum (p) += (long long )z * (r (p) - l (p) + 1 ); add (p) += z; return ; } spread (p); int mid = (l (p) + r (p)) / 2 ; if (l <= mid) change (p * 2 , l, r, z); if (r > mid) change (p * 2 + 1 , l, r, z); sum (p) = sum (p * 2 ) + sum (p * 2 + 1 ); } long long ask (int p, int l, int r) if (l <= l (p) && r >= r (p)) return sum (p); spread (p); int mid = (l (p) + r (p)) / 2 ; long long ans = 0 ; if (l <= mid) ans += ask (p * 2 , l, r); if (r > mid) ans += ask (p * 2 + 1 , l, r); return ans; } int main () cin >> n >> m; for (int i = 1 ; i <= n; i++) scanf ("%d" , &a[i]); build (1 , 1 , n); while (m--) { char op[2 ]; int x, y, z; scanf ("%s%d%d" , op, &x, &y); if (op[0 ] == 'C' ) { scanf ("%d" , &z); change (1 , x, y, z); } else printf ("%I64d\n" , ask (1 , x, y)); } }
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #include <iostream> using namespace std;using LL = long long ;const int N = 1e5 + 10 ;int n, m;LL a[N]; struct Node { int l, r; LL sum, add; } tr[4 * N]; void pushup (Node &u, Node &l, Node &r) u.sum = l.sum + r.sum; } void pushup (int u) pushup (tr[u], tr[u << 1 ], tr[u << 1 | 1 ]); } void pushdown (int u) auto &root = tr[u], &l = tr[u << 1 ], &r = tr[u << 1 | 1 ]; if (root.add) { l.add += root.add; l.sum += (LL)(l.r - l.l + 1 ) * root.add; r.add += root.add; r.sum += (LL)(r.r - r.l + 1 ) * root.add; root.add = 0 ; } } void build (int u, int l, int r) if (l == r) { tr[u] = {l, r, a[l], 0 }; return ; } tr[u] = {l ,r}; int mid = l + r >> 1 ; build (u << 1 , l , mid); build (u << 1 | 1 , mid + 1 , r); pushup (u); } void modify_add (int u, int l, int r, int d) if (l <= tr[u].l && tr[u].r <= r) { tr[u].sum += (LL)(tr[u].r - tr[u].l + 1 ) * d; tr[u].add += d; return ; } pushdown (u); int mid = tr[u].l + tr[u].r >> 1 ; if (l <= mid) modify_add (u << 1 , l, r, d); if (r > mid) modify_add (u << 1 | 1 , l, r ,d); pushup (u); } LL ask (int u, int l, int r) { if (l <= tr[u].l && tr[u].r <= r) return tr[u].sum; pushdown (u); int mid = tr[u].l + tr[u].r >> 1 ; LL sum = 0 ; if (l <= mid) sum += ask (u << 1 , l, r); if (r > mid) sum += ask (u << 1 | 1 , l, r); return sum; } int main () cin >> n >> m; for (int i = 1 ; i <= n; ++i) cin >> a[i]; build (1 , 1 , n); char op; int l, r, d; while (m--) { cin >> op >> l >> r; if (op == 'C' ) { cin >> d; modify_add (1 , l, r, d); } else { cout << ask (1 , l, r) << endl; } } }
老师交给小可可一个维护数列的任务,现在小可可希望你来帮他完成。
有长为 N N N a 1 , a 2 , … , a N a_1,a_2,…,a_N a 1 , a 2 , … , a N
有如下三种操作形式:
把数列中的一段数全部乘一个值;
把数列中的一段数全部加一个值;
询问数列中的一段数的和,由于答案可能很大,你只需输出这个数模 P P P
输入格式
第一行两个整数 N N N P P P
第二行含有 N N N a 1 , a 2 , … , a N a_1,a_2,…,a_N a 1 , a 2 , … , a N
第三行有一个整数 M M M
从第四行开始每行描述一个操作,输入的操作有以下三种形式:
操作 1 1 1 1 t g c,表示把所有满足 t ≤ i ≤ g t \le i \le g t ≤ i ≤ g a i a_i a i a i × c a_i \times c a i × c
操作 2 2 2 2 t g c,表示把所有满足 t ≤ i ≤ g t \le i \le g t ≤ i ≤ g a i a_i a i a i + c a_i + c a i + c
操作 3 3 3 3 t g,询问所有满足 t ≤ i ≤ g t \le i \le g t ≤ i ≤ g a i a_i a i P P P
同一行相邻两数之间用一个空格隔开,每行开头和末尾没有多余空格。
输出格式
对每个操作 3 3 3
数据范围
1 ≤ N , M ≤ 1 0 5 1 \le N,M \le 10^5 1 ≤ N , M ≤ 1 0 5 1 ≤ t ≤ g ≤ N 1 \le t \le g \le N 1 ≤ t ≤ g ≤ N 0 ≤ c , a i ≤ 1 0 9 0 \le c,a_i \le 10^9 0 ≤ c , a i ≤ 1 0 9 1 ≤ P ≤ 1 0 9 1 \le P \le 10^9 1 ≤ P ≤ 1 0 9
输入样例:
1 2 3 4 5 6 7 8 7 43 1 2 3 4 5 6 7 5 1 2 5 5 3 2 4 2 3 7 9 3 1 3 3 4 7
输出样例:
样例解释
初始时数列为 { 1 , 2 , 3 , 4 , 5 , 6 , 7 } \lbrace 1,2,3,4,5,6,7 \rbrace { 1 , 2 , 3 , 4 , 5 , 6 , 7 }
经过第 1 1 1 { 1 , 10 , 15 , 20 , 25 , 6 , 7 } \lbrace 1,10,15,20,25,6,7 \rbrace { 1 , 10 , 15 , 20 , 25 , 6 , 7 }
对第 2 2 2 10 + 15 + 20 = 45 10+15+20=45 10 + 15 + 20 = 45 43 43 43 2 2 2
经过第 3 3 3 { 1 , 10 , 24 , 29 , 34 , 15 , 16 } \lbrace 1,10,24,29,34,15,16 \rbrace { 1 , 10 , 24 , 29 , 34 , 15 , 16 }
对第 4 4 4 1 + 10 + 24 = 35 1+10+24=35 1 + 10 + 24 = 35 43 43 43 35 35 35
对第 5 5 5 29 + 34 + 15 + 16 = 94 29+34+15+16=94 29 + 34 + 15 + 16 = 94 43 43 43 8 8 8
算法分析
1.区间修改 - 乘 加
