参考《算法竞赛进阶指南》 、AcWing题库
二叉堆
二叉堆是一种支持插入、删除、查询最值的数据结构。它其实是一棵满足“堆性质” 的完全二叉树, 树上的每个节点带有一个权值。
完全二叉树:叶子节点都在最后两层,且在最后一层集中于左侧的二叉树。
若树中的任意一个节点的权值都小于等于其父节点的权值, 则称该二叉树满足 “大根堆性质”。若树中任意一个节点的权值都大于等于其父节点的权值, 则称该二叉树满足 “小根堆性质” 。满足 “大根堆性质” 的完全二叉树就是 “大根堆”, 而满足 “小根堆性质” 的完全二叉树就是 “小根堆” , 二者都是二叉堆的形态之一。
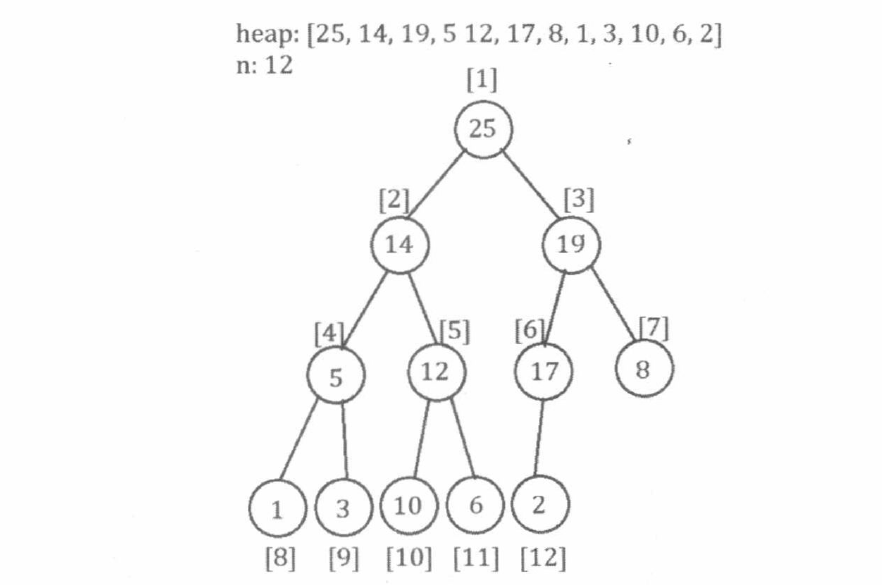
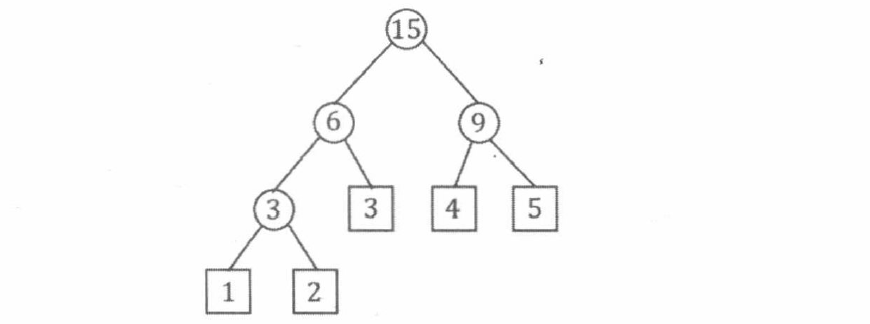
根据完全二叉树的性质, 我们可以采用层次序列存储方式, 直接用一个数组来保存二叉堆。层次序列存储方式, 就是逐层从左到右为树中的节点依次编号, 把此编号作为节点在数组中存储的位置 (下标)。在这种存储方式中, 父节点编号等于子节点编号除以 2 , 左子节点编号等于父节点编号乘 2 , 右子节点编号等于父节点编号乘 2 加 1 , 如下图所示。
我们以大根堆为例探讨堆支持的几种常见操作的实现。
Insert
I n s e r t ( v a l ) Insert (val) I n ser t ( v a l ) v a l val v a l O ( log N ) O(\log N) O ( log N )
1 2 3 4 5 6 7 8 9 10 11 12 13 int heap[SIZE], idx; void up (int u) while (u / 2 && heap[u] > heap[u / 2 ]) { swap (heap[u], heap[u / 2 ]); u /= 2 ; } } void insert (int val) heap[++idx] = val; up (idx); }
GetTop
G e t T o p GetTop G e tT o p h e a p [ 1 ] heap[1] h e a p [ 1 ] O ( 1 ) O(1) O ( 1 )
1 2 3 int getTop () return heap[1 ]; }
RemoveTop
R e m o v e T o p RemoveTop R e m o v e T o p h e a p [ 1 ] heap[1] h e a p [ 1 ] h e a p [ n ] heap[n] h e a p [ n ] n n n O ( log N ) O(\log N) O ( log N )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void down (int u) int t = u, ls = u << 1 , rs = u << 1 | 1 ; if (ls <= idx && heap[t] < heap[ls]) t = ls; if (rs <= idx && heap[t] < heap[rs]) t = rs; if (t != u) { swap (t, u); down (t); } } void removeTop () heap[1 ] = head[idx--]; down (1 ); }
Romove
Remove ( p ) \operatorname{Remove}(p) Remove ( p ) p p p h e a p [ p ] heap[p] h e a p [ p ] h e a p [ n ] heap[n] h e a p [ n ] n n n h e a p [ p ] heap[p] h e a p [ p ] O ( log N ) O(\log N) O ( log N )
1 2 3 4 void remove (int k) heap[k] = heap[idx--]; up (k), down (k); }
