参考《算法竞赛进阶指南》 、AcWing题库
递推与递归
一个实际问题的各种可能情况构成的集合通常称为 “状态空间”, 而程序的运行则是对于状态空间的遍历, 算法和数据结构则通过划分、归纳、提取、抽象来帮助提高程序遍历状态空间的效率。递推和递归就是程序遍历状态空间的两种基本方式。
递推与递归的宏观描述
对于一个待求解的问题, 当它局限在某处边界、某个小范围或者某种特殊情形下时, 其答案往往是已知的。如果能够将该解答的应用场景扩大到原问题的状态空间, 并且扩展过程的每个步骤具有相似性, 就可以考虑使用递推或者递归求解。
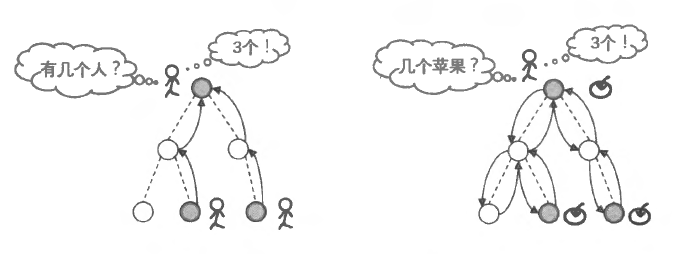
以已知的 “问题边界” 为起点向 “原问题” 正向推导的扩展方式就是递推。然而在很多时候, 推导的路线难以确定, 这时以 “原问题” 为起点尝试寻找把状态空问缩小到已知的 “问题边界” 的路线, 再通过该路线反向回溯的遍历方式就是递归。我们通过两幅图来表示递推与递归的差别。
我们刚才也提到, 使用递推或递归要求 “原问题” 与 “问题边界” 之间的每个变换步骤具有相似性, 这样我们才能够设计一段程序实现这个步骤, 将其重复作用于问题之中。换句话说, 程序在每个步骤上应该面对相同种类的问题, 这些问题都是原问题的一个子问题, 可能仅在规模或者某些限制条件上有所区别, 并且能够使用 “求解原问题的程序” 进行求解。
对于递归算法,有 了上面这个前提,我们就可以让程序在每个变换步骤中执行三个操作:
缩小问题状态空间的规模。这意味着程序尝试寻找在 “原问题” 与 “问题边界” 之间的变换路线, 并向正在探索的路线上迈出一步。
尝试求解规模缩小以后的问题, 结果可能是成功, 也可能是失败。
如果成功, 即找到了规模缩小后的问题的答案, 那么将答案扩展到当前问题。如果失败, 那么重新回到当前问题, 程序可能会继续寻找当前问题的其他变换路线, 直至最终确定当前问题无法求解。
在以上三个操作中有两点颇为关键。
一是 “如何尝试求解规模缩小以后的问题”。因为规模缩小以后的问题是原问题的一个子问题, 所以我们可以把它视为一个新的 “原问题” 由相同的程序 (上述三个操作)进行求解, 这就是所谓的 “自身调用自身”。
二是如果求解子问题失败, 程序需要重新回到当前问题去寻找其他的变换路线, 因此把当前问题缩小为子问题时所做的对当前问题状态产生影响的事情应该全部失效, 这就是所谓的 “回溯时还原现场”。
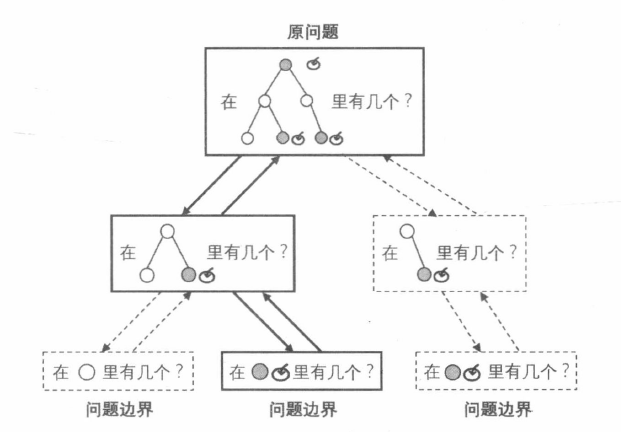
上面这类程序就是 “递归” 的遍历方式, 其整体流程如下图所示。
可以看到, 递归程序的基本单元是由 “缩小” “求解” “扩展” 组成的一种变换步骤, 只是在 “求解” 时因为问题的相似性, 不断重复使用了这样一种变换步骤, 直至在已知的问题边界上直接确定答案。对于其中任意一条从 “原问题” 到 “问题边界” 的变换路线 (图中实线圈出的路径), 横向来看, 它的每一层是一次递归程序体的执行; 纵向来看, 它的左右两边分别是寻找路线和沿其推导的流程。为了保证每层的 “缩小” 与 “扩展” 能够衔接在同一形式的问题上, “求解” 操作自然要保证在执行前后程序面对问题的状态是相同的, 这也就是 “还原现场” 的必要性所在。
递推与递归的简单应用
在使用枚举算法蛮力探索问题的整个 “状态空间” 时, 经常需要递归。按照规模大小, 有如下几种常见的枚举形式和遍历方式:
枚举形式
状态空间规模
一般遍历方式
多项式
n k , k n^k,\;k n k , k 循环(for)、递推
指 数
k n , k k^{n},\;k k n , k 递归、位运算
排 列
n ! n! n ! 递归、C++ next_permutation
组 合
C n m C_n^{m} C n m 递归+剪枝
“多项式” 型的枚举在程序设计中随处可见。
从 1 ∼ n 1 \sim n 1 ∼ n n n n
输入格式
输入一个整数 n n n
输出格式
每行输出一种方案。
同一行内的数必须升序排列,相邻两个数用恰好 1 1 1
对于没有选任何数的方案,输出空行。
本题有自定义校验器(SPJ),各行(不同方案)之间的顺序任意。
数据范围
1 ≤ n ≤ 15 1 \le n \le 15 1 ≤ n ≤ 15
输入样例:
输出样例:
