给定一张 N 个点(编号 1,2…N),M 条边的有向图,求从起点 S 到终点 T 的第 K 短路的长度,路径允许重复经过点或边。
注意: 每条最短路中至少要包含一条边。
输入格式
第一行包含两个整数 N 和 M。
接下来 M 行,每行包含三个整数 A,B 和 L,表示点 A 与点 B 之间存在有向边,且边长为 L。
最后一行包含三个整数 S,T 和 K,分别表示起点 S,终点 T 和第 K 短路。
输出格式
输出占一行,包含一个整数,表示第 K 短路的长度,如果第 K 短路不存在,则输出 −1。
数据范围
1≤S,T≤N≤1000, 0≤M≤105, 1≤K≤1000, 1≤L≤100
输入样例:
1 2 3 4
2 2 1 2 5 2 1 4 1 2 2
输出样例:
1
14
算法分析
一个比较直接的想法是使用优先队列 BFS 进行求解。优先队列 (堆) 中保存一些二元组 (x,dist), 其中 x 为节点编号, dist 表示从 S 沿着某条路径到 x 的距离。
起初, 堆中只有 (S,0) 。我们不断从堆中取出 dist 值最小的二元组 (x,dist), 然后沿着从 x 出发的每条边 (x,y) 进行扩展, 把新的二元组 (y,dist+length(x,y)) 插入到堆中 (无论堆中是否已经存在一个节点编号为 y 的二元组)。
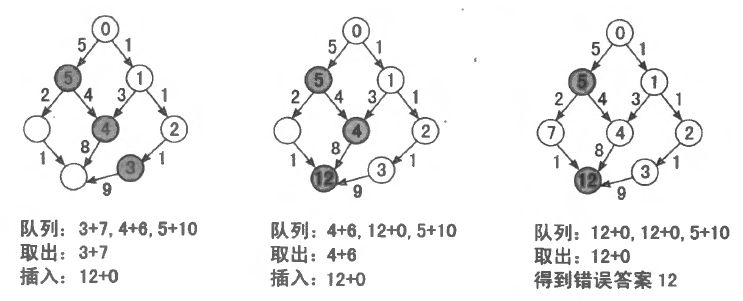
上一节我们已经讲到, 在优先队列 BFS 中, 某个状态第一次从堆中被取出时, 就得到了从初态到它的最小代价。读者用数学归纳法很容易得到一个推论: 对于任意正整数 i 和任意节点 x, 当第 i 次从堆中取出包含节点 x 的二元组时, 对应的 dist 值就是从 S 到 x 的第 i 短路。(所以, 当扩展到的节点 y 已经被取出 K 次时, 就没有必要再插入堆中了。注意:如果使用 A∗ 算法,加了估价函数后,中间的第一次出队不一定是最短距离,故不能只用取出 K 次进行优化)。最后当节点 T 第 K 次被取出时, 就得到了 S 到 T 的第 K 短路。
根据估价函数的设计准则, 在第 K 短路中从 x 到 T 的估计距离 f(x) 应该不大于第 K 短路中从 x 到 T 的实际距离 g(x) 。于是, 我们可以把估价函数 f(x) 定为从 x 到 T 的最短路长度, 这样不但能保证 f(x)≤g(x), 还能顺应 g(x) 的实际变化趋势。 最终我们得到了以下 A∗ 算法:
预处理出各个节点 x 到终点 T 的最短路长度 f(x) 一一这等价于在反向图上以 T 为起点求解单源最短路径问题, 可以在 O((N+M)log(N+M)) 的时间内完成。
建立一个二叉堆, 存储一些二元组 (x,dist+f(x)), 其中 x 为节点编号, dist 表示从 S 到 x 当前走过的距离。起初堆中只有 (S,0+f(0)) 。
从二叉堆中取出 dist+f(x) 值最小的二元组 (x,dist+f(x)), 然后沿着从 x 出发的每条边 (x,y) 进行扩展。如果节点 y 被取出的次数尚未达到 K , 就把新的二元组 (y,dist+length(x,y)+f(y)) 插入堆中。
重复第 2∼3 步, 直至第 K 次取出包含终点 T 的二元组, 此时二元组中的 dist 值就是从 S 到 T 的第 K 短路。
//Author:XuHt #include<queue> #include<cstdio> #include<vector> #include<cstring> #include<iostream> usingnamespace std; constint N = 1006; int n, m, st, ed, k, f[N], cnt[N]; bool v[N]; vector<pair<int, int> > e[N], fe[N]; priority_queue<pair<int, int> > pq;
voiddijkstra(){ memset(f, 0x3f, sizeof(f)); memset(v, 0, sizeof(v)); f[ed] = 0; pq.push(make_pair(0, ed)); while (pq.size()) { int x = pq.top().second; pq.pop(); if (v[x]) continue; v[x] = 1; for (unsignedint i = 0; i < fe[x].size(); i++) { int y = fe[x][i].first, z = fe[x][i].second; if (f[y] > f[x] + z) { f[y] = f[x] + z; pq.push(make_pair(-f[y], y)); } } } }
voidA_star(){ if (st == ed) ++k; pq.push(make_pair(-f[st], st)); memset(cnt, 0, sizeof(cnt)); while (pq.size()) { int x = pq.top().second; int dist = -pq.top().first - f[x]; pq.pop(); ++cnt[x]; if (cnt[ed] == k) { cout << dist << endl; return; } for (unsignedint i = 0; i < e[x].size(); i++) { int y = e[x][i].first, z = e[x][i].second; if (cnt[y] != k) pq.push(make_pair(-f[y] - dist - z, y)); } } cout << "-1" << endl; }
intmain(){ cin >> n >> m; for (int i = 1; i <= m; i++) { int x, y, z; scanf("%d %d %d", &x, &y, &z); e[x].push_back(make_pair(y, z)); fe[y].push_back(make_pair(x, z)); } cin >> st >> ed >> k; dijkstra(); A_star(); return0; }