C++ STL中的 priority_queue (优先队列) 为实现了一个大根堆, 支持 p u s h ( I n s e r t ) push (Insert) p u s h ( I n ser t ) t o p ( G e t T o p ) top (GetTop) t o p ( G e tT o p ) p o p ( R e m o v e T o p ) pop (RemoveTop) p o p ( R e m o v e T o p ) R e m o v e Remove R e m o v e
例题
超市里有 N N N p i p_i p i d i d_i d i
求合理安排每天卖的商品的情况下,可以得到的最大收益是多少。
输入格式
输入包含多组测试用例。
每组测试用例,以输入整数 N N N N N N p i p_i p i d i d_i d i i i i
在输入中,数据之间可以自由穿插任意个空格或空行,输入至文件结尾时终止输入,保证数据正确。
输出格式
对于每组产品,输出一个该组的最大收益值。
每个结果占一行。
数据范围
0 ≤ N ≤ 10000 0 \le N \le 10000 0 ≤ N ≤ 10000 1 ≤ p i , d i ≤ 10000 1 \le p_i,d_i \le 10000 1 ≤ p i , d i ≤ 10000 14 14 14
输入样例:
1 2 3 4 4 50 2 10 1 20 2 30 1 7 20 1 2 1 10 3 100 2 8 2 5 20 50 10
输出样例:
算法分析
容易想到一个贪心策略:在最优解中, 对于每个时间 (天数) t t t t t t 。因此, 我们可以依次考虑每个商品, 动态维护一个满足上述性质的方案。
详细地说, 我们把商品按照过期时间排序, 建立一个初始为空的小根堆 (节点权值为商品利润), 然后扫描每个商品:
若当前商品的过期时间 (天数) t t t t t t t t t t t t
若当前商品的过期时间 (天数) 大于当前堆中的商品个数, 直接把该商品插入堆。
最终, 堆里的所有商品就是我们需要卖出的商品, 它们的利润之和就是答案。该算法的时间复杂度为 O ( N log N ) O(N \log N) O ( N log N )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <queue> #include <cstdio> #include <iostream> #include <algorithm> using namespace std;const int N = 10006 ;int n;pair<int , int > a[N]; priority_queue<int > q; void Supermarket () for (int i = 1 ; i <= n; i++) scanf ("%d %d" , &a[i].second, &a[i].first); sort (a + 1 , a + n + 1 ); for (int i = 1 ; i <= n; i++) { if (a[i].first == q.size () && -q.top () < a[i].second) { q.pop (); q.push (-a[i].second); continue ; } if (a[i].first > q.size ()) q.push (-a[i].second); } int ans = 0 ; while (q.size ()) { ans += q.top (); q.pop (); } cout << -ans << endl; } int main () while (cin >> n) Supermarket (); return 0 ; }
Solution
给定 m m m n n n
现在我们可以从每个序列中选择一个数字以形成具有 m m m
很明显,我们一共可以得到 n m n^m n m n m n^m n m
现在请你求出这些序列和之中最小的 n n n
输入格式
第一行输入一个整数 T T T
接下来输入 T T T
对于每组测试用例,第一行输入两个整数 m m m n n n
