参考《算法竞赛进阶指南》 、AcWing题库
并查集
并查集 (Disjoint-Set) 是一种可以动态维护若干个不重叠的集合, 并支持合并与查询的数据结构。详细地说, 并查集包括如下两个基本操作:
Get, 查询一个元素属于哪一个集合。
Merge, 把两个集合合并成一个大集合。
为了具体实现并查集这种数据结构, 我们首先需要定义集合的表示方法。在并查集中, 我们采用 “代表元” 法, 即为每个集合选择一个固定的元素, 作为整个集合的 “代表” 。
其次, 我们需要定义归属关系的表示方法。第一种思路是维护一个数组 f f f f [ x ] f[x] f [ x ] x x x f f f 使用一个树形结构存储每个集合, 树上的每个节点都是一个元素, 树根是集合的代表元素 。整个并查集实际上是一个森林 (若干棵树)。我们仍然可以维护一个数组 f a f a f a f a [ x ] f a[x] f a [ x ] x x x f a f a f a f a [ root 1 ] = root 2 f a\left[\operatorname{root}_{1}\right]=\operatorname{root}_{2} f a [ root 1 ] = root 2 f a f a f a
路径压缩与按秩合并
读者可能已经注意到, 第一种思路 (直接用数组 f f f
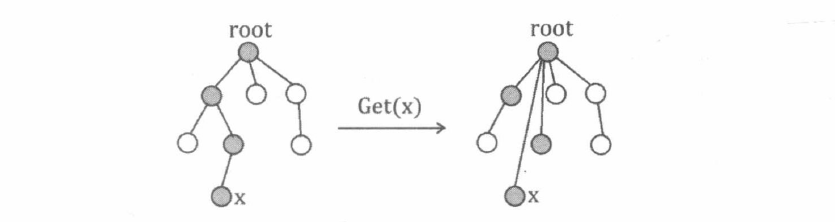
因此, 我们可以在每次执行 Get 操作的同时, 把访问过的每个节点 (也就是所查询元素的全部祖先) 都直接指向树根, 即把上图中左边那棵树变成右边那棵。这种优化方法被称为路径压缩。采用路径压缩优化的并查集, 每次 Get 操作的均摊复杂度为 O ( log N ) O(\log N) O ( log N )
还有一种优化方法被称为按秩合并。所谓 “秩”, 一般有两种定义。有的资料把并查集中集合的 “秩” 定义为树的深度 (未路径压缩时)。有的资料把集合的 “秩” 定义为集合的大小。无论采取哪种定义, 我们都可以把集合的 “秩” 记录在 “代表元素”,也就是树根上。在合并时都把 “秩” 较小的树根作为 “秩” 较大的树根的子节点。
值得一提的是, 当 “秩” 定义为集合的大小时, “按秩合并” 也称为 “启发式合并 ”, 它是数据结构相关问题中一种重要的思想, 应用非常广泛, 不只局限于并查集中。启发式合并的原则是: 把 “小的结构” 合并到 “大的结构” 中, 并且只增加 “小的结构” 的查询代价。这样一来, 把所有结构全部合并起来, 增加的总代价不会超过 N log N N \log N N log N O ( log N ) O(\log N) O ( log N )
同时采用 “路径压缩” 和 “按秩合并” 优化的并查集, 每次 Get 操作的均推复杂度可以进一步降低到 O ( α ( N ) ) O(\alpha(N)) O ( α ( N )) α ( N ) \alpha(N) α ( N ) log N \log N log N ∀ N ≤ 2 2 1 0 10992 \forall N \leq 2^{2^{10^{10992}}} ∀ N ≤ 2 2 1 0 10992 α ( N ) < 5 \alpha(N)<5 α ( N ) < 5 α ( N ) \alpha(N) α ( N )
在实际应用中, 我们一般只用路径压缩优化就足够了。接下来, 我们对并查集的具体代码实现作一下具体说明。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class UnionFind {public : vector<int > fa, size; int part; UnionFind (int n) { for (int i = 0 ; i < n; ++i) fa.push_back (i); size.resize (n, 1 ); part = n; } int find (int x) if (fa[x] == x) return x; return fa[x] = find (fa[x]); } bool merge (int x, int y) int rootx = find (x), rooty = find (y); if (rootx == rooty) return false ; if (size[rootx] > size[rooty]) swap (rootx, rooty); fa[rootx] = rooty; size[rooty] += size[rootx]; --part; return true ; } bool isConnected (int x, int y) return find (x) == find (y); } };
并查集的存储
使用一个数组 f a f a f a
并查集的初始化
设有 n n n n n n
1 for (int i = 1 ; i <= n; ++i) fa[i] = i;
并查集的 Get 操作
若 x x x x x x f a [ x ] fa[x] f a [ x ]
1 2 3 4 int get (int x) if (x == fa[x]) return x; return fa[x] = get (fa[x]); }
并查集的 Merge 操作
合并元素 x x x y y y x x x y y y
1 2 3 void merge (int x, int y) fa[get (x)] = get (y); }
在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足。
