参考《算法竞赛进阶指南》 、AcWing题库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class BIT {public : vector<int > c; int n; BIT () {} BIT (int n) { this ->n = n; c.resize (n + 1 ); } BIT (vector<int > &a) { int n = a.size () + 1 ; c.resize (n); for (int i = 1 ; i <= n; ++i) { auto val = a[i - 1 ]; c[i] += val; if (i + lowbit (i) <= n) c[i + lowbit (i)] += c[i]; } } void add (int x, int w) for (; x <= n; x += lowbit (x)) c[x] += w; } int askSum (int x) int ans = 0 ; for (; x; x -= lowbit (x)) ans += c[x]; return ans; } int lowbit (int x) return x & -x; } };
树状数组
在基本算法中, 我们详细探讨了位运算、二分、倍增等贯穿于各种数据结构设计始末的思想。无论是二进制、折半还是翻倍, 都与 “二” 这个数字密切相关。请读者回想倍增一文的 ST 表, 在对一个较大的连续线性范围进行统计时, 我们把它按照 2 的整数次幂分成若干个小范围进行预处理和计算。再回想位运算一文的快速幂算法, 根据任意正整数关于 2 的不重复次幂的唯一分解性质, 若一个正整数 x x x a k − 1 a k − 2 ⋯ a 2 a 1 a 0 a_{k-1} a_{k-2} \cdots a_{2} a_{1} a_{0} a k − 1 a k − 2 ⋯ a 2 a 1 a 0 { a i 1 , a i 2 , ⋯ , a i m } \left\{a_{i_{1}}, a_{i_{2}}, \cdots, a_{i_{m}}\right\} { a i 1 , a i 2 , ⋯ , a i m } x x x
x = 2 i 1 + 2 i 2 + ⋯ + 2 i m x=2^{i_{1}}+2^{i_{2}}+\cdots+2^{i_{m}}
x = 2 i 1 + 2 i 2 + ⋯ + 2 i m
不妨设 i 1 > i 2 > ⋯ > i m i_{1}>i_{2}>\cdots>i_{m} i 1 > i 2 > ⋯ > i m [ 1 , x ] [1, x] [ 1 , x ] O ( log x ) O(\log x) O ( log x )
长度为 2 i 1 2^{i_{1}} 2 i 1 [ 1 , 2 i 1 ] \left[1,2^{i_{1}}\right] [ 1 , 2 i 1 ]
长度为 2 i 2 2^{i_{2}} 2 i 2 [ 2 i 1 + 1 , 2 i 1 + 2 i 2 ] \left[2^{i_{1}}+1,2^{i_{1}}+2^{i_{2}}\right] [ 2 i 1 + 1 , 2 i 1 + 2 i 2 ]
长度为 2 i 3 2^{i_{3}} 2 i 3 [ 2 i 1 + 2 i 2 + 1 , 2 i 1 + 2 i 2 + 2 i 3 ] \left[2^{i_{1}}+2^{i_{2}}+1,2^{i_{1}}+2^{i_{2}}+2^{i_{3}}\right] [ 2 i 1 + 2 i 2 + 1 , 2 i 1 + 2 i 2 + 2 i 3 ] 2 i m 2^{i_{m}} 2 i m [ 2 i 1 + 2 i 2 + ⋯ + 2 i m − 1 + 1 , 2 i 1 + 2 i 2 + ⋯ + 2 i m ] \left[2^{i_{1}}+2^{i_{2}}+\cdots+2^{i_{m-1}}+1,2^{i_{1}}+2^{i_{2}}+\cdots+2^{i_{m}}\right] [ 2 i 1 + 2 i 2 + ⋯ + 2 i m − 1 + 1 , 2 i 1 + 2 i 2 + ⋯ + 2 i m ]
[x - lowbit(x) + 1, x] = (x - lowbit(x), x]