算法分析
这等价于每个整数可以选可以不选, 所有可能的方案总数共有 2 n 2^{n} 2 n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vector<int > chosen; void calc (int x) if (x == n + 1 ) { for (int i = 0 ; i < chosen.size (); i++) printf ("%d " , chosen[i]); puts ("" ); return ; } calc (x + 1 ); chosen.push_back (x); calc (x + 1 ); chosen.pop_back (); } int main () calc (1 ); }
Solution
从 1 ∼ n 1 \sim n 1 ∼ n n n n m m m
输入格式
两个整数 n , m n, m n , m
输出格式
按照从小到大的顺序输出所有方案,每行 1 1 1
首先,同一行内的数升序排列,相邻两个数用一个空格隔开。
其次,对于两个不同的行,对应下标的数一一比较,字典序较小的排在前面(例如 1 3 5 7 排在 1 3 6 8 前面)。
数据范围
n > 0 n>0 n > 0 0 ≤ m ≤ n 0 \le m \le n 0 ≤ m ≤ n n + ( n − m ) ≤ 25 n+(n-m) \le 25 n + ( n − m ) ≤ 25
输入样例:
输出样例:
1 2 3 4 5 6 7 8 9 10 1 2 3 1 2 4 1 2 5 1 3 4 1 3 5 1 4 5 2 3 4 2 3 5 2 4 5 3 4 5
思考题 :如果要求使用非递归方法,该怎么做呢?
算法分析
我们只需要在上面指数型枚举的程序的 calc 函数开头添加以下这条语句即可:
1 if (chosen.size () > m || chosen.size () + (n - x + 1 ) < m) return ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vector<int > chosen; void calc (int x) if (chosen.size () > m || chosen.size () + (n - x + 1 ) < m) return ; if (x == n + 1 ) { for (int i = 0 ; i < chosen.size (); i++) printf ("%d " , chosen[i]); puts ("" ); return ; } calc (x + 1 ); chosen.push_back (x); calc (x + 1 ); chosen.pop_back (); }
这就是所谓的 “剪枝” 。寻找变换路线其实就是 “搜索” 的过程, 如果能够及时确定当前问题一定是无解的, 就不需要到达问题边界才返回结果。在本题中, 如果已经选择了超过 m m m m m m 2 n 2^{n} 2 n C n m C_{n}^{m} C n m
Solution
算法分析
该问题也被称为全排列问题, 所有可能的方案总数有 n ! n ! n ! n n n n − 1 n-1 n − 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <vector> using namespace std;int n;int order[20 ]; bool chosen[20 ]; void calc (int k) if (k == n + 1 ) { for (int i = 1 ; i <= n; i++) printf ("%d " , order[i]); puts ("" ); return ; } for (int i = 1 ; i <= n; i++) { if (chosen[i]) continue ; order[k] = i; chosen[i] = 1 ; calc (k + 1 ); chosen[i] = 0 ; order[k] = 0 ; } } int main () cin >> n; calc (1 ); }
Solution
你玩过“拉灯”游戏吗?