考虑一个约束满足问题的简化版本:假设 x 1 , x 2 , x 3 , … x_1,x_2,x_3,… x 1 , x 2 , x 3 , … n n n x i = x j x_i=x_j x i = x j x i ≠ x j x_i≠x_j x i = x j
例如,一个问题中的约束条件为:x 1 = x 2 , x 2 = x 3 , x 3 = x 4 , x 1 ≠ x 4 x_1=x_2,x_2=x_3,x_3=x_4,x_1≠x_4 x 1 = x 2 , x 2 = x 3 , x 3 = x 4 , x 1 = x 4
现在给出一些约束满足问题,请分别对它们进行判定。
输入格式
输入文件的第 1 1 1 1 1 1 t t t
对于每个问题,包含若干行:
第 1 1 1 1 1 1 n n n
接下来 n n n 3 3 3 i , j , e i,j,e i , j , e 1 1 1 e = 1 e=1 e = 1 x i = x j x_i=x_j x i = x j e = 0 e=0 e = 0 x i ≠ x j x_i≠x_j x i = x j
输出格式
输出文件包括 t t t
输出文件的第 k k k YES 或者 NO,YES 表示输入中的第 k k k NO 表示不可被满足。
数据范围
1 ≤ n ≤ 1 0 5 1 \le n \le 10^5 1 ≤ n ≤ 1 0 5 1 ≤ i , j ≤ 1 0 9 1 \le i,j \le 10^9 1 ≤ i , j ≤ 1 0 9
输入样例:
1 2 3 4 5 6 7 2 2 1 2 1 1 2 0 2 1 2 1 2 1 1
输出样例:
算法分析
先满足所有 “相等” 类型的约束条件。容易发现, 如果把每个变量看作无向图中的一个节点, 每个 “相等” 的约束条件看作无向图中的一条边, 那么两个变量相等当且仅当它们连通。于是, 我们可以把变量分成若干个集合, 每个集合都对应无向图中的一个连通块。
有两种方法求出这些集合。第一种是建出上面提到的无向图, 执行深度优先遍历, 划分出无向图中的每个连通块。第二种是使用并查集动态维护。起初, 所有变量各自构成一个集合; 对于每条 “相等” 的约束条件, 合并它约束的两个变量所在的集合即可。 最后, 扫描所有 “不等” 类型的约束条件。若存在一条 “不等” 的约束条件, 它约束的两个变量处于同一个集合内, 则不可能被满足。若不存在这样的“不等” 约束, 则全部条件可以被满足。
值得注意的是, 本题中变量 x x x x x x 1 ∼ 2 n 1 \sim 2 n 1 ∼ 2 n
从这道题目我们看到, 并查集能在一张无向图中维护节点之间的连通性 , 这是它的基本用途之一。实际上, 并查集擅长动态维护许多具有传递性的关系 。所谓传递性, 顾名思义, 就是指如果 A A A B B B B B B C C C A A A C C C
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <cstdio> #include <iostream> #include <algorithm> using namespace std;const int N = 100006 ;int n, m, a[N*2 ], fa[N*2 ];struct P { int i, j; bool e; } p[N]; int get (int x) if (x == fa[x]) return x; return fa[x] = get (fa[x]); } int find (int x) return lower_bound (a + 1 , a + m + 1 , x) - a; } void cxzdfx () cin >> n; for (int i = 1 ; i <= n; i++) { cin >> p[i].i >> p[i].j; cin >> p[i].e; a[2 *i-1 ] = p[i].i; a[2 *i] = p[i].j; } sort (a + 1 , a + 2 * n + 1 ); m = unique (a + 1 , a + 2 * n + 1 ) - (a + 1 ); for (int i = 1 ; i <= m; i++) fa[i] = i; for (int i = 1 ; i <= n; i++) if (p[i].e) fa[get (find (p[i].i))] = get (find (p[i].j)); for (int i = 1 ; i <= n; i++) if (!p[i].e && get (find (p[i].i)) == get (find (p[i].j))) { puts ("NO" ); return ; } puts ("YES" ); } int main () int t; cin >> t; while (t--) cxzdfx (); return 0 ; }
