#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> usingnamespace std; int a[100], v[100], n, len, cnt;
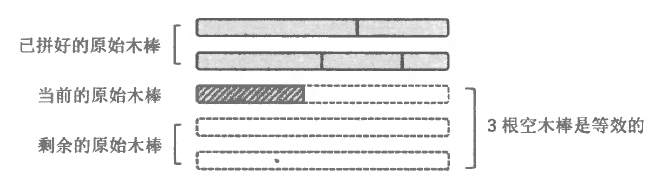
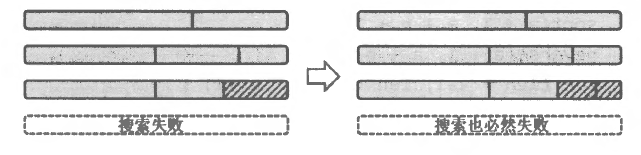
// 正在拼第stick根原始木棒(已经拼好了stick-1根) // 第stick根木棒的当前长度为cab // 拼接到第stick根木棒中的上一根小木棍为last booldfs(int stick, int cab, int last){ // 所有原始木棒已经全部拼好,搜索成功 if (stick > cnt) returntrue; // 第stick根木棒已经拼好,去拼下一根 if (cab == len) returndfs(stick + 1, 0, 1); int fail = 0; // 剪枝(2) // 剪枝(1):小木棍长度递减(从last开始枚举) for (int i = last; i <= n; i++) if (!v[i] && cab + a[i] <= len && fail != a[i]) { v[i] = 1; if (dfs(stick, cab + a[i], i + 1)) returntrue; fail = a[i]; v[i] = 0; // 还原现场 if (cab == 0 || cab + a[i] == len) returnfalse; // 剪枝(3,4) } returnfalse; // 所有分支均尝试过,搜索失败 }
intmain(){ while (cin >> n && n) { int sum = 0, val = 0, m = 0; for (int i = 1; i <= n; i++) { int x; scanf("%d", &x); if (x <= 50) { a[++m] = x; sum += a[m]; val = max(val, a[m]); } } n = m; sort(a + 1, a + n + 1); reverse(a + 1, a + n + 1); for (len = val; len <= sum; len++) { if (sum % len) continue; cnt = sum / len; // 原始木棒长度为len,共cnt根 memset(v, 0, sizeof(v)); if (dfs(1, 0, 1)) break; } cout << len << endl; } }
#include<iostream> #include<cstring> #include<algorithm> usingnamespace std; constint N = 70;
int n; int w[N], sum, len; bool used[N];
booldfs(int u, int curl, int start){ if (u * len == sum) returntrue; //当前大木棒已经拼好了,成功与否完全看后面大木棒拼接情况 if (curl == len) returndfs(u + 1, 0, 0); for (int i = start; i < n; ++i) { if (used[i]) continue; if (curl + w[i] > len) continue; used[i] = true; if (dfs(u, curl + w[i], i + 1)) returntrue; //当前加入第 i 个小木棒失败了之后的处理逻辑 used[i] = false; if (curl == 0) returnfalse; if (curl + w[i] == len) returnfalse; int j = i; while (j < n && w[j] == w[i]) ++j; i = j - 1; //因为后面有 ++i,所以要回退一个 } returnfalse;// 所有分支均尝试过,搜索失败 }
intmain(){ while (cin >> n, n) { memset(used, 0, sizeof used); sum = 0; for (int i = 0; i < n; ++i) { cin >> w[i]; sum += w[i]; } sort(w, w + n, greater<int>()); len = 1; while (true) { if (sum % len == 0 && dfs(0, 0, 0)) { cout << len << endl; break; } ++len; } } }
#include<cmath> #include<iostream> #include<algorithm> usingnamespace std; constint INF = 0x7fffffff; int n, m, minv[30], mins[30], ans = INF; int h[30], r[30], s = 0, v = 0;
voiddfs(int dep){ if (!dep) { if (v == n) ans = min(ans, s); return; } for (r[dep] = min((int)sqrt(n - v), r[dep + 1] - 1); r[dep] >= dep; r[dep]--) for (h[dep] = min((int)((double)(n-v) / r[dep] / r[dep]), h[dep+1] - 1); h[dep] >= dep; h[dep]--) { if (v + minv[dep-1] > n) continue; if (s + mins[dep-1] > ans) continue; if (s + (double)2 * (n - v) / r[dep] > ans) continue; if (dep == m) s += r[dep] * r[dep]; s += 2 * r[dep] * h[dep]; v += r[dep] * r[dep] * h[dep]; dfs(dep - 1); if (dep == m) s -= r[dep] * r[dep]; s -= 2 * r[dep] * h[dep]; v -= r[dep] * r[dep] * h[dep]; } }
intmain(){ cin >> n >> m; minv[0] = mins[0] = 0; for (int i = 1; i <= m; i++) { minv[i] = minv[i-1] + i * i * i; mins[i] = mins[i-1] + i * i; } h[m+1] = r[m+1] = INF; dfs(m); cout << ans << endl; return0; }
#include<cstdio> #include<vector> #include<cstring> #include<iostream> usingnamespace std; char s[16][16]; int cnt[1<<16], f[1<<16], num[16][16], n = 0; vector<int> e[1<<16];
voidwork(int i, int j, int k){ for (int t = 0; t < 16; t++) { num[i][t] &= ~(1 << k); num[t][j] &= ~(1 << k); } int x = i / 4 * 4, y = j / 4 * 4; for (int ti = 0; ti < 4; ti++) for (int tj = 0; tj < 4; tj++) num[x+ti][y+tj] &= ~(1 << k); }