25 25 25 5 × 5 5 \times 5 5 × 5
每一个灯都有一个开关,游戏者可以改变它的状态。
每一步,游戏者可以改变某一个灯的状态。
游戏者改变一个灯的状态会产生连锁反应:和这个灯上下左右相邻的灯也要相应地改变其状态。
我们用数字 1 1 1 0 0 0
下面这种状态
1 2 3 4 5 10111 01101 10111 10000 11011
在改变了最左上角的灯的状态后将变成:
1 2 3 4 5 01111 11101 10111 10000 11011
再改变它正中间的灯后状态将变成:
1 2 3 4 5 01111 11001 11001 10100 11011
给定一些游戏的初始状态,编写程序判断游戏者是否可能在 6 6 6
输入格式
第一行输入正整数 n n n n n n
以下若干行数据分为 n n n 5 5 5 5 5 5
每组数据描述了一个游戏的初始状态。
各组数据间用一个空行分隔。
输出格式
一共输出 n n n 6 6 6
对于某一个游戏初始状态,若 6 6 6 − 1 -1 − 1
数据范围
0 < n ≤ 500 0 < n \le 500 0 < n ≤ 500
输入样例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 3 00111 01011 10001 11010 11100 11101 11101 11110 11111 11111 01111 11111 11111 11111 11111
输出样例:
算法分析
在上述规则的 01 矩阵的点击游戏中, 很容易发现三个性质:
每个位置至多只会被点击一次。
若固定了第一行 (不能再改变第一行), 则满足题意的点击方案至多只有 1 种。 其原因是:当第 i i i i i i i + 1 i+1 i + 1 i i i
点击的先后顺序不影响最终结果。
于是, 我们不妨先考虑第一行如何点击。在枚举第一行的点击方法 ( 2 5 = 32 2^{5}=32 2 5 = 32 2 ∼ 5 2 \sim 5 2 ∼ 5 2 ∼ 5 2 \sim 5 2 ∼ 5 i i i i + 1 i+1 i + 1 n n n
对于第一行点击方法的枚举, 可以采用位运算的方式, 枚举 0 ∼ 31 0 \sim 31 0 ∼ 31 k ( 0 ≤ k < 5 ) k(0 \leq k<5) k ( 0 ≤ k < 5 ) k + 1 k+1 k + 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <cstring> #include <iostream> using namespace std;const int N = 6 ;int a[N], ans, aa[N];char s[N];void dj (int x, int y) aa[x] ^= (1 << y); if (x != 1 ) aa[x-1 ] ^= (1 << y); if (x != 5 ) aa[x+1 ] ^= (1 << y); if (y != 0 ) aa[x] ^= (1 << (y - 1 )); if (y != 4 ) aa[x] ^= (1 << (y + 1 )); } void pd (int p) int k = 0 ; memcpy (aa, a, sizeof for (int i = 0 ; i < 5 ; i++) if (!((p >> i) & 1 )) { dj (1 , i); if (++k >= ans) return ; } for (int x = 1 ; x < 5 ; x++) for (int y = 0 ; y < 5 ; y++) if (!((aa[x] >> y) & 1 )) { dj (x + 1 , y); if (++k >= ans) return ; } if (aa[5 ] == 31 ) ans = k; } void abc () memset (a, 0 , sizeof for (int i = 1 ; i <= 5 ; i++) { cin >> (s + 1 ); for (int j = 1 ; j <= 5 ; j++) a[i] = a[i] * 2 + (s[j] - '0' ); } ans = 7 ; for (int p = 0 ; p < (1 << 5 ); p++) pd (p); if (ans == 7 ) cout << "-1" << endl; else cout << ans << endl; } int main () int n; cin >> n; while (n--) abc (); return 0 ; }
Solution
汉诺塔问题,条件如下:
1、这里有 A 、 B 、 C A、B、C A 、 B 、 C D D D
2、这里有 n n n n n n
3、每个圆盘的尺寸都不相同。
4、所有的圆盘在开始时都堆叠在塔 A A A
5、我们需要将所有的圆盘都从塔 A A A D D D
6、每次可以移动一个圆盘,当塔为空塔或者塔顶圆盘尺寸大于被移动圆盘时,可将圆盘移至这座塔上。
请你求出将所有圆盘从塔 A A A D D D
输入格式
没有输入
输出格式