using PII = pair<int, int>; using PIII = pair<int, PII>; constint N = 1010, M = 2e5 + 10, INF = 0x3f3f3f3f;
structNode{ int deva = INF, dreal, id; booloperator < (const Node &x) const { return deva + dreal > x.deva + x.dreal; } }node[M];
int n, m, st, ed, k; int h[N], rh[N], e[M], w[M], ne[M], idx; int dist[N]; bool used[N];
voidadd(int h[], int a, int b, int c){ e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx++; }
voiddijkstra(){ priority_queue<PII, vector<PII>, greater<PII>> heap; node[ed].deva = 0; heap.push({0, ed}); while (heap.size()) { auto now = heap.top(); heap.pop(); int ver = now.second; if (used[ver]) continue; used[ver] = true; for (int i = rh[ver]; ~i; i = ne[i]) { int adj = e[i]; if (node[adj].deva > node[ver].deva + w[i]) { node[adj].deva = node[ver].deva + w[i]; heap.push({node[adj].deva, adj}); } } } }
intastar(){ if (node[st].deva == INF) return-1; priority_queue<Node> heap; heap.push({node[st].deva, 0, st}); int cnt = 0; while (heap.size()) { auto now = heap.top(); heap.pop();
if (now.id == ed) ++cnt; if (cnt == k) return now.dreal; for (int i = h[now.id]; ~i; i = ne[i]) { int adj = e[i]; heap.push({node[adj].deva, now.dreal + w[i], adj}); } } return-1; }
intmain(){ cin >> n >> m; memset(h, -1, sizeof h); memset(rh, -1, sizeof rh); for (int i = 1; i <= m; ++i) { int a, b, c; cin >> a >> b >> c; add(h, a, b, c); add(rh, b, a, c); } cin >> st >> ed >> k; if (st == ed) ++k; dijkstra(); cout << astar() << endl; }
structNode{ int d, pos; string s, op; booloperator<(const Node&x) const { return d > x.d; } };
intcalc(string &s){ int md = 0; for (int i = 0; i < s.size(); ++i) { if (s[i] == 'x') continue; int num = s[i] - '1'; md += abs(num / 3 - i / 3) + abs(num % 3 - i % 3); } return md; }
boolvalid(int x, int y){ return x >= 0 && x < n && y >= 0 && y < n; }
string astar(string &st, string &ed){ unordered_map<string, int> dist; priority_queue<Node> q; int pos = 0; while (st[pos] != 'x') ++pos; dist[st] = 0; q.push({calc(st), pos, st, ""}); while (q.size()) { auto now = q.top(); q.pop(); if (now.s == ed) return now.op; for (int i = 0; i < 4; ++i) { auto s = now.s; auto pos = now.pos; int x = pos / 3 + dx[i], y = pos % 3 + dy[i], npos = x * 3 + y; if (!valid(x, y)) continue; swap(s[pos], s[npos]); if (!dist.count(s) || dist[s] > dist[now.s] + 1) { dist[s] = dist[now.s] + 1; q.push({dist[s] + calc(s), npos, s, now.op + dir[i]}); } } } }
intmain(){ string seq; for (int i = 0; i < 9; ++i) { char c; cin >> c; st += c; if (c != 'x') seq += c; } int cnt = 0; for (int i = 0; i < 8; ++i) for (int j = i + 1; j < 8; ++j) if (seq[i] > seq[j]) ++cnt;