这些小区间的共同特点是:若区间结尾为 R R R R R R lowbit ( R ) \operatorname{lowbit}(R) lowbit ( R ) x = 7 = 2 2 + 2 1 + 2 0 x=7=2^{2}+2^{1}+2^{0} x = 7 = 2 2 + 2 1 + 2 0 [ 1 , 7 ] [1,7] [ 1 , 7 ] [ 1 , 4 ] 、 [ 5 , 6 ] [1,4] 、[5,6] [ 1 , 4 ] 、 [ 5 , 6 ] [ 7 , 7 ] [7,7] [ 7 , 7 ] lowbit ( 4 ) = 4 、 lowbit ( 6 ) = 2 \operatorname{lowbit}(4)=4 、 \operatorname{lowbit}(6)=2 lowbit ( 4 ) = 4 、 lowbit ( 6 ) = 2 ( 7 ) = 1 (7)=1 ( 7 ) = 1
我们在位运算 一文中探讨过 lowbit 运算, 并介绍了如何利用 lowbit 运算找出整数在 二进制表示下所有等于 1 的位。类似地, 给定一个整数 x x x [ 1 , x ] [1, x] [ 1 , x ] O ( log x ) O(\log x) O ( log x )
1 2 3 while (x > 0 ) { printf ("[%d, %d]\n" , x - (x & -x) + 1 , x); }
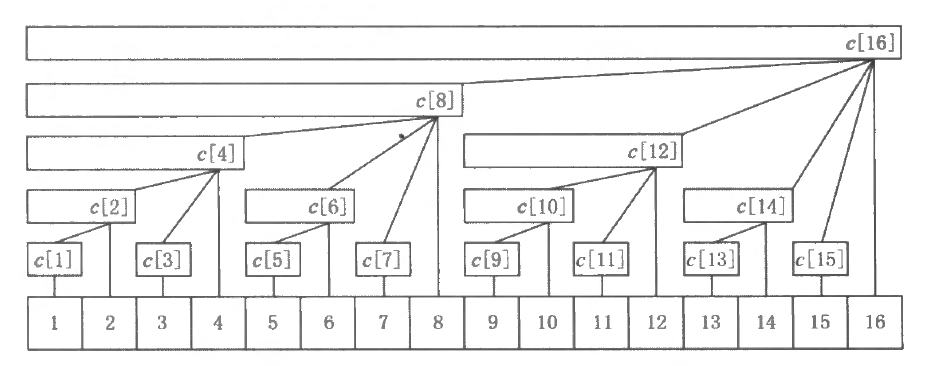
树状数组结构
树状数组 (Binary Indexed Trees) 就是一种基于上述思想的数据结构, 其基本用途是维护序列的前缀和 。对于给定的序列 a a a c c c c [ x ] c[x] c [ x ] a a a [ x − lowbit ( x ) + 1 , x ] [x-\operatorname{lowbit}(x)+1, x] [ x − lowbit ( x ) + 1 , x ] ∑ i = x − lowbit ( x ) + 1 x a [ i ] \sum_{i=x-\operatorname{lowbit}(x)+1}^{x} a[i] ∑ i = x − lowbit ( x ) + 1 x a [ i ]
事实上, 数组 c c c N N N ( N = 16 ) (N=16) ( N = 16 ) a [ 1 ∼ N ] a[1 \sim N] a [ 1 ∼ N ]
每个内部节点 c [ x ] c[x] c [ x ]
每个内部节点 c [ x ] c[x] c [ x ] lowbit ( x ) \operatorname{lowbit}(x) lowbit ( x )
除树根外, 每个内部节点 c [ x ] c[x] c [ x ] c [ x + lowbit ( x ) ] c[x+\operatorname{lowbit}(x)] c [ x + lowbit ( x )]
树的深度为 O ( log N ) \mathrm{O}(\log N) O ( log N )
如果 N N N
操作一:求前缀和
树状数组支持的基本操作有两个, 第一个操作是查询前缀和 , 即序列 a a a 1 ∼ x 1\sim x 1 ∼ x x x x [ 1 , x ] [1, x] [ 1 , x ] O ( log N ) O(\log N) O ( log N ) c c c O ( log N ) O(\log N) O ( log N )
1 2 3 4 5 int ask (int x) int ans = 0 ; for (; x; x -= x & -x) ans += c[x]; return ans; }
当然, 若要查询序列 a a a [ l , r ] [l, r] [ l , r ] ask ( r ) − ask ( l − 1 ) \operatorname{ask}(r)-\operatorname{ask}(l- 1) ask ( r ) − ask ( l − 1 )
操作二:单点增加
树状数组支持的第二个基本操作是单点增加 。意思是给序列中的一个数 a [ x ] a[x] a [ x ] y y y c [ x ] c[x] c [ x ] a [ x ] a[x] a [ x ] log N \log N log N c c c O ( log N ) O(\log N) O ( log N )
1 2 3 void add (int x, int y) for (; x <= N; x += x & -x) c[x] += y; }
树状数组初始化
在执行所有操作之前, 我们需要对树状数组进行初始化 ——针对原始序列 a a a
为了简便, 比较一般的初始化方法是: 直接建立一个全为 0 的数组 c c c x x x add ( x , a [ x ] ) \operatorname{add}(x, a[x]) add ( x , a [ x ]) a a a O ( N log N ) O(N \log N) O ( N log N )