接下在 m m m m m m 10000 10000 10000
输出格式
对于每组测试用例,均以递增顺序输出最小的 n n n
每组输出占一行。
数据范围
0 < m ≤ 1000 0 < m \le 1000 0 < m ≤ 1000 0 < n ≤ 2000 0 < n \le 2000 0 < n ≤ 2000
输入样例:
输出样例:
算法分析
先来考虑当 M = 2 M=2 M = 2 N 2 N^{2} N 2 N N N A A A B B B
可以发现, 最小和一定是 A [ 1 ] + B [ 1 ] A[1]+B[1] A [ 1 ] + B [ 1 ] min ( A [ 1 ] + B [ 2 ] , A [ 2 ] + B [ 1 ] ) \min (A[1]+B[2], A[2]+B[1]) min ( A [ 1 ] + B [ 2 ] , A [ 2 ] + B [ 1 ]) A [ 2 ] + B [ 1 ] A[2]+B[1] A [ 2 ] + B [ 1 ] A [ 1 ] + B [ 2 ] , A [ 2 ] + B [ 2 ] , A [ 3 ] + B [ 1 ] A[1]+B[2], A[2]+B[2], A[3]+B[1] A [ 1 ] + B [ 2 ] , A [ 2 ] + B [ 2 ] , A [ 3 ] + B [ 1 ] 当确定 A [ i ] + B [ j ] A[i]+B[j] A [ i ] + B [ j ] k k k A [ i + 1 ] + B [ j ] A[i+1]+B[j] A [ i + 1 ] + B [ j ] A [ i ] + B [ j + 1 ] A[i]+B[j+1] A [ i ] + B [ j + 1 ] k + 1 k+1 k + 1 。读者可以类比有两个指针分别指向 A [ i ] A[i] A [ i ] B [ j ] B[j] B [ j ]
需要注意的是, A [ 1 ] + B [ 2 ] A[1]+B[2] A [ 1 ] + B [ 2 ] A [ 2 ] + B [ 1 ] A[2]+B[1] A [ 2 ] + B [ 1 ] A [ 2 ] + B [ 2 ] A[2]+B[2] A [ 2 ] + B [ 2 ] j j j j j j i i i A [ 1 ] + B [ 1 ] A[1]+B[1] A [ 1 ] + B [ 1 ] A [ i ] + B [ j ] A[i]+B[j] A [ i ] + B [ j ] A A A i i i B B B j j j
我们建立一个小根堆, 堆中每个节点存储一个三元组 ( i , j , l a s t ) (i, j, l a s t) ( i , j , l a s t ) l a s t last l a s t j j j A [ i ] + B [ j ] A[i]+B[j] A [ i ] + B [ j ]
起初, 堆中只有 ( 1 , 1 , f a l s e ) (1,1, false) ( 1 , 1 , f a l se )
取出堆顶 ( i , j , l a s t ) (i, j,last) ( i , j , l a s t ) ( i , j + 1 , t r u e ) (i, j+1,true) ( i , j + 1 , t r u e ) l a s t last l a s t f a l s e false f a l se ( i + 1 , j , f a l s e ) (i+1, j, false) ( i + 1 , j , f a l se )
重复上一步 N N N A [ i ] + B [ j ] A[i]+B[j] A [ i ] + B [ j ] N N N O ( N log N ) O(N \log N) O ( N log N )