存储信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 对于x 若对懒标记的处理是先加再乘 若此次操作为乘上一个数c 可以表示为 (n + add) * mul * c 即 (n + X) * X 的形式 若此次操作为加上一个数c (n + add) * mul + c 不能写成 (n + X ) * X的形式 -> 无法更新新的懒标记 若对懒标记的处理是先乘再加 若此次操作是加上一个数c 可以表示为n * mul + add + c -> 此时新的add即为add + c 若此次操作是乘上一个数c 可以表示为n * mul * c + add * c -> 此时新的add即为add * c,新的mul即为mul * c -> 故先乘再加,以便更新懒标记 可以把乘和加的操作都看成 x * c + d -> 若是乘法,d为0 -> 若是加法,c为1 若当前x的懒标记为add和mul -> 操作可以写成(x * mul + add) * c + d -> 即x * (mul * c) + (add * c + d) -> 新的mul为(mul * c),新的add为(add * c + d) 注意:乘的懒标记初始为1
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 #include <iostream> using namespace std;using LL = long long ;const int N = 1e5 + 10 ;int n, p, m;int a[N];struct Node { int l, r; LL sum = 0 , mul = 1 , add = 0 ; } tr[N * 4 ]; void pushup (Node &u, Node &ls, Node &rs) u.sum = (ls.sum + rs.sum) % p; } void pushup (int u) pushup (tr[u], tr[u << 1 ], tr[u << 1 | 1 ]); } void calc (Node& u, int mul, int add) u.sum = (u.sum * mul + 1LL * (u.r - u.l + 1 ) * add) % p; u.mul = u.mul * mul % p; u.add = (u.add * mul + add) % p; } void pushdown (Node &u, Node &ls, Node &rs) calc (ls, u.mul, u.add); calc (rs, u.mul, u.add); u.add = 0 ; u.mul = 1 ; } void pushdown (int u) pushdown (tr[u], tr[u << 1 ], tr[u << 1 | 1 ]); } void build (int u, int l, int r) if (l == r) { tr[u] = {l, r, a[l], 1 , 0 }; return ; } tr[u] = {l, r}; int mid = l + r >> 1 ; build (u << 1 , l, mid); build (u << 1 | 1 , mid + 1 , r); pushup (u); } void modify (int u, int l, int r, int mul, int add) if (l <= tr[u].l && tr[u].r <= r) { calc (tr[u], mul, add); return ; } pushdown (u); int mid = tr[u].l + tr[u].r >> 1 ; if (l <= mid) modify (u << 1 , l, r, mul, add); if (r > mid) modify (u << 1 | 1 , l, r, mul, add); pushup (u); } int ask (int u, int l, int r) if (l <= tr[u].l && tr[u].r <= r) return tr[u].sum; pushdown (u); int mid = tr[u].l + tr[u].r >> 1 ; LL sum = 0 ; if (l <= mid) sum += ask (u << 1 , l, r); if (r > mid) sum += ask (u << 1 | 1 , l, r); return