对于每一个整数 n n n
数据范围
1 ≤ n ≤ 12 1 \le n \le 12 1 ≤ n ≤ 12
输入样例:
输出样例:
算法分析
首先考虑 n n n d [ n ] d[n] d [ n ] n n n d [ n ] = 2 ∗ d [ n − 1 ] + 1 d[n]=2 * d[n-1]+1 d [ n ] = 2 ∗ d [ n − 1 ] + 1 n − 1 n-1 n − 1 B \mathrm{B} B n n n A \mathrm{A} A C \mathrm{C} C n − 1 n-1 n − 1 B \mathrm{B} B
回到本题, 设 f [ n ] f[n] f [ n ] n n n
f [ n ] = min 1 ≤ i < n { 2 ∗ f [ i ] + d [ n − i ] } f[n]=\min _{1 \leq i<n}\{2 * f[i]+d[n-i]\}
f [ n ] = 1 ≤ i < n min { 2 ∗ f [ i ] + d [ n − i ]}
其中 f [ 1 ] = 1 f[1]=1 f [ 1 ] = 1 i i i B \mathrm{B} B n − i n-i n − i i i i i i i
在时间复杂度可以接受的前提下, 上述做法可以推广到 n n n m m m
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <cstring> #include <iostream> #include <algorithm> #define ll long long using namespace std;const int N = 15 ;ll d[N], f[N]; int main () int n = 12 ; memset (f, 0x3f , sizeof d[1 ] = f[1 ] = 1 ; for (int i = 2 ; i <= n; i++) d[i] = 2 * d[i-1 ] + 1 ; for (int i = 2 ; i <= n; i++) for (int j = 1 ; j < i; j++) f[i] = min (f[i], 2 * f[j] + d[i-j]); for (int i = 1 ; i <= n; i++) cout << f[i] << endl; return 0 ; }
Solution
分治
分治法把一个问题划分为若干个规模更小的同类子问题, 对这些子问题递归求解, 然后在回溯时通过它们推导出原问题的解。
假设现在有两个自然数 A A A B B B S S S A B A^B A B
请你求出 S m o d 9901 S \bmod 9901 S mod 9901
输入格式
在一行中输入用空格隔开的两个整数 A A A B B B
输出格式
输出一个整数,代表 S m o d 9901 S \bmod 9901 S mod 9901
数据范围
0 ≤ A , B ≤ 5 × 1 0 7 0 \le A,B \le 5 \times 10^7 0 ≤ A , B ≤ 5 × 1 0 7
输入样例:
输出样例:
注意 : A A A B B B 0 0 0
算法分析
把 A A A p 1 c 1 ∗ p 2 c 2 ∗ ⋯ ∗ p n c n p_{1}^{c_{1}} * p_{2}^{c_{2}} * \cdots * p_{n}^{c_{n}} p 1 c 1 ∗ p 2 c 2 ∗ ⋯ ∗ p n c n A B A^{B} A B p 1 B ∗ c 1 ∗ p 2 B ∗ c 2 ∗ ⋯ ∗ p n B ∗ c n p_{1}^{B * c_{1}} * p_{2}^{B * c_{2}} * \cdots * p_{n}^{B * c_{n}} p 1 B ∗ c 1 ∗ p 2 B ∗ c 2 ∗ ⋯ ∗ p n B ∗ c n A B A^{B} A B { p 1 k 1 ∗ p 2 k 2 ∗ ⋯ ∗ p n k n } \left\{p_{1}^{k_{1}} * p_{2}^{k_{2}} * \cdots * p_{n}^{k_{n}}\right\} { p 1 k 1 ∗ p 2 k 2 ∗ ⋯ ∗ p n k n } 0 ≤ k i ≤ B ∗ c i ( 1 ≤ i ≤ n ) 0 \leq k_{i} \leq B * c_{i}(1 \leq i \leq n) 0 ≤ k i ≤ B ∗ c i ( 1 ≤ i ≤ n )
根据乘法分配律, A B A^{B} A B
( 1 + p 1 + p 1 2 + ⋯ + p 1 B ∗ c 1 ) ∗ ( 1 + p 2 + p 2 2 + ⋯ + p 2 B ∗ c 2 ) ∗ ⋯ ∗ ( 1 + p n + p n 2 + ⋯ + p n B ∗ c n ) \begin{gathered}
\left(1+p_{1}+p_{1}^{2}+\cdots+p_{1}^{B * c_{1}}\right) *\left(1+p_{2}+p_{2}^{2}+\cdots+p_{2}^{B * c_{2}}\right) * \cdots \\