回到本题, 根据数学归纳法, 我们可以先求出前 2 个序列中任取一个数相加构成的前 N N N N N N N N N M M M N N N O ( M N log N ) \mathrm{O}(M N \log N) O ( MN log N )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <queue> #include <cstdio> #include <cstring> #include <iostream> #include <algorithm> using namespace std;const int N = 2006 ;int m, n, f[N], a[N], b[N];priority_queue<pair<int , pair<int , int >>> q; void work () priority_queue<pair<int , pair<int , int >>> w; swap (w, q); q.push (make_pair (- a[1 ] - b[1 ], make_pair (1 , 1 ))); for (int i = 1 ; i <= n; i++) { f[i] = -q.top ().first; int x = q.top ().second.first, y = q.top ().second.second; q.pop (); if (y == 1 ) q.push (make_pair (- a[x+1 ] - b[y], make_pair (x + 1 , y))); q.push (make_pair (- a[x] - b[y+1 ], make_pair (x, y + 1 ))); } } void Sequence () cin >> m >> n; for (int i = 1 ; i <= n; i++) scanf ("%d" , &a[i]); sort (a + 1 , a + n + 1 ); --m; while (m--) { for (int j = 1 ; j <= n; j++) scanf ("%d" , &b[j]); sort (b + 1 , b + n + 1 ); work (); memcpy (a, f, sizeof } for (int i = 1 ; i <= n; i++) printf ("%d " , a[i]); cout << endl; } int main () int t; cin >> t; while (t--) Sequence (); return 0 ; }
Solution
你在一家 IT 公司为大型写字楼或办公楼的计算机数据做备份。
然而数据备份的工作是枯燥乏味的,因此你想设计一个系统让不同的办公楼彼此之间互相备份,而你则坐在家中尽享计算机游戏的乐趣。
已知办公楼都位于同一条街上,你决定给这些办公楼配对(两个一组)。
每一对办公楼可以通过在这两个建筑物之间铺设网络电缆使得它们可以互相备份。
然而,网络电缆的费用很高。
当地电信公司仅能为你提供 K K K K K K 2 K 2K 2 K
任意一个办公楼都属于唯一的配对组(换句话说,这 2 K 2K 2 K
此外,电信公司需按网络电缆的长度(公里数)收费。
因而,你需要选择这 K K K
换句话说,你需要选择这 K K K
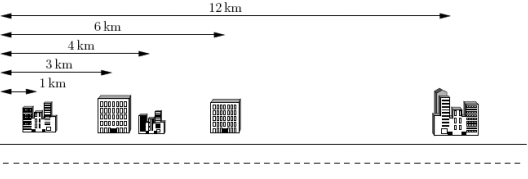
下面给出一个示例,假定你有 5 5 5
这 5 5 5 1 k m , 3 k m , 4 k m , 6 k m 1km, 3km, 4km, 6km 1 km , 3 km , 4 km , 6 km 12 k m 12km 12 km
电信公司仅为你提供 K = 2 K=2 K = 2
上例中最好的配对方案是将第 1 1 1 2 2 2 3 3 3 4 4 4
这样可按要求使用 K = 2 K=2 K = 2
第 1 1 1 3 k m − 1 k m = 2 k m 3km-1km=2km 3 km − 1 km = 2 km 2 2 2 6 k m − 4 k m = 2 k m 6km-4km=2km 6 km − 4 km = 2 km
这种配对方案需要总长 4 k m 4km 4 km
输入格式
第一行输入整数 n n n K K K n n n K K K