sum % p; } int main () cin.tie (0 ); ios::sync_with_stdio (false ); cin >> n >> p; for (int i = 1 ; i <= n; ++i) cin >> a[i]; build (1 , 1 , n); cin >> m; while (m--) { int op, l, r, c; cin >> op >> l >> r; if (op == 1 ) { cin >> c; modify (1 , l, r, c, 0 ); } else if (op == 2 ) { cin >> c; modify (1 , l, r, 1 , c); } else { cout << ask (1 , l, r) << endl; } } }
扫描线
有几个古希腊书籍中包含了对传说中的亚特兰蒂斯岛的描述。
其中一些甚至包括岛屿部分地图。
但不幸的是,这些地图描述了亚特兰蒂斯的不同区域。
您的朋友 Bill 必须知道地图的总面积。
你自告奋勇写了一个计算这个总面积的程序。
输入格式
输入包含多组测试用例。
对于每组测试用例,第一行包含整数 n n n
接下来 n n n x 1 , y 1 , x 2 , y 2 x_1,y_1,x_2,y_2 x 1 , y 1 , x 2 , y 2 ( x 1 , y 1 ) (x_1,y_1) ( x 1 , y 1 ) ( x 2 , y 2 ) (x_2,y_2) ( x 2 , y 2 )
注意,坐标轴 x x x y y y
当输入用例 n = 0 n=0 n = 0
输出格式
每组测试用例输出两行。
第一行输出 Test case #k,其中 k k k 1 1 1
第二行输出 Total explored area: a,其中 a a a
在每个测试用例后输出一个空行。
数据范围
1 ≤ n ≤ 10000 1 \le n \le 10000 1 ≤ n ≤ 10000 0 ≤ x 1 < x 2 ≤ 100000 0 \le x_1 < x_2 \le 100000 0 ≤ x 1 < x 2 ≤ 100000 0 ≤ y 1 < y 2 ≤ 100000 0 \le y_1 < y_2 \le 100000 0 ≤ y 1 < y 2 ≤ 100000 n n n 10000 10000 10000
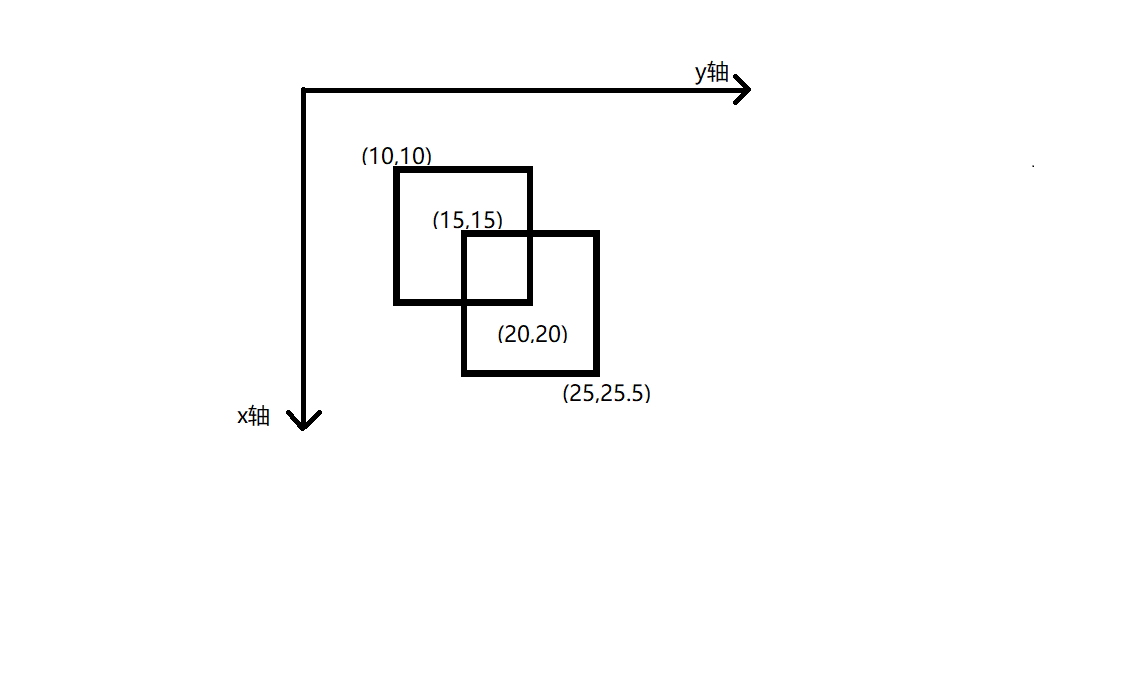
输入样例:
1 2 3 4 2 10 10 20 20 15 15 25 25.5 0
输出样例:
1 2 Test case #1 Total explored area: 180.00
样例解释
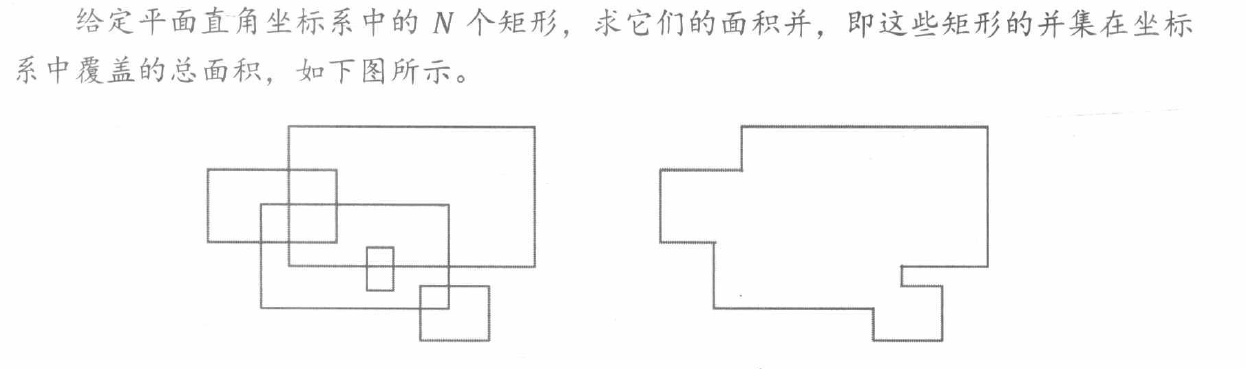
样例所示地图覆盖区域如下图所示,两个矩形区域所覆盖的总面积,即为样例的解。
算法分析
试想, 如果我们用一条坚直直线从左到右扫过整个坐标系, 那么直线上被并集图形覆盖的长度只会在每个矩形的左右边界处发生变化。
换言之, 整个并集图形可以被分成 2 ∗ N 2 * N 2 ∗ N L L L L ∗ W L*W L ∗ W W W W
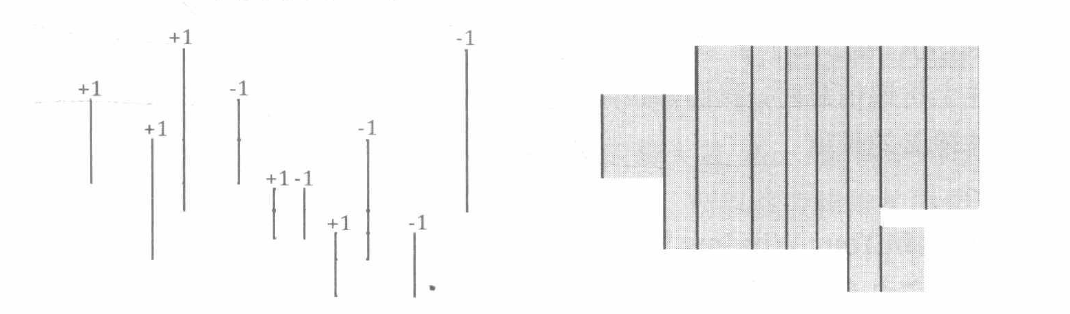
具体来说, 我们可以取出 N N N ( x 1 , y 1 ) \left(x_{1}, y_{1}\right) ( x 1 , y 1 ) ( x 2 , y 2 ) \left(x_{2}, y_{2}\right) ( x 2 , y 2 ) x 1 < x 2 , y 1 < y 2 x_{1}<x_{2}, y_{1}<y_{2} x 1 < x 2 , y 1 < y 2 ( x 1 , y 1 , y 2 , 1 ) \left(x_{1}, y_{1}, y_{2}, 1\right) ( x 1 , y 1 , y 2 , 1 ) ( x 2 , y 1 , y 2 , − 1 ) \left(x_{2}, y_{1}, y_{2},-1\right) ( x 2 , y 1 , y 2 , − 1 ) 2 N 2 N 2 N x x x
注意到本题中的 y y y y y y 离散化 。设 v a l ( y ) val(y) v a l ( y ) y y y r a w ( i ) raw(i) r a w ( i ) i i i y y y