1 2 int c[N];for (int i = 1 ; i <= n; ++i) add (i, a[i]);
更高效的初始化方法是: 从小到大依次考虑每个节点 x x x O ( ∑ k = 1 log N k ∗ N / 2 k ) = O ( N ) O\left(\sum_{k=1}^{\log N} k * N / 2^{k}\right)=O(N) O ( ∑ k = 1 l o g N k ∗ N / 2 k ) = O ( N )
1 2 3 4 5 int c[N];for (int i = 1 ; i <= n; ++i) { c[i] += a[i]; if (i + lowbit (i) <= n) c[i + lowbit (i)] += c[i]; }
还有一种简单的初始化方式:
先求前缀和sum数组
c[x] = sum[x] - sum[x - lowbit(x)]
树状数组与逆序对
任意给定一个集合 a a a t [ v a l ] t[v a l] t [ v a l ] v a l val v a l a a a t t t [ l , r ] [l, r] [ l , r ] ∑ i = l r t [ i ] \sum_{i=l}^{r} t[i] ∑ i = l r t [ i ] a a a [ l , r ] [l, r] [ l , r ]
我们可以在集合 a a a 数值范围上 建立一个树状数组, 来维护 t t t a a a
我们在排序一文中提到了逆序对问题以及使用归并排序的解法。对于一个序列 a a a i < j i<j i < j a [ i ] > a [ j ] a[i]>a[j] a [ i ] > a [ j ] a [ i ] a[i] a [ i ] a [ j ] a[j] a [ j ]
在序列 a a a
倒序扫描给定的序列 a a a a [ i ] a[i] a [ i ]
在树状数组中查询前缀和 [ 1 , a [ i ] − 1 ] [1, a[i]-1] [ 1 , a [ i ] − 1 ] a n s a n s an s
执行 “单点增加” 操作, 即把位置 a [ i ] a[i] a [ i ] t [ a [ i ] ] t[a[i]] t [ a [ i ]] t t t a [ i ] a[i] a [ i ]
ans 即为所求。
1 2 3 4 for (int i = n; i; --i) { ans += ask (a[i] - 1 ); add (a[i], 1 ); }
在这个算法中, 因为倒序扫描, “已经出现过的数” 就是在 a [ i ] a[i] a [ i ] a [ i ] a[i] a [ i ] 。每次查询的结果之和当然就是逆序对个数。时间复杂度为 O ( ( N + M ) log M ) , M \mathrm{O}((N+M) \log M), M O (( N + M ) log M ) , M
当数值范围较大时, 当然可以先进行离散化, 再用树状数组进行计算。不过因为离散化本身就要通过排序来实现, 所以在这种情况下就不如直接用归并排序来计算逆序对数了。
在完成了分配任务之后,西部 314 314 314
相传很久以前这片土地上(比楼兰古城还早)生活着两个部落,一个部落崇拜尖刀(V),一个部落崇拜铁锹(∧),他们分别用 V 和 ∧ 的形状来代表各自部落的图腾。
西部 314 314 314 n n n n n n
西部 314 314 314 n n n ( 1 , y 1 ) , ( 2 , y 2 ) , … , ( n , y n ) (1,y_1),(2,y_2),…,(n,y_n) ( 1 , y 1 ) , ( 2 , y 2 ) , … , ( n , y n ) y 1 ∼ y n y_1 \sim y_n y 1 ∼ y n 1 1 1 n n n
西部 314 314 314
如果三个点 ( i , y i ) , ( j , y j ) , ( k , y k ) (i,y_i),(j,y_j),(k,y_k) ( i , y i ) , ( j , y j ) , ( k , y k ) 1 ≤ i < j < k ≤ n 1 \le i < j < k \le n 1 ≤ i < j < k ≤ n y i > y j , y j < y k y_i > y_j, y_j < y_k y i > y j , y j < y k V 图腾;
如果三个点 ( i , y i ) , ( j , y j ) , ( k , y k ) (i,y_i),(j,y_j),(k,y_k) ( i , y i ) , ( j , y j ) , ( k , y k ) 1 ≤ i < j < k ≤ n 1 \le i < j< k \le n 1 ≤ i < j < k ≤ n y i < y j , y j > y k y_i < y_j, y_j > y_k y i < y j , y j > y k ∧ 图腾;