接下来的 n n n s s s
这些整数将按照从小到大的顺序依次出现。
输出格式
输出应由一个正整数组成,给出将 2 K 2K 2 K K K K
数据范围
2 ≤ n ≤ 100000 2 \le n \le 100000 2 ≤ n ≤ 100000 1 ≤ K ≤ n / 2 1 \le K \le n/2 1 ≤ K ≤ n /2 0 ≤ s ≤ 1000000000 0 \le s \le 1000000000 0 ≤ s ≤ 1000000000
输入样例:
输出样例:
算法分析
我们很容易发现, 最优解中每两个配对的办公楼一定是相邻的。我们求出每两个相邻办公楼之间的距离, 记为 D 1 , D 2 , D 3 , ⋯ , D N − 1 D_{1}, D_{2}, D_{3}, \cdots, D_{N-1} D 1 , D 2 , D 3 , ⋯ , D N − 1 D D D K K K K K K
如果 K = 1 K=1 K = 1 D D D K = 2 K=2 K = 2
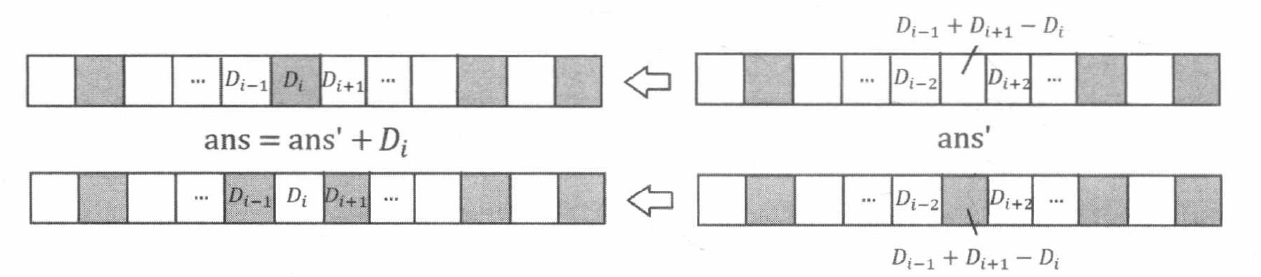
选择最小值 D i D_{i} D i D i − 1 , D i , D i + 1 D_{i-1}, D_{i}, D_{i+1} D i − 1 , D i , D i + 1
选择最小值 D i D_{i} D i D i − 1 D_{i-1} D i − 1 D i + 1 D_{i+1} D i + 1
这很容易证明: 如果 D i − 1 D_{i-1} D i − 1 D i + 1 D_{i+1} D i + 1 D i D_{i} D i D i − 1 D_{i-1} D i − 1 D i + 1 D_{i+1} D i + 1 D i D_{i} D i
通过上述证明, 我们也可以得到一个推论: 在最优解中, 最小值左右两侧的数要么同时选, 要么都不选。
因此, 我们可以先选上 D D D D i − 1 , D i , D i + 1 D_{i-1}, D_{i}, D_{i+1} D i − 1 , D i , D i + 1 D D D D i − 1 + D i + 1 − D i D_{i-1}+D_{i+1}-D_{i} D i − 1 + D i + 1 − D i D D D D D D K − 1 K-1 K − 1
在这个子问题中, 如果选了 D i − 1 + D i + 1 − D i D_{i-1}+D_{i+1}-D_{i} D i − 1 + D i + 1 − D i D i D_{i} D i D i − 1 D_{i-1} D i − 1 D i + 1 D_{i+1} D i + 1 D i D_{i} D i
综上所述, 我们得到了这样一个算法:
建立一个链表 L L L N − 1 N-1 N − 1 D 1 , D 2 , D 3 , ⋯ , D N − 1 D_{1}, D_{2}, D_{3}, \cdots, D_{N-1} D 1 , D 2 , D 3 , ⋯ , D N − 1 N − 1 N-1 N − 1 D 1 , D 2 , D 3 , ⋯ , D N − 1 D_{1}, D_{2}, D_{3}, \cdots, D_{N-1} D 1 , D 2 , D 3 , ⋯ , D N − 1
取出堆顶, 把权值累加到答案中。设堆顶对应链表节点的指针为 p p p L ( p ) L(p) L ( p ) p , p → p r e v p, p\rightarrow prev p , p → p re v p → n e x t p\rightarrow next p → n e x t q q q L ( q ) = L ( p → p r e v ) + L ( p → n e x t ) − L ( p ) L(q)=L(p\rightarrow prev )+L(p\rightarrow next )-L(p) L ( q ) = L ( p → p re v ) + L ( p → n e x t ) − L ( p ) p → p r e v p\rightarrow prev p → p re v p → n e x t p\rightarrow next p → n e x t q q q L ( q ) L(q) L ( q )
