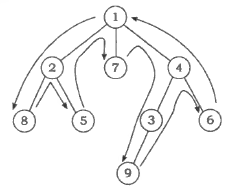
树中各个节点的深度是一种自顶向下的统计信息。起初, 我们已知根节点的深度为 0 。若节点 x 的深度为 d[x], 则它的子节点 y 的深度就是 d[y]=d[x]+1 。在深度优先遍历的过程中结合自顶向下的递推, 就可以求出每个节点的深度 d 。
1 2 3 4 5 6 7 8 9 10
// 求树中各点的深度 voiddfs(int x){ v[x] = 1; for (int i = head[x]; i; i = next[i]) { int y = ver[i]; if (v[y]) continue; // 点y已经被访问过了 d[y] = d[x] + 1; //从父节点 x 到子节点 y 递推,计算深度 dfs(y); } }
树的重心
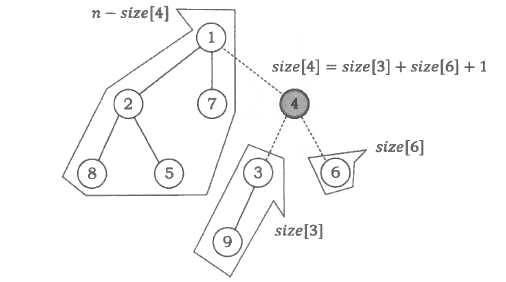
当然, 也有许多信息是自底向上进行统计的, 比如以每个节点 x 为根的子树大小 size[x] 。对于叶子节点, 我们已知 “以它为根的子树” 大小为 1 。若节点 x 有 k 个子节点 y1∼yk , 并且以 y1∼yk 为根的子树大小分别是 size[y1],size[y2],⋯,size[yk], 则以 x 为根的子树的大小就是 size[x]=size[y1]+size[y2]+⋯+size[yk]+1 。
对于一个节点 x, 如果我们把它从树中删除, 那么原来的一棵树可能会分成若干个不相连的部分, 其中每一部分都是一棵子树。设 max_part(x) 表示在删除节点 x 后产生的子树中, 最大的一棵的大小。使 max_part 函数取到最小值的节点 p 就称为整棵树的重心。例如上图中的树的重心应该是节点 1 。通过下面的代码, 我们可以统计出 size 数组, 并求出树的重心。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// 求树的重心 voiddfs(int x){ v[x] = 1; size[x] = 1; // 子树x的大小 int max_part = 0; // 删掉x后分成的最大子树的大小 for (int i = head[x]; i; i = next[i]) { int y = ver[i]; if (v[y]) continue; // 点y已经被访问过了 dfs(y); size[x] += size[y]; // 从子节点向父节点递推 max_part = max(max_part, size[y]); } max_part = max(max_part, n - size[x]); // n 为整棵树的节点数目 if (max_part < ans) { ans = max_part; // 全局变量 ans 记录重心对应的 max_part 值 pos = x; // 全局变量 pos 记录了重心 } }
图的连通块划分
下面的代码每从 x 开始一次遍历, 就会访问 x 能㡅到达的所有的点与边。因此, 通过多次深度优先遍历, 可以划分出一张无向图中的各个连通块。同理, 对一个森林进行深度优先遍历, 可以划分出森林中的每棵树。如下面的代码所示, cnt 就是无向图包含的连通块的个数, v 数组标记了每个点属于哪一个连通块。
// 广度优先遍历框架 voidbfs(){ memset(d, 0, sizeof(d)); queue<int> q; q.push(1); d[1] = 1; while (q.size()) { int x = q.front(); q.pop(); for (int i = head[x]; i; i = next[i]) { int y = ver[i]; if (d[y]) continue; d[y] = d[x] + 1; q.push(y); } } }
在上面的代码中, 我们在广度优先遍历的过程中顺便求出了一个 d 数组。对于一棵树来讲, d[x] 就是点 x 在树中的深度。对于一张图来讲, d[x] 被称为点 x 的层次 (从起点 1 走到点 x 需要经过的最少点数)。从代码和示意图中我们可以发现, 广度优先遍历是一种按照层次顺序进行访问的方法, 它具有如下两个重要性质;
在访问完所有的第 i 层节点后, 才会开始访问第 i+1 层节点。
任意时刻, 队列中至多有两个层次的节点。若其中一部分节点属于第 i 层, 则另一部分节点属于第 i+1 层, 并且所有第 i 层节点排在第 i+1 层节点之前。也就是说, 广度优先遍历队列中的元素关于层次满足 “两段性” 和 “单调性”。
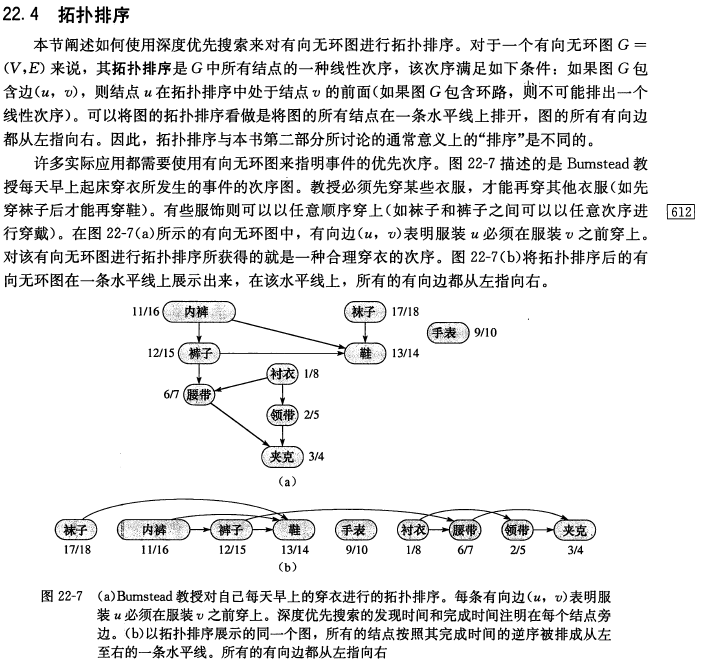
// 拓扑排序, 链式前向星存图写法 voidadd(int x, int y){ // 在邻接表中添加一条有向边 ver[++tot] = y, next[tot] = head[x], head[x] = tot; deg[y]++; } voidtopsort(){ queue<int> q; for (int i = 1; i <= n; i++) if (deg[i] == 0) q.push(i); while (q.size()) { int x = q.front(); q.pop(); a[++cnt] = x; //出队时存储 for (int i = head[x]; i; i = next[i]) { int y = ver[i]; if (--deg[y] == 0) q.push(y); } } } intmain(){ cin >> n >> m; // 点数、边数 for (int i = 1; i <= m; i++) { int x, y; scanf("%d%d", &x, &y); add(x, y); } topsort(); if (cnt != n) cout << "不存在拓扑排序"; else { for (int i = 1; i <= cnt; i++) printf("%d ", a[i]); cout << endl; } }