在离散化后, 若有 M M M y y y r a w ( 1 ) , r a w ( 2 ) , ⋯ , r a w ( M ) raw(1), raw(2), \cdots, raw(M) r a w ( 1 ) , r a w ( 2 ) , ⋯ , r a w ( M ) M − 1 M-1 M − 1 i i i [ r a w ( i ) , r a w ( i + 1 ) ] [raw(i),raw(i+1)] [ r a w ( i ) , r a w ( i + 1 )] c c c c [ i ] c[i] c [ i ] i i i c c c
逐一扫描排序后的 2 N 2 N 2 N ( x , y 1 , y 2 , k ) \left(x, y_{1}, y_{2}, k\right) ( x , y 1 , y 2 , k ) c c c c [ v a l ( y 1 ) ] , c [ v a l ( y 1 ) + 1 ] , ⋯ , c [ v a l ( y 2 ) − 1 ] c\left[val\left(y_{1}\right)\right], c\left[val\left(y_{1}\right)+1\right], \cdots, c\left[val\left(y_{2}\right)-1\right] c [ v a l ( y 1 ) ] , c [ v a l ( y 1 ) + 1 ] , ⋯ , c [ v a l ( y 2 ) − 1 ] k k k [ y 1 , y 2 ] \left[y_{1}, y_{2}\right] [ y 1 , y 2 ] x 2 x_{2} x 2 x x x x 2 x_{2} x 2 ∑ c [ i ] > 0 ( r a w ( i + 1 ) − r a w ( i ) ) \sum_{c[i]>0}(raw(i+1)-raw(i)) ∑ c [ i ] > 0 ( r a w ( i + 1 ) − r a w ( i )) c c c ( x 2 − x ) ∗ ∑ c [ i ] > 0 ( r a w ( i + 1 ) − r a w ( i ) \left(x_{2}-x\right) * \sum_{c[i]>0}(raw(i+ 1)-raw(i) ( x 2 − x ) ∗ ∑ c [ i ] > 0 ( r a w ( i + 1 ) − r a w ( i )
对于每个四元组, 采用朴素算法在 c c c O ( N 2 ) \mathrm{O}\left(N^{2}\right) O ( N 2 )
值得说明的是, 四元组中的 y 1 , y 2 y_{1}, y_{2} y 1 , y 2 一个“点” 。我们需要维护的是扫描线上每一段 被覆盖的次数及其长度, 对 “点” 的覆盖次数进行统计是没有意义的。因此, 我们把 c c c c [ i ] c[i] c [ i ] ( x , y 1 , y 2 , k ) \left(x, y_{1}, y_{2}, k\right) ( x , y 1 , y 2 , k ) c [ v a l ( y 1 ) ∼ v a l ( y 2 ) − 1 ] c\left[val\left(y_{1}\right) \sim val\left(y_{2}\right)-1\right] c [ v a l ( y 1 ) ∼ v a l ( y 2 ) − 1 ]
另外, 我们可以用线段树维护 c c c O ( N log N ) O(N \log N) O ( N log N )
在本题中, 我们只关心整个扫描线 (线段树根节点) 上被矩形覆盖的长度。而且, 因为四元组 ( x , y 1 , y 2 , 1 ) \left(x, y_{1}, y_{2}, 1\right) ( x , y 1 , y 2 , 1 ) ( x , y 1 , y 2 , − 1 ) \left(x, y_{1}, y_{2},-1\right) ( x , y 1 , y 2 , − 1 )
除左右端点 l , r l, r l , r l e n l e n l e n c n t c n t c n t
对于一个四元组 ( x , y 1 , y 2 , k ) \left(x, y_{1}, y_{2}, k\right) ( x , y 1 , y 2 , k ) [ v a l ( y 1 ) , v a l ( y 2 ) − 1 ] \left[val\left(y_{1}\right), val\left(y_{2}\right)-1\right] [ v a l ( y 1 ) , v a l ( y 2 ) − 1 ] O ( log N ) O(\log N) O ( log N ) c n t c n t c n t k k k