西部 314 314 314 n n n
因此,你需要编写一个程序来求出 V 的个数和 ∧ 的个数。
输入格式
第一行一个数 n n n
第二行是 n n n y 1 , y 2 , … , y n y_1,y_2,…,y_n y 1 , y 2 , … , y n
输出格式
两个数,中间用空格隔开,依次为 V 的个数和 ∧ 的个数。
数据范围
对于所有数据,n ≤ 200000 n \le 200000 n ≤ 200000 i n t 64 int64 in t 64 y 1 ∼ y n y_1 \sim y_n y 1 ∼ y n 1 1 1 n n n
输入样例:
输出样例:
算法分析
题目描述的第一句话实际上告诉我们, 如果把这 N N N 1 ∼ N 1 \sim N 1 ∼ N a a a
在树状数组求逆序对的算法中, 我们已经知道如何在一个序列中计算每个数后边有多少个数比它小。类似地, 我们可以:
倒序扫描序列 a a a a [ i ] a[i] a [ i ] r i g h t [ i ] right[i] r i g h t [ i ]
正序扫描序列 a a a a [ i ] a[i] a [ i ] l e f t [ i ] left[i] l e f t [ i ]
依次枚举每个点作为中间点, 以该点为中心的 “ v \mathrm{v} v l e f t [ i ] ∗ r i g h t [ i ] left[i] * right[i] l e f t [ i ] ∗ r i g h t [ i ] v \mathrm{v} v ∑ i = 1 N left [ i ] ∗ right [ i ] \sum_{i=1}^{N} \operatorname{left}[i] * \operatorname{right}[i] ∑ i = 1 N left [ i ] ∗ right [ i ] ^” 字图腾的个数。
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> #include <cstring> using namespace std;const int N = 2e5 + 10 ;int n;int a[N], c[N];int l[N], r[N];int ask (int x) int ans = 0 ; for (; x; x -= x & -x) ans += c[x]; return ans; } void add (int x, int w) for (; x <= n; x += x & -x) c[x] += w; } int main () cin >> n; for (int i = 1 ; i <= n; ++i) cin >> a[i]; for (int i = n; i; --i) { int val = a[i]; r[i] = ask (val - 1 ); add (val, 1 ); } memset (c, 0 , sizeof c); for (int i = 1 ; i <= n; ++i) { int val = a[i]; l[i] = ask (val - 1 ); add (val, 1 ); } long long ans1 = 0 , ans2 = 0 ; for (int i = 1 ; i <= n; ++i) { ans1 += 1LL * (i - 1 - l[i]) * (n - i - r[i]); ans2 += 1LL * l[i] * r[i]; } cout << ans1 << " " << ans2; }
树状数组的扩展应用
给定长度为 N N N A A A M M M
第一类指令形如 C l r d,表示把数列中第 l ∼ r l \sim r l ∼ r d d d
第二类指令形如 Q x,表示询问数列中第 x x x
对于每个询问,输出一个整数表示答案。
输入格式
第一行包含两个整数 N N N M M M
第二行包含 N N N A [ i ] A[i] A [ i ]
接下来 M M M M M M
输出格式
对于每个询问,输出一个整数表示答案。
每个答案占一行。
数据范围
1 ≤ N , M ≤ 1 0 5 1 \le N,M \le 10^5 1 ≤ N , M ≤ 1 0 5 ∣ d ∣ ≤ 10000 |d| \le 10000 ∣ d ∣ ≤ 10000 ∣ A [ i ] ∣ ≤ 1 0 9 |A[i]| \le 10^9 ∣ A [ i ] ∣ ≤ 1 0 9