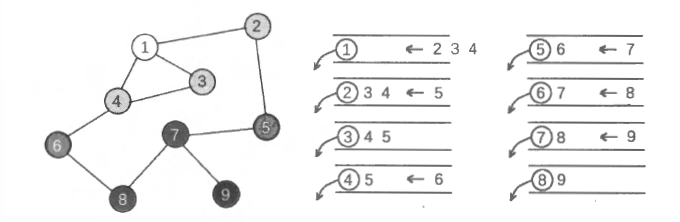
也就是说, 从 x 出发能够到达的点, 是从 “ x 的各个后继节点 y "出发能够到达 的点的并集, 再加上点 x 自身。所以, 在计算出一个点的所有后继节点的 f 值之后, 就可以计算出该点的 f 值。这启发我们先用拓扑排序算法求出一个拓扑序, 然后按照 拓扑序的倒序进行计算一一因为在拓扑序中, 对任意的一条边 (x,y),x 都排在 y 之 前。
回想起状态压缩方法, 我们可以使用一个 N 位二进制数存储每个 f(x), 其中第 i 位是 1 表示 x 能到 i , 0 表示不能到 i 。这样一来, 对若干个集合求并, 就相当于对若干个 N 位二进制数做 “按位或” 运算。最后, 每个 f(x) 中 1 的个数就是从 x 出发能够到达的节点数量。
这个 N 位二进制数可以压缩成 N/32+1 个无符号 32 位整数 unsigned int 进行存储, 更简便的方法是直接使用 C++ STL 中为我们提供的 bitset , bitset 支持我们上述所需的所有运算。该拓扑排序 + 状态压缩算法花费的时间规模约为N(N+M)/32 , 所需空间大小约为 N2/8 字节。
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> #include<bitset> #include<queue> usingnamespace std; int n, m, deg[30010], a[30010]; int ver[30010], Next[30010], head[30010], tot, cnt; bitset<30010> f[30010];
voidadd(int x, int y){ // 在邻接表中添加一条有向边 ver[++tot] = y, Next[tot] = head[x], head[x] = tot; deg[y]++; }
voidtopsort(){ // 拓扑排序 queue<int> q; for (int i = 1; i <= n; i++) if (deg[i] == 0) q.push(i); while (q.size()) { int x = q.front(); q.pop(); a[++cnt] = x; for (int i = head[x]; i; i = Next[i]) { int y = ver[i]; if (--deg[y] == 0) q.push(y); } } }
voidcalc(){ for (int i = cnt; i; i--) { int x = a[i]; f[x][x] = 1; for (int i = head[x]; i; i = Next[i]) { int y = ver[i]; f[x] |= f[y]; } } }
intmain(){ cin >> n >> m; // 点数、边数 for (int i = 1; i <= m; i++) { int x, y; scanf("%d%d", &x, &y); add(x, y); } topsort(); calc(); for (int i = 1; i <= n; i++) printf("%d\n", f[i].count()); }
intmain(){ memset(num, 0, sizeof(num)); int n, m; cin >> n >> m; for (int i = 1; i <= m; i++) { int x, y; cin >> x >> y; e[x].push_back(y); num[y]++; b[x][y] = 1; } for (int i = 1; i <= n; i++) if (!num[i]) q.push(i); while (q.size()) { int x = q.front(); q.pop(); a.push_back(x); for (unsignedint i = 0; i < e[x].size(); i++) { int y = e[x][i]; if (!--num[y]) q.push(y); } } for (int i = 1; i <= n; i++) b[i][i] = 1; for (int i = a.size() - 1; i >= 0; i--) { int x = a[i]; for (unsignedint j = 0; j < e[x].size(); j++) b[x] |= b[e[x][j]]; ans[x] = b[x].count(); } for(int i = 1; i <= n; i++) cout << ans[i] << endl; return0; }