*\left(1+p_{n}+p_{n}^{2}+\cdots+p_{n}^{B * c_{n}}\right)
\end{gathered}
( 1 + p 1 + p 1 2 + ⋯ + p 1 B ∗ c 1 ) ∗ ( 1 + p 2 + p 2 2 + ⋯ + p 2 B ∗ c 2 ) ∗ ⋯ ∗ ( 1 + p n + p n 2 + ⋯ + p n B ∗ c n )
我们可以把该式展开, 与约数集合比较。
上式中的每个括号内都是等比数列, 如果使用等比数列求和公式, 需要做除法。而答案还需要对 9901 取模, mod 运算只对加、减、乘有分配率, 不能直接对分子、分母分别取模后再做除法。我们可以换一种思路, 使用分治法进行等比数列求和。
问题: 使用分治法求 sum ( p , c ) = 1 + p + p 2 + ⋯ + p c = ? \operatorname{sum}(p, c)=1+p+p^{2}+\cdots+p^{c}=? sum ( p , c ) = 1 + p + p 2 + ⋯ + p c = ?
若 c c c
sum ( p , c ) = ( 1 + p + ⋯ + p c − 1 2 ) + ( p c + 1 2 + ⋯ + p c ) = ( 1 + p + ⋯ + p c − 1 2 ) + p c + 1 2 ∗ ( 1 + p + ⋯ + p c − 1 2 ) = ( 1 + p c + 1 2 ) ∗ sum ( p , c − 1 2 ) \begin{aligned}
\operatorname{sum}(p, c)=(1&\left.+p+\cdots+p^{\frac{c-1}{2}}\right)+\left(p^{\frac{c+1}{2}}+\cdots+p^{c}\right) \\
&=\left(1+p+\cdots+p^{\frac{c-1}{2}}\right)+p^{\frac{c+1}{2}} *\left(1+p+\cdots+p^{\frac{c-1}{2}}\right) \\
&=\left(1+p^{\frac{c+1}{2}}\right) * \operatorname{sum}\left(p, \frac{c-1}{2}\right)
\end{aligned}
sum ( p , c ) = ( 1 + p + ⋯ + p 2 c − 1 ) + ( p 2 c + 1 + ⋯ + p c ) = ( 1 + p + ⋯ + p 2 c − 1 ) + p 2 c + 1 ∗ ( 1 + p + ⋯ + p 2 c − 1 ) = ( 1 + p 2 c + 1 ) ∗ sum ( p , 2 c − 1 )
若 c c c
sum ( p , c ) = ( 1 + p c 2 ) ∗ sum ( p , c 2 − 1 ) + p c \operatorname{sum}(p, c)=\left(1+p^{\frac{c}{2}}\right) * \operatorname{sum}\left(p, \frac{c}{2}-1\right)+p^{c}
sum ( p , c ) = ( 1 + p 2 c ) ∗ sum ( p , 2 c − 1 ) + p c
每次分治 (递归之后), 问题规模均会缩小一半, 配合快速幂即可在 O ( log c ) \mathrm{O}(\log c) O ( log c )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <vector> #include <iostream> #define ll long long using namespace std;const ll P = 9901 ;vector<pair<ll, ll> > w; ll ksm (ll a, ll b) { ll ans = 1 ; a %= P; while (b) { if (b & 1 ) (ans *= a) %= P; (a *= a) %= P; b >>= 1 ; } return ans; } ll get_sum (ll p, ll c) { if (!p) return 0 ; if (!c) return 1 ; if (c & 1 ) return (ksm (p, (c + 1 ) / 2 ) + 1 ) * get_sum (p, c / 2 ) % P; return ((ksm (p, c / 2 ) + 1 ) * get_sum (p, c / 2 - 1 ) + ksm (p, c)) % P; } void fj (ll a) for (ll i = 2 ; i * i <= a; i++) if (!(a % i)) { ll num = 0 ; while (!(a % i)) { num++; a /= i; } w.push_back (make_pair (i, num)); } if (a != 1 ) w.push_back (make_pair (a, 1 )); } int main () ll a, b; cin >> a >> b; fj (a); ll ans = 1 ; for (unsigned ll i = 0 ; i < w.size (); i++) { ll p = w[i].first, c = w[i].second; (ans *= get_sum (p, b * c)) %= P; } cout << ans << endl; return 0 ; }