输入样例:
1 2 3 4 5 6 7 10 5 1 2 3 4 5 6 7 8 9 10 Q 4 Q 1 Q 2 C 1 6 3 Q 2
输出样例:
算法分析
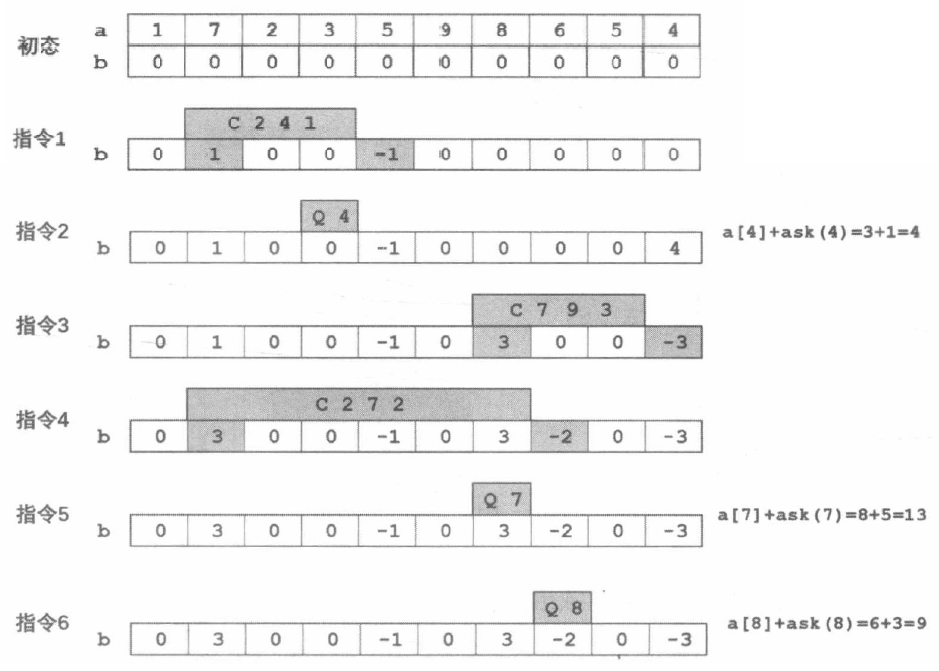
本题的指令有 “区间增加 ” 和 “单点查询 ”, 而树状数组仅支持 “单点增加” , 需要作出一些转化来解决问题。
新建一个数组 b b b C l r d \mathrm{C} \;l \;\mathrm{r} \;d C l r d
把 b [ l ] b[l] b [ l ] d d d
再把 b [ r + 1 ] b[r+1] b [ r + 1 ] d d d
执行上面两条指令之后, 我们来考虑一下 b b b b [ 1 ∼ x ] b[1 \sim x] b [ 1 ∼ x ]
对于 1 ≤ x < l 1 \leq x<l 1 ≤ x < l
对于 l ≤ x ≤ r l \leq x \leq r l ≤ x ≤ r d d d
对于 r < x ≤ N r<x \leq N r < x ≤ N ( l (l ( l d , r + 1 d, r+1 d , r + 1 d d d
我们发现, b b b b [ 1 ∼ x ] b[1 \sim x] b [ 1 ∼ x ] C l r d \mathrm{C\;l\;r\;d} C l r d a [ x ] a[x] a [ x ]
于是, 我们可以用树状数组来维护数组 b b b b b b b [ 1 ∼ x ] b[1 \sim x] b [ 1 ∼ x ] C \mathrm{C} C a [ x ] a[x] a [ x ] a [ x ] a[x] a [ x ] Q x \mathrm{Q} \;x Q x
该做法把 “维护数列的具体值” 转化为 “维护指令的累积影响”。每次修改的 “影响” 在 l l l r + 1 r+1 r + 1 b [ 1 ∼ x ] b[1 \sim x] b [ 1 ∼ x ] a [ x ] a[x] a [ x ] 该做法巧妙地把 “区间增加” + “单点查询” 变为树状数组擅长的 “单点增加” + “区间查询” 进行处理 。
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <iostream> using namespace std;using LL = long long ;const int N = 1e5 + 10 ;int n, m;int a[N], c[N];LL ask (int x) { LL ans = 0 ; for (; x; x -= x & -x) ans += c[x]; return ans; } void add (int x, int w) for (; x <= n; x += x & -x) c[x] += w; } int main () cin >> n >> m; for (int i = 1 ; i <= n; ++i) cin >> a[i]; while (m--) { char op; cin >> op; if (op == 'Q' ) { int x; cin >> x; cout << a[x] + ask (x) << endl; } else { int l, r, d; cin >> l >> r >> d; add (l, d); add (r + 1 , -d); } } }
给定一个长度为 N N N A A A M M M
C l r d,表示把 A [ l ] , A [ l + 1 ] , … , A [ r ] A[l],A[l+1],…,A[r] A [ l ] , A [ l + 1 ] , … , A [ r ] d d d Q l r,表示询问数列中第 l ∼ r l \sim r l ∼ r
对于每个询问,输出一个整数表示答案。
输入格式
第一行两个整数 N , M N,M N , M
第二行 N N N A [ i ] A[i] A [ i ]
接下来 M M M M M M
输出格式
对于每个询问,输出一个整数表示答案。
每个答案占一行。
数据范围
1 ≤ N , M ≤ 1 0 5 1 \le N,M \le 10^5 1 ≤ N , M ≤ 1 0 5 ∣ d ∣ ≤ 10000 |d| \le 10000 ∣ d ∣ ≤ 10000 ∣ A [ i ] ∣ ≤ 1 0 9 |A[i]| \le 10^9 ∣ A [ i ] ∣ ≤ 1 0 9
输入样例:
1 2 3 4 5 6 7 10 5 1 2 3 4 5 6 7 8 9 10 Q 4 4 Q 1 10 Q 2 4 C 3 6 3 Q 2 4
输出样例:
算法分析