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include <iostream> #include <unordered_map> using namespace std;const int N = 1e5 + 10 ;int n, m;int fa[2 * N];unordered_map<int , int > hm; struct Query { int x, y, e; }query[N]; int get (int x) if (hm.count (x) == 0 ) hm[x] = ++m; return hm[x]; } int find (int x) if (fa[x] == x) return x; return fa[x] = find (fa[x]); } bool merge (int x, int y) int rootx = find (x), rooty = find (y); if (rootx == rooty) return false ; fa[rootx] = rooty; return true ; } int main () int t; cin >> t; while (t--) { hm.clear (); m = 0 ; cin >> n; for (int i = 1 ; i <= n; ++i) { int x, y, e; cin >> x >> y >> e; query[i] = {get (x), get (y), e}; } for (int i = 1 ; i <= m; ++i) fa[i] = i; for (int i = 1 ; i <= n; ++i) { if (query[i].e == 1 ) { merge (query[i].x, query[i].y); } } bool flag = true ; for (int i = 1 ; i <= n; ++i) { if (query[i].e == 0 ) { int rootx = find (query[i].x), rooty = find (query[i].y); if (rootx == rooty) { flag = false ; break ; } } } if (flag) cout << "YES" << endl; else cout << "NO" << endl; } }
超市里有 N N N p i p_i p i d i d_i d i
求合理安排每天卖的商品的情况下,可以得到的最大收益是多少。
输入格式
输入包含多组测试用例。
每组测试用例,以输入整数 N N N N N N p i p_i p i d i d_i d i i i i
在输入中,数据之间可以自由穿插任意个空格或空行,输入至文件结尾时终止输入,保证数据正确。
输出格式
对于每组产品,输出一个该组的最大收益值。
每个结果占一行。
数据范围
0 ≤ N ≤ 10000 0 \le N \le 10000 0 ≤ N ≤ 10000 1 ≤ p i , d i ≤ 10000 1 \le p_i,d_i \le 10000 1 ≤ p i , d i ≤ 10000 14 14 14
输入样例:
1 2 3 4 4 50 2 10 1 20 2 30 1 7 20 1 2 1 10 3 100 2 8 2 5 20 50 10
输出样例:
算法分析
在二叉堆做法中, 我们把商品按照过期时间从前到后排序, 然后依次尝试用每个商品替换掉堆中利润较低的商品。
另一种显而易见的贪心策略则是, 优先考虑卖出利润大的商品, 并且对每个商品, 在它过期之前尽量晩卖出一一占用较晩的时间, 显然对其他商品具有 “决策包容性” 。
于是我们可以把商品按照利润从大到小排序, 并建立一个关于 “天数” 的并查集, 起初每一天各自构成一个集合。对于每个商品, 若它在 d d d d d d r r r r r r r r r r r r r − 1 r-1 r − 1 r r r r − 1 r-1 r − 1
这个并查集实际上维护了一个数组中 “位置” 的占用情况 。每个 “位置” 所在集合的代表就是从它开始往前数第一个空闲的位置 (包括它本身)。当一个 “位置” 被占用时(某一天安排了商品,就把该 “位置” 在并查集中指向它前一个 “位置”。利用并查集的路径压缩, 就可以快速找到最晩能卖出的时间 (从过期时间往前数第一个空闲的天数 )。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <iostream> #include <algorithm> using namespace std;const int N = 10006 ;int n, fa[N];pair<int , int > p[N]; int get (int x) if (x == fa[x]) return x; return fa[x] = get (fa[x]); } void Supermarket () int d = 0 , ans = 0 ; for (int i = 1 ; i <= n; i++) { cin >> p[i].first >> p[i].second; d = max (d, p[i].second); } for (int i = 0 ; i <= d; i++) fa[i] = i; sort (p + 1 , p + n + 1 ); for (int i = n; i; i--) { int x = get (p[i].second); if (x) { ans += p[i].first; fa[x] = x - 1 ; } } cout << ans << endl; } int main () while (cin >> n) Supermarket (); return 0 ; }
Solution
Alice和Bob玩了一个古老的游戏:首先画一个 n × n n \times n n × n n = 3 n = 3 n = 3
接着,他们两个轮流在相邻的点之间画上红边和蓝边:
直到围成一个封闭的圈(面积不必为 1 1 1
他们甚至在游戏中都不知道谁赢得了游戏。
于是请你写一个程序,帮助他们计算他们是否结束了游戏?