重复上述操作 K K K
Solution
Huffman 树
考虑这样一个问题: 构造一棵包含 n n n k k k i i i w i w_{i} w i ∑ w i ∗ l i \sum w_{i} * l_{i} ∑ w i ∗ l i l i l_{i} l i i i i k k k
为了最小化 ∑ w i ∗ l i \sum w_{i} * l_{i} ∑ w i ∗ l i k = 2 k=2 k = 2
建立一个小根堆, 插入这 n n n
从堆中取出最小的两个权值 w 1 w_{1} w 1 w 2 w_{2} w 2 a n s + = w 1 + w 2 ans \;+=w_{1}+w_{2} an s + = w 1 + w 2
建立一个权值为 w 1 + w 2 w_{1}+w_{2} w 1 + w 2 p p p p p p w 1 w_{1} w 1 w 2 w_{2} w 2
在堆中插入权值 w 1 + w 2 w_{1}+w_{2} w 1 + w 2
重复第 2 ∼ 4 2 \sim 4 2 ∼ 4
最后, 由所有新建的 p p p ∑ w i ∗ l i \sum w_{i} * l_{i} ∑ w i ∗ l i
对于 k ( k > 2 ) k(k>2) k ( k > 2 ) k k k 2 ∼ k − 1 2 \sim k-1 2 ∼ k − 1 k k k k k k ∑ w i ∗ l i \sum w_{i} * l_{i} ∑ w i ∗ l i
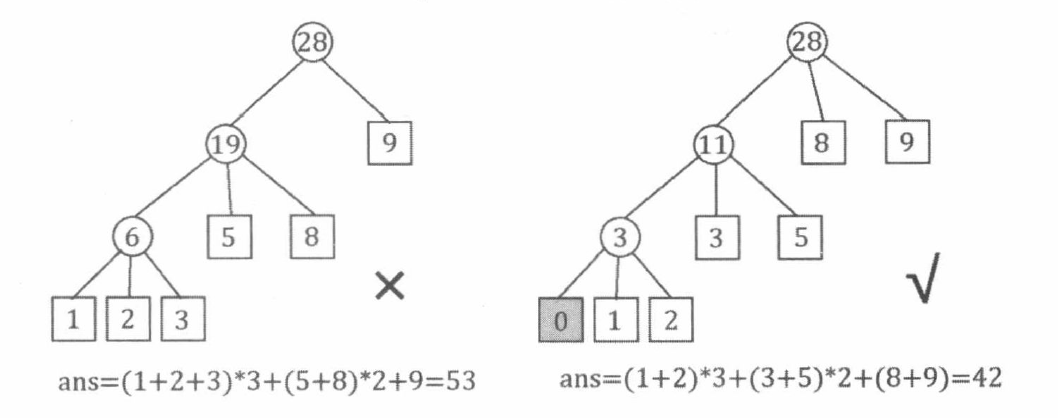
因此, 我们应该在执行上述贪心算法之前, 补加一些额外的权值为 0 的叶子节点, 使叶子节点的个数 n n n ( n − 1 ) m o d ( k − 1 ) = 0 (n-1) \bmod (k-1)=0 ( n − 1 ) mod ( k − 1 ) = 0 k k k ( n − 1 ) m o d ( k − 1 ) = 0 (n-1) \bmod (k-1)=0 ( n − 1 ) mod ( k − 1 ) = 0 k k k
在一个果园里,达达已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。
达达决定把所有的果子合成一堆。
每一次合并,达达可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。
可以看出,所有的果子经过 n − 1 n-1 n − 1
达达在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以达达在合并果子时要尽可能地节省体力。
假定每个果子重量都为 1 1 1
例如有 3 3 3 1 , 2 , 9 1,2,9 1 , 2 , 9
可以先将 1 、 2 1、2 1 、 2 3 3 3 3 3 3
接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 12 12 12 12 12 12
所以达达总共耗费体力= 3 + 12 = 15 =3+12=15 = 3 + 12 = 15
可以证明 15 15 15
输入格式
输入包括两行,第一行是一个整数 n n n
第二行包含 n n n i i i a i a_i a i i i i
输出格式
输出包括一行,这一行只包含一个整数,也就是最小的体力耗费值。
输入数据保证这个值小于 2 31 2^{31} 2 31
数据范围
1 ≤ n ≤ 10000 1 \le n \le 10000 1 ≤ n ≤ 10000 1 ≤ a i ≤ 20000 1 \le a_i \le 20000 1 ≤ a i ≤ 20000
输入样例:
输出样例:
算法分析