在上一题中, 我们用树状数组维护了一个数组 b b b C l r d \mathrm{C} \;l\; \mathrm{r} \;d C l r d b [ l ] b[l] b [ l ] d d d b [ r + 1 ] b[r+1] b [ r + 1 ] d d d
我们已经讨论过, b b b ∑ i = 1 x b [ i ] \sum_{i=1}^{x} b[i] ∑ i = 1 x b [ i ] a [ x ] a[x] a [ x ] a a a a [ 1 ∼ x ] a[1 \sim x] a [ 1 ∼ x ]
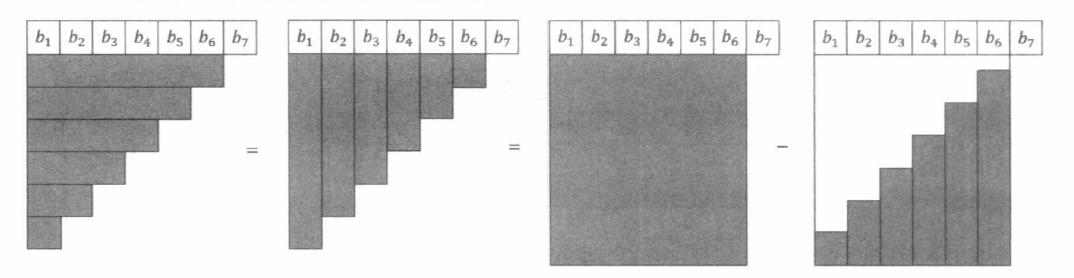
∑ i = 1 x ∑ j = 1 i b [ j ] \sum_{i=1}^{x} \sum_{j=1}^{i} b[j]
i = 1 ∑ x j = 1 ∑ i b [ j ]
上式可以改写为:
∑ i = 1 x ∑ j = 1 i b [ j ] = ∑ i = 1 x ( x − i + 1 ) ∗ b [ i ] = ( x + 1 ) ∑ i = 1 x b [ i ] − ∑ i = 1 x i ∗ b [ i ] \sum_{i=1}^{x} \sum_{j=1}^{i} b[j]=\sum_{i=1}^{x}(x-i+1) * b[i]=(x+1) \sum_{i=1}^{x} b[i]-\sum_{i=1}^{x} i * b[i]
i = 1 ∑ x j = 1 ∑ i b [ j ] = i = 1 ∑ x ( x − i + 1 ) ∗ b [ i ] = ( x + 1 ) i = 1 ∑ x b [ i ] − i = 1 ∑ x i ∗ b [ i ]
这个推导也可以用图形来直观描绘:
在本题中, 我们增加一个树状数组, 用于维护 i ∗ b [ i ] i * b[i] i ∗ b [ i ] ∑ i = 1 x i ∗ b [ i ] \sum_{i=1}^{x} i * b[i] ∑ i = 1 x i ∗ b [ i ]
具体来说, 我们建立两个树状数组 c 0 c_{0} c 0 c 1 c_{1} c 1 Clrd \operatorname{C l r d} Clrd
在树状数组 c 0 c_{0} c 0 l l l d d d
在树状数组 c 0 c_{0} c 0 r + 1 r+1 r + 1 d d d
在树状数组 c 1 c_{1} c 1 l l l l ∗ d l * d l ∗ d
在树状数组 c 1 c_{1} c 1 r + 1 r+1 r + 1 ( r + 1 ) ∗ d (r+1) * d ( r + 1 ) ∗ d
另外, 我们建立数组 sum 存储序列 a a a Q l r Q \;l\; r Q l r 1 ∼ r 1 \sim r 1 ∼ r 1 ∼ l − 1 1 \sim l-1 1 ∼ l − 1
( s u m [ r ] + ( r + 1 ) ∗ a s k ( c 0 , r ) − a s k ( c 1 , r ) ) −
(sum[r]+(r+1)*ask(c_{0}, r)-ask(c_{1}, r)) \;- ( s u m [ r ] + ( r + 1 ) ∗ a s k ( c 0 , r ) − a s k ( c 1 , r )) −
( s u m [ l − 1 ] + l ∗ a s k ( c 0 , l − 1 ) − a s k ( c 1 , l − 1 ) ) (sum[l-1]+l * ask(c_{0}, l-1)-ask(c_{1}, l-1))
( s u m [ l − 1 ] + l ∗ a s k ( c 0 , l − 1 ) − a s k ( c 1 , l − 1 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> using namespace std;using LL = long long ;const int N = 1e5 + 10 ;int n, m;int a[N];LL sum[N], c[2 ][N]; LL ask (int k, int x) { LL ans = 0 ; for (; x; x -= x & -x) ans += c[k][x]; return ans; } void add (int k, int x, LL w) for (; x <= n; x += x & -x) c[k][x] += w; } LL prefixSum (int x) { return sum[x] + (x + 1 ) * ask (0 , x) - ask (1 , x); } int main () cin >> n >> m; for (int i = 1 ; i <= n; ++i) cin >> a[i], sum[i] = sum[i - 1 ] + a[i]; while (m--) { char op; int l, r; cin >> op >> l >> r; if (op == 'Q' ) { cout << prefixSum (r) - prefixSum (l - 1 ) << endl; } else { int d; cin >> d; add (0 , l, d); add (0 , r + 1 , -d); add (1 , l, l * d); add (1 , r + 1 , -(r + 1 ) * d); } } }
值得指出的是, 为什么我们把 ∑ i = 1 x ( x − i + 1 ) ∗ b [ i ] \sum_{i=1}^{x}(x-i+1) * b[i] ∑ i = 1 x ( x − i + 1 ) ∗ b [ i ] ( x + 1 ) ∑ i = 1 x b [ i ] − ∑ i = 1 x i ∗ b [ i ] (x+1) \sum_{i=1}^{x} b[i]-\sum_{i=1}^{x} i * b[i] ( x + 1 ) ∑ i = 1 x b [ i ] − ∑ i = 1 x i ∗ b [ i ] x x x a [ 1 ∼ x ] a[1 \sim x] a [ 1 ∼ x ] i i i
对于前者来说, 求和式中的每一项同时包含 x x x i i i ( x − i + 1 ) (x-i+1) ( x − i + 1 ) b [ i ] b[i] b [ i ]
对于后者来说, 求和式中的每一项只与 i i i ( x + 1 ) (x+1) ( x + 1 ) b [ i ] b[i] b [ i ] i ∗ b [ i ] i * b[i] i ∗ b [ i ] 分离包含有多个变量的项, 使公式中不同变量之间互相独立 的思想非常重要, 我们在讨论动态规划的优化策略时会多次用到。
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> using namespace std;using LL = long long ;const int N = 1e5 + 10 ;int n, m;int a[N];LL sum[N], c[2 ][N]; LL ask (int k, int x) { LL ans = 0 ; for (; x; x -= x & -x) ans += c[k][x]; return ans; } void add (int k, int x, LL w) for (; x <= n; x += x & -x) c[k][x] += w; } LL prefixSum (int x) { return (x + 1 ) * ask (0 , x) - ask (1 , x); } int main () cin >> n >> m; for (int i = 1 ; i <= n; ++i) cin >> a[i]; for (int i = 1 ; i <= n; ++i) { int b = a[i] - a[i - 1 ]; add (0 , i, b); add (1 , i, 1LL * i * b); } while (m--) { char op; int l, r; cin >> op >> l >> r; if (op == 'Q' ) { cout << prefixSum (r) - prefixSum (l - 1 ) << endl; } else { int d; cin >> d; add (0 , l, d); add (0 , r + 1 , -d); add (1 , l, l * d); add (1 , r + 1 , -(r + 1 ) * d); } } }
有 n n n 1 ∼ n 1 \sim n 1 ∼ n
现在这 n n n i i i A i A_i A i
输入格式
第 1 1 1 n n n
第 2.. n 2..n 2.. n A i A_i A i i i i i i i A i A_i A i 1 1 1
输出格式
输出包含 n n n
第 i i i i i i
数据范围
1 ≤ n ≤ 1 0 5 1 \le n \le 10^5 1 ≤ n ≤ 1 0 5
输入样例:
输出样例:
算法分析
如果最后一头奶牛前面有 A n A_{n} A n H n = A n + 1 H_{n}=A_{n}+1 H n = A n + 1 A n + 1 A_{n}+1 A n + 1 A n − 1 A_{n-1} A n − 1 A n − 1 + 1 A_{n-1}+1 A n − 1 + 1