Solution
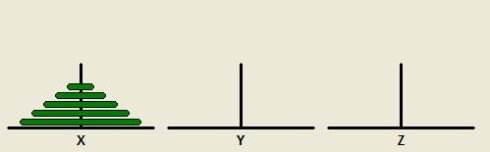
分形
城市的规划在城市建设中是个大问题。
不幸的是,很多城市在开始建设的时候并没有很好的规划,城市规模扩大之后规划不合理的问题就开始显现。
而这座名为 Fractal 的城市设想了这样的一个规划方案,如下图所示:
当城区规模扩大之后,Fractal 的解决方案是把和原来城区结构一样的区域按照图中的方式建设在城市周围,提升城市的等级。
对于任意等级的城市,我们把正方形街区从左上角开始按照道路标号。
虽然这个方案很烂,Fractal 规划部门的人员还是想知道,如果城市发展到了等级 N N N A A A B B B
街区的距离指的是街区的中心点之间的距离,每个街区都是边长为 10 10 10
输入格式
第一行输入正整数 n n n
以下 n n n n n n
每组数据包括三个整数 N , A , B N, A, B N , A , B
输出格式
一共输出 n n n
数据范围
1 ≤ N ≤ 31 1 \le N \le 31 1 ≤ N ≤ 31 1 ≤ A , B ≤ 2 2 N 1 \le A,B \le 2^{2N} 1 ≤ A , B ≤ 2 2 N 1 ≤ n ≤ 1000 1 \le n \le 1000 1 ≤ n ≤ 1000
输入样例:
1 2 3 4 3 1 1 2 2 16 1 3 4 33
输出样例:
算法分析
这就是著名的通过一定规律无限包含自身的 “分形” 图。为了计算方便, 我们把题目中房屋的编号都减去 1 , 即从 0 开始编号, 并把 S S S D D D
本题关键是要解决:求编号为 M M M N N N calc ( N , M ) \operatorname{calc}(N, M) calc ( N , M ) calc ( N , S ) \operatorname{calc}(N, S) calc ( N , S ) calc ( N , D ) \operatorname{calc}(N, D) calc ( N , D )
不难看出, N ( N > 1 ) N(N>1) N ( N > 1 ) N − 1 N-1 N − 1 N − 1 N-1 N − 1 N − 1 N-1 N − 1 N − 1 N-1 N − 1 N − 1 N-1 N − 1
在求解 calc ( N , M ) \operatorname{calc}(N, M) calc ( N , M ) N − 1 N-1 N − 1 2 2 N − 2 2^{2 N-2} 2 2 N − 2 calc ( N − 1 , M m o d 2 2 N − 2 ) \operatorname{calc}\left(N-1, M \bmod 2^{2 N-2}\right) calc ( N − 1 , M mod 2 2 N − 2 ) ( x , y ) (x, y) ( x , y ) x x x y y y M / 2 2 N − 2 M / 2^{2 N-2} M / 2 2 N − 2 M M M N − 1 N-1 N − 1
若处于左上的 N − 1 N-1 N − 1 ( x , y ) (x, y) ( x , y ) N − 1 N-1 N − 1 ( y , 2 N − 1 − x − 1 ) \left(y, 2^{N-1}-x-1\right) ( y , 2 N − 1 − x − 1 ) ( y , x ) (y, x) ( y , x ) N N N
若处于右上的 N − 1 N-1 N − 1 N N N ( x , y + (x, y+ ( x , y + 2 N − 1 ) \left.2^{N-1}\right) 2 N − 1 )
若处于右下的 N − 1 N-1 N − 1 N N N ( x + (x+ ( x + 2 N − 1 , y + 2 N − 1 ) \left.2^{N-1}, y+2^{N-1}\right) 2 N − 1 , y + 2 N − 1 )
若处于左下的 N − 1 N-1 N − 1 ( x , y ) (x, y) ( x , y ) N − 1 N-1 N − 1 ( 2 N − 1 − y − 1 , 2 N − 1 − x − 1 ) \left(2^{N-1}-y-1,2^{N-1}-x-1\right) ( 2 N − 1 − y − 1 , 2 N − 1 − x − 1 ) N N N 2 N − 1 2^{N-1} 2 N − 1 ( 2 N − y − 1 , 2 N − 1 − x − 1 ) \left(2^{N}-y-1,2^{N-1}-x-1\right) ( 2 N − y − 1 , 2 N − 1 − x − 1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <cmath> #include <cstdio> #include <cstring> #include <algorithm> using namespace std;pair<long long , long long > calc (int n, long long m) { if (n == 0 ) return make_pair (0 , 0 ); long long len = 1ll << (n - 1 ), cnt = 1ll << (2 * n - 2 ); pair<long long , long long > pos = calc (n - 1 , m % cnt); long long x = pos.first, y = pos.second; long long z = m / cnt; if (z == 0 ) return make_pair (y, x); if (z == 1 ) return make_pair (x, y + len); if (z == 2 ) return make_pair (x + len, y + len); if (z == 3 ) return make_pair (2 * len - y - 1 , len - x - 1 ); } int main () int data; for (scanf ("%d" , &data); data; --data) { int n; long long h, o; scanf ("%d %I64d %I64d" , &n, &h, &o); pair<long long , long long > hp = calc (n, h - 1 ); pair<long long , long long > op = calc (n, o - 1 ); long long dx = hp.first - op.first, dy = hp.second - op.second; printf ("%.0f\n" , (double )sqrt (dx * dx + dy * dy) * 10 ); } return 0 ; }
Solution
递归的机器实现
递归在计算机中是如何实现的? 换句话说, 它最终被编译成什么样的机器语言? 这就要从函数调用说起。实际上, 一台典型的 32 位计算机采用 “堆栈结构” 来实现函数调用, 它在汇编语言中, 把函数所需的第 k k k k − 1 k-1 k − 1 ⋯ \cdots ⋯
对于函数中定义的 C++局部变量, 在每次执行 call 与 ret 指令时, 也会在 “栈” 中相应地保存与复原, 而作用范围超过该函数的变量, 以及通过 new 和 malloc 函数动态分配的空间则保存在另一块称为 “堆” (注意, 这个堆与我们所说的二叉堆是两个不同的概念) 的结构中。栈指针、返回值、局部的运算会借助 CPU 的 “寄存器” 完成。
由此我们可以得知:
局部变量在每层递归中都占有一份空间, 声明过多或递归过深就会超过 “栈”所能存储的范围, 造成栈溢出。
非局部变量对于各层递归都共享同一份空间, 需要及时维护、还原现场, 以防止在各层递归之间存储和读取的数据互相影响。
了解了递归的机器实现之后, 我们就可以使用模拟的方法, 把递归程序改写为非递归程序。具体来说, 我们可以使用一个数组来模拟栈, 使用变量来模拟栈指针和返回值,使用 switch/case 或者 goto/label 来模拟语句跳转。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <vector> using namespace std;vector<int > chosen; int stack[100010 ], top = 0 , address = 0 , n, m;void call (int x, int ret_addr) int old_top = top; stack[++top] = x; stack[++top] = ret_addr; stack[++top] = old_top; } int ret () int ret_addr = stack[top - 1 ]; top = stack[top]; return ret_addr; } int main () cin >> n >> m; call (1 , 0 ); while (top) { int x = stack[top - 2 ]; switch case 0 : if (chosen.size ()>m || chosen.size ()+(n-x+1 )<m) { address = ret (); continue ; } if (x == n + 1 ) { for (int i = 0 ; i < chosen.size (); i++) printf ("%d " , chosen[i]); puts ("" ); address = ret (); continue ; } chosen.push_back (x); call (x+1 , 1 ); address = 0 ; continue ; case 1 : chosen.pop_back (); call (x+1 , 2 ); address = 0 ; continue ; case 2 : address = ret (); } } }