booldfs(int ans){ if (!ans) return1; int pre[16][16]; memcpy(pre, num, sizeof(pre)); for (int i = 0; i < 16; i++) for (int j = 0; j < 16; j++) if (s[i][j] == '-') { if (!num[i][j]) return0; if (cnt[num[i][j]] == 1) { s[i][j] = f[num[i][j]] + 'A'; work(i, j, f[num[i][j]]); if (dfs(ans - 1)) return1; s[i][j] = '-'; memcpy(num, pre, sizeof(num)); return0; } } for (int i = 0; i < 16; i++) { int w[16], o = 0; memset(w, 0, sizeof(w)); for (int j = 0; j < 16; j++) if (s[i][j] == '-') { o |= num[i][j]; for (unsignedint k = 0; k < e[num[i][j]].size(); k++) ++w[e[num[i][j]][k]]; } else { o |= (1 << (s[i][j] - 'A')); w[f[1<<(s[i][j]-'A')]] = -1; } if (o != (1 << 16) - 1) return0; for (int k = 0; k < 16; k++) if (w[k] == 1) for (int j = 0; j < 16; j++) if (s[i][j] == '-' && ((num[i][j] >> k) & 1)) { s[i][j] = k + 'A'; work(i, j, k); if (dfs(ans - 1)) return1; s[i][j] = '-'; memcpy(num, pre, sizeof(num)); return0; } } for (int j = 0; j < 16; j++) { int w[16], o = 0; memset(w, 0, sizeof(w)); for (int i = 0; i < 16; i++) if (s[i][j] == '-') { o |= num[i][j]; for (unsignedint k = 0; k < e[num[i][j]].size(); k++) ++w[e[num[i][j]][k]]; } else { o |= (1 << (s[i][j] - 'A')); w[f[1<<(s[i][j]-'A')]] = -1; } if (o != (1 << 16) - 1) return0; for (int k = 0; k < 16; k++) if (w[k] == 1) for (int i = 0; i < 16; i++) if (s[i][j] == '-' && ((num[i][j] >> k) & 1)) { s[i][j] = k + 'A'; work(i, j, k); if (dfs(ans - 1)) return1; s[i][j] = '-'; memcpy(num, pre, sizeof(num)); return0; } } for (int i = 0; i < 16; i += 4) for (int j = 0; j < 16; j += 4) { int w[16], o = 0; memset(w, 0, sizeof(w)); for (int p = 0; p < 4; p++) for (int q = 0; q < 4; q++) if (s[i+p][j+q] == '-') { o |= num[i+p][j+q]; for (unsignedint k = 0; k < e[num[i+p][j+q]].size(); k++) ++w[e[num[i+p][j+q]][k]]; } else { o |= (1 << (s[i+p][j+q] - 'A')); w[f[1<<(s[i+p][j+q]-'A')]] = -1; } if (o != (1 << 16) - 1) return0; for (int k = 0; k < 16; k++) if (w[k] == 1) for (int p = 0; p < 4; p++) for (int q = 0; q < 4; q++) if (s[i+p][j+q] == '-' && ((num[i+p][j+q] >> k) & 1)) { s[i+p][j+q] = k + 'A'; work(i + p, j + q, k); if (dfs(ans - 1)) return1; s[i+p][j+q] = '-'; memcpy(num, pre, sizeof(num)); return0; } } int k = 17, tx, ty; for (int i = 0; i < 16; i++) for (int j = 0; j < 16; j++) if (s[i][j] == '-' && cnt[num[i][j]] < k) { k = cnt[num[i][j]]; tx = i; ty = j; } for (unsignedint i = 0; i < e[num[tx][ty]].size(); i++) { int tz = e[num[tx][ty]][i]; work(tx, ty, tz); s[tx][ty] = tz + 'A'; if (dfs(ans - 1)) return1; s[tx][ty] = '-'; memcpy(num, pre, sizeof(num)); } return0; }
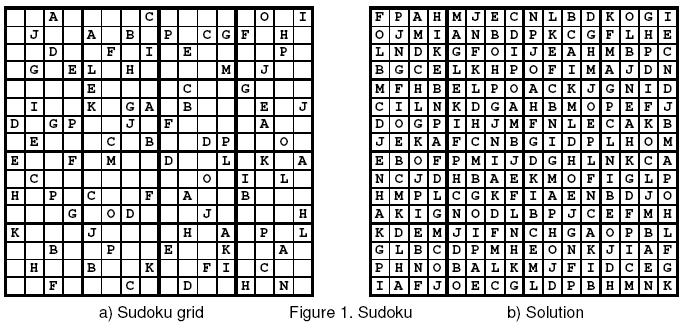
voidSudoku(){ for (int i = 1; i < 16; i++) cin >> s[i]; for (int i = 0; i < 16; i++) for (int j = 0; j < 16; j++) num[i][j] = (1 << 16) - 1; int ans = 0; for (int i = 0; i < 16; i++) for (int j = 0; j < 16; j++) if (s[i][j] != '-') work(i, j, s[i][j] - 'A'); else ++ans; dfs(ans); for (int i = 0; i < 16; i++) { for (int j = 0; j < 16; j++) cout << s[i][j]; cout << endl; } cout << endl; }
intget_cnt(int i){ int k = i & -i; e[i].push_back(f[k]); for (unsignedint j = 0; j < e[i-k].size(); j++) e[i].push_back(e[i-k][j]); return cnt[i-k] + 1; }
intmain(){ memset(f, 0, sizeof(f)); for (int i = 0; i < 16; i++) f[1<<i] = i; cnt[0] = 0; for (int i = 1; i < (1 << 16); i++) cnt[i] = get_cnt(i); while (cin >> s[0]) Sudoku(); return0; }