若 A n − 1 < A n A_{n-1}<A_{n} A n − 1 < A n H n − 1 = A n − 1 + 1 H_{n-1}=A_{n-1}+1 H n − 1 = A n − 1 + 1
若 A n − 1 ≥ A n A_{n-1} \geq A_{n} A n − 1 ≥ A n H n − 1 = A n − 1 + 2 H_{n-1}=A_{n-1}+2 H n − 1 = A n − 1 + 2
依此类推, 如果第 k k k A k A_{k} A k H k H_{k} H k 1 ∼ n 1 \sim n 1 ∼ n A k + 1 A_{k}+1 A k + 1 { H k + 1 , H k + 2 , ⋯ , H n } \left\{H_{k+1}, H_{k+2}, \cdots, H_{n}\right\} { H k + 1 , H k + 2 , ⋯ , H n }
核心问题:
从剩余数中,找出第 k k k
删除某个数
具体来说, 我们建立一个长度为 n n n b b b b[i] = 1 表示身高 i 可用。然后, 从 n n n A i A_{i} A i A i A_{i} A i
查询序列 b b b A i + 1 A_{i}+1 A i + 1 i i i H i H_{i} H i
把 b [ H i ] b\left[H_{i}\right] b [ H i ] ) ) )
也就是说, 我们需要实时维护一个 01 序列, 支持查询第 k k k ( k (k ( k 。
方法一: 树状数组+二分 , 单次操作 O ( log 2 n ) O\left(\log ^{2} n\right) O ( log 2 n )
用树状数组 c c c b b b ask ( m i d ) \operatorname{ask}(\mathrm{mid}) ask ( mid ) k k k
方法二: 树状数组+倍增 , 单次操作 O ( log n ) O(\log n) O ( log n )
用树状数组 c c c b b b
初始化两个变量 a n s = 0 a n s=0 an s = 0 s u m = 0 s u m=0 s u m = 0
从 log n \log n log n p p p p p p a n s + 2 p ≤ n a n s+2^{p} \leq n an s + 2 p ≤ n s u m + c [ a n s + 2 p ] < k s u m+c\left[a n s+2^{p}\right]<k s u m + c [ an s + 2 p ] < k s u m + = c [ a n s + 2 p ] , a n s + = 2 p s u m+=c[a n s+2^{p}]\;,\;ans+=2^{p} s u m + = c [ an s + 2 p ] , an s + = 2 p
最后, H i = a n s + 1 H_{i}=a n s+1 H i = an s + 1
该做法与 “倍增” 中给出的第一个小问题采用了类似的思想, 都是 “以 2 的整数次幂为步长, 能累加则累加 ”。树状数组 c c c
Solution
树状数组 + 二分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> using namespace std;const int N = 1e5 + 10 ;int n;int h[N], c[N], ans[N];void add (int x, int w) for (; x <= n; x += x & -x) c[x] += w; } int ask (int x) int ans = 0 ; for (; x; x -= x & -x) ans += c[x]; return ans; } int main () cin >> n; for (int i = 2 ; i <= n; ++i) cin >> h[i]; for (int i = 1 ; i <= n; ++i) add (i, 1 ); for (int i = n; i; --i) { int k = h[i] + 1 ; int l = 1 , r = n; while (l < r) { int mid = l + r >> 1 ; if (ask (mid) >= k) r = mid; else l = mid + 1 ; } ans[i] = r; add (r, -1 ); } for (int i = 1 ; i <= n; ++i) cout << ans[i] << endl; }