对于线段树中任意一个节点 [ l , r ] [l, r] [ l , r ] c n t > 0 c n t>0 c n t > 0 r a w ( r + 1 ) − r a w ( l ) raw(r+1)-raw(l) r a w ( r + 1 ) − r a w ( l ) l e n len l e n l e n len l e n c n t cnt c n t l e n len l e n 根节点的 l e n len l e n
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 #include <iostream> #include <vector> #include <algorithm> #include <iomanip> using namespace std;const int N = 1e5 + 10 ;int n;struct Range { double x, y1, y2; int k; bool operator < (const Range &t) const { return x < t.x; } } range[N * 2 ]; struct Node { int l, r; int cnt; double len; } tr[N * 2 * 4 ]; vector<double > ys; unordered_map<double , int > idx; int findIdx (double y) return lower_bound (ys.begin (), ys.end (), y) - ys.begin (); } void pushup (Node &u, Node &ls, Node &rs) if (u.cnt) { u.len = ys[u.r + 1 ] - ys[u.l]; } else if (u.l != u.r) { u.len = ls.len + rs.len; } else if (u.l == u.r){ u.len = 0 ; } } void pushup (int u) pushup (tr[u], tr[u << 1 ], tr[u << 1 | 1 ]); } void build (int u, int l, int r) if (l == r) { tr[u] = {l, r, 0 , 0 }; return ; } tr[u] = {l, r}; int mid = l + r >> 1 ; build (u << 1 , l, mid); build (u << 1 | 1 , mid + 1 , r); pushup (u); } void modify (int u, int l, int r, int d) if (l <= tr[u].l && tr[u].r <= r) { tr[u].cnt += d; pushup (u); return ; } int mid = tr[u].l + tr[u].r >> 1 ; if (l <= mid) modify (u << 1 , l, r, d); if (r > mid) modify (u << 1 | 1 , l, r, d); pushup (u); } int main () int T = 1 ; while (cin >> n, n) { ys.clear (); for (int i = 0 ; i < n; ++i) { double x1, y1, x2, y2; cin >> x1 >> y1 >> x2 >> y2; range[i << 1 ] = {x1, y1, y2, 1 }; range[i << 1 | 1 ] = {x2, y1, y2, -1 }; ys.push_back (y1); ys.push_back (y2); } sort (ys.begin (), ys.end ()); ys.erase (unique (ys.begin (), ys.end ()), ys.end ()); for (int i = 0 ; i < ys.size (); ++i) idx[ys[i]] = i; int m = ys.size (); build (1 , 0 , m - 2 ); sort (range, range + 2 * n); double ans = 0 ; for (int i = 0 ; i < 2 * n; ++i) { if (i) ans += tr[1 ].len * (range[i].x - range[i - 1 ].x); modify (1 , idx[range[i].y1], idx[range[i].y2] - 1 , range[i].k); } cout << "Test case #" << T++ << endl; cout << "Total explored area: " << fixed << setprecision (2 ) << ans << endl; cout << endl; } }
在一个天空中有很多星星(看作平面直角坐标系),已知每颗星星的坐标和亮度(都是整数)。
求用宽为 W W W H H H W , H W,H W , H
输入格式
输入包含多组测试用例。
每个用例的第一行包含 3 3 3 n , W , H n,W,H n , W , H
然后是 n n n 3 3 3 x , y , c x,y,c x , y , c ( x , y ) (x,y) ( x , y )
没有两颗星星在同一点上。
输出格式
每个测试用例输出一个亮度总和最大值。
每个结果占一行。
数据范围
1 ≤ n ≤ 10000 1 \le n \le 10000 1 ≤ n ≤ 10000 1 ≤ W , H ≤ 1000000 1 \le W,H \le 1000000 1 ≤ W , H ≤ 1000000 0 ≤ x , y < 2 31 0 \le x,y < 2^{31} 0 ≤ x , y < 2 31
输入样例:
1 2 3 4 5 6 7 8 3 5 4 1 2 3 2 3 2 6 3 1 3 5 4 1 2 3 2 3 2 5 3 1
输出样例:
算法分析
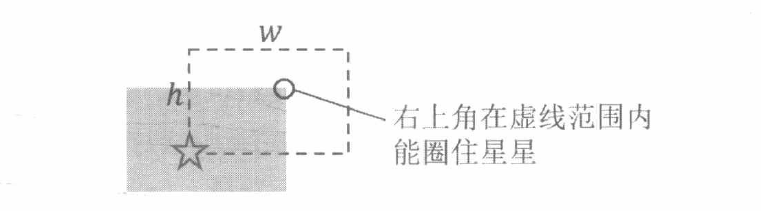
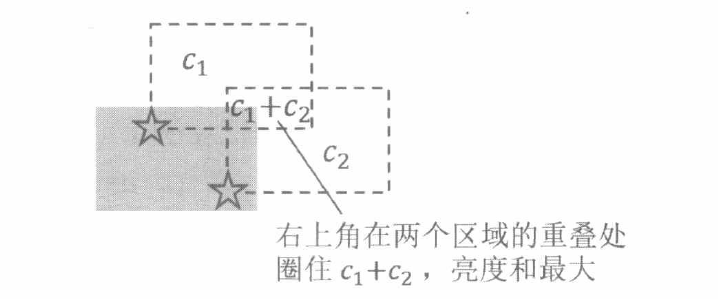
因为矩形的大小固定, 所以矩形可以由它的任意一个顶点唯一确定。我们可以考虑把矩形的右上角顶点放在什么位置 , 圈住的星星亮度总和最大。
对于一个星星 ( x , y , c ) (x, y, c) ( x , y , c ) x , y x, y x , y c c c ( x , y ) (x, y) ( x , y ) ( x + w , y + h ) (x+w, y+h) ( x + w , y + h )
题目中说 “矩形边界上的星星不算” 。为了处理这种边界情况, 不妨把所有星星向左、向下各移动 0.5 0.5 0.5 ( x , y ) (x, y) ( x , y ) ( x − 0.5 , y − 0.5 ) (x-0.5, y-0.5) ( x − 0.5 , y − 0.5 ) 不妨假设圈住星星的矩形顶点坐标都是整数 。于是, 上图虚线 “区域” 的左下角可看作 ( x , y ) (x, y) ( x , y ) ( x + w − 1 , y + h − 1 ) (x+w-1, y+h-1) ( x + w − 1 , y + h − 1 )
此时, 问题转化为: 平面上有若干个区域, 每个区域都带有一个权值, 求在哪个坐 标上重叠的区域权值和最大。其中, 每一个区域都是由一颗星星产生的, 权值等于星星 的亮度, 把原问题中的矩形右上角放在该区域中, 就能圈住这颗星星。
在转化后的问题中, 我们使用扫描线算法, 取出每个区域的左右边界, 保存成两个四元组 ( x , y , y + h − 1 , c ) (x, y, y+h-1, c) ( x , y , y + h − 1 , c ) ( x + w , y , y + h − 1 , − c ) (x+w, y, y+h-1,-c) ( x + w , y , y + h − 1 , − c )
同时, 关于纵坐标建立一棵线段树, 维护区间最大值 d a t d a t d a t ( x , y 1 , y 2 , c ) \left(x, y_{1}, y_{2}, c\right) ( x , y 1 , y 2 , c ) [ y 1 , y 2 ] \left[y_{1}, y_{2}\right] [ y 1 , y 2 ] c c c
Solution
动态开点与线段树合并