因为每次合并消耗的体力等于两堆果子的重量之和, 所以最终消耗的体力总和就是每堆果子的重量乘它参与合并的次数。这恰好对应一个二叉 Huffman 树问题, 果子堆的重量就是叶子节点的权值, 参与合并的次数就是叶子到根的距离。
建立一个小根堆, 揷入所有果子堆的重量。不断取出堆中最小的两个值, 把它们的 和揷入堆, 同时累加到答案中。直至最后堆的大小为 1 时, 输出答案即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <queue> #include <cstdio> #include <iostream> using namespace std;priority_queue<int > q; int main () int n, a; cin >> n; while (n--) { scanf ("%d" , &a); q.push (-a); } int ans = 0 ; while (q.size () != 1 ) { int x = -q.top (); q.pop (); int y = -q.top (); q.pop (); ans += x + y; q.push (- x - y); } cout << ans << endl; return 0 ; }
Solution
追逐影子的人,自己就是影子。 ——荷马
达达最近迷上了文学。
她喜欢在一个慵懒的午后,细细地品上一杯卡布奇诺,静静地阅读她爱不释手的《荷马史诗》。
但是由《奥德赛》和《伊利亚特》组成的鸿篇巨制《荷马史诗》实在是太长了,达达想通过一种编码方式使得它变得短一些。
一部《荷马史诗》中有 n n n 1 1 1 n n n i i i w i w_i w i
达达想要用 k k k s i s_i s i i i i
对于任意的 1 ≤ i , j ≤ n , i ≠ j 1≤i,j≤n,i≠j 1 ≤ i , j ≤ n , i = j s i s_i s i s j s_j s j
现在达达想要知道,如何选择 s i s_i s i
在确保总长度最小的情况下,达达还想知道最长的 s i s_i s i
一个字符串被称为 k k k 0 0 0 k − 1 k−1 k − 1 0 0 0 k − 1 k−1 k − 1
字符串 S t r 1 Str1 St r 1 S t r 2 Str2 St r 2 1 ≤ t ≤ m 1≤t≤m 1 ≤ t ≤ m S t r 1 = S t r 2 [ 1.. t ] Str1=Str2[1..t] St r 1 = St r 2 [ 1.. t ]
其中,m m m S t r 2 Str2 St r 2 S t r 2 [ 1.. t ] Str2[1..t] St r 2 [ 1.. t ] S t r 2 Str2 St r 2 t t t
注意 :请使用 64 64 64
输入格式
输入文件的第 1 1 1 2 2 2 n , k n,k n , k n n n k k k
第 2 ∼ n + 1 2 \sim n+1 2 ∼ n + 1 i + 1 i+1 i + 1 1 1 1 w i w_i w i i i i
输出格式
输出文件包括 2 2 2
第 1 1 1 1 1 1
第 2 2 2 1 1 1 s i s_i s i
数据范围
2 ≤ n ≤ 100000 2 \le n \le 100000 2 ≤ n ≤ 100000 2 ≤ k ≤ 9 2 \le k \le 9 2 ≤ k ≤ 9 1 ≤ w i ≤ 1 0 12 1 \le w_i \le 10^{12} 1 ≤ w i ≤ 1 0 12
输入样例:
输出样例:
算法分析
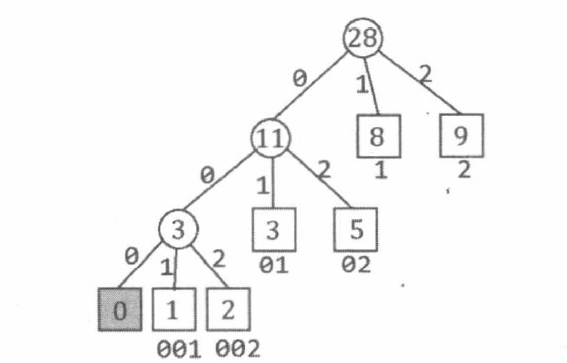
本题所构造的编码方式其实就是 Huffman 编码。我们把单词的出现次数 w 1 ∼ w n w_{1} \sim w_{n} w 1 ∼ w n k k k k k k 0 ∼ k − 1 0 \sim k-1 0 ∼ k − 1
此时, 如果把这棵 Huffman 树看作一棵 Trie 树, 就得到了使总长度最小的编码方式——单词 i i i i i i
本题还要求最长的 s i s_{i} s i
Solution