输入格式
输入数据第一行为两个整数 n n n m m m n n n m m m m m m
以后 m m m ( x , y ) (x, y) ( x , y ) D D D R R R
输入数据不会有重复的边且保证正确。
输出格式
输出一行:在第几步的时候结束。
假如 m m m
数据范围
1 ≤ n ≤ 200 1 \le n \le 200 1 ≤ n ≤ 200 1 ≤ m ≤ 24000 1 \le m \le 24000 1 ≤ m ≤ 24000
输入样例:
1 2 3 4 5 6 3 5 1 1 D 1 1 R 1 2 D 2 1 R 2 2 D
输出样例:
算法分析
并查集(典型并查集判断是否存在环的问题)
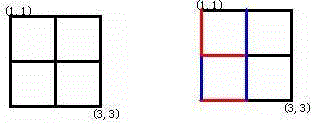
1、将每个坐标看成一个点值,为了方便计算,将所有的坐标横纵坐标都减1,第一个位置即(1,1)看成是0,(1,2)看成是1,依次类推,将所有的坐标横纵坐标都减1后,假设当前点是(x,y),则该点的映射值是a = (x * n + y),b = [(x + 1) * n + y],若向右画,则b = [x * n + y - 1]
2、枚举所有操作,通过并查集操作判断a和b是否在同一个集合,
若在同一个集合则标记此操作可以让格子形成环
若不在同一个集合,则需要将两个集合进行合并
并查集解决的是连通性(无向图联通分量)和传递性(家谱关系)问题,并且可以动态的维护。抛开格子不看,任意一个图中,增加一条边形成环当且仅当这条边连接的两点已经联通,于是可以将点分为若干个集合,每个集合对应图中的一个连通块。
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <iostream> using namespace std;const int N = 40010 ;int fa[N];int n, m;void init () for (int i = 0 ; i < n * n; ++i) fa[i] = i; } int find (int x) if (fa[x] == x) return x; return fa[x] = find (fa[x]); } bool merge (int x, int y) int rootx = find (x), rooty = find (y); if (rootx == rooty) return false ; fa[rootx] = rooty; return true ; } int getId (int x, int y) return x * n + y; } int main () cin >> n >> m; init (); int ans = 0 ; for (int i = 1 ; i <= m; ++i) { int x, y; char d; cin >> x >> y >> d; --x, --y; int a = getId (x, y); int b; if (d == 'D' ) b = getId (x + 1 , y); else b = getId (x, y + 1 ); if (!merge (a, b)) { ans = i; break ; } } if (ans == 0 ) cout << "draw" ; else cout << ans; }
Joe觉得云朵很美,决定去山上的商店买一些云朵。
商店里有 n n n 1 , 2 , … , n 1,2,…,n 1 , 2 , … , n
但是商店老板跟他说,一些云朵要搭配来买才好,所以买一朵云则与这朵云有搭配的云都要买。
但是Joe的钱有限,所以他希望买的价值越多越好。
输入格式
第 1 1 1 n , m , w n,m,w n , m , w n n n m m m w w w
第 2 ∼ n + 1 2 \sim n+1 2 ∼ n + 1 c i , d i c_i,d_i c i , d i i i i
第 n + 2 ∼ n + 1 + m n+2 \sim n+1+m n + 2 ∼ n + 1 + m u i , v i u_i,v_i u i , v i u i u_i u i v i v_i v i v i v_i v i u i u_i u i
输出格式
一行,表示可以获得的最大价值。
数据范围
1 ≤ n ≤ 10000 1 \le n \le 10000 1 ≤ n ≤ 10000 0 ≤ m ≤ 5000 0 \le m \le 5000 0 ≤ m ≤ 5000 1 ≤ w ≤ 10000 1 \le w \le 10000 1 ≤ w ≤ 10000 1 ≤ c i ≤ 5000 1 \le c_i \le 5000 1 ≤ c i ≤ 5000 1 ≤ d i ≤ 100 1 \le d_i \le 100 1 ≤ d i ≤ 100 1 ≤ u i , v i ≤ n 1 \le u_i,v_i \le n 1 ≤ u i , v i ≤ n
输入样例:
1 2 3 4 5 6 7 8 9 5 3 10 3 10 3 10 3 10 5 100 10 1 1 3 3 2 4 2
输出样例:
算法分析
把每一个连通块看做是一个物品,然后就变成了一个简单的 01 背包问题了。
在每个集合的根节点维护该集合的价钱和价值,即体积和重量。
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <iostream> using namespace std;const int N = 1e4 + 10 ;int n, m, vol;int v[N], w[N];int fa[N];int f[N];int find (int x) if (fa[x] == x) return x; return fa[x] = find (fa[x]); } bool merge (int x, int y) int rootx = find (x), rooty = find (y); if (rootx == rooty) return false ; v[rooty] += v[rootx]; w[rooty] += w[rootx]; fa[rootx] = rooty; return true ; } int main () cin >> n >> m >> vol; for (int i = 1 ; i <= n; ++i) fa[i] = i; for (int i = 1 ; i <= n; ++i) cin >> v[i] >> w[i]; for (int i = 1 ; i <= m; ++i) { int a, b; cin >> a >> b; merge (a, b); } for (int i = 1 ; i <= n; ++i) { if (fa[i] != i) continue ; for (int j = vol; j >= v[i]; --j) { f[j] = max (f[j], f[j - v[i]] + w[i]); } } cout << f[vol]; }
“扩展域” 与 “边带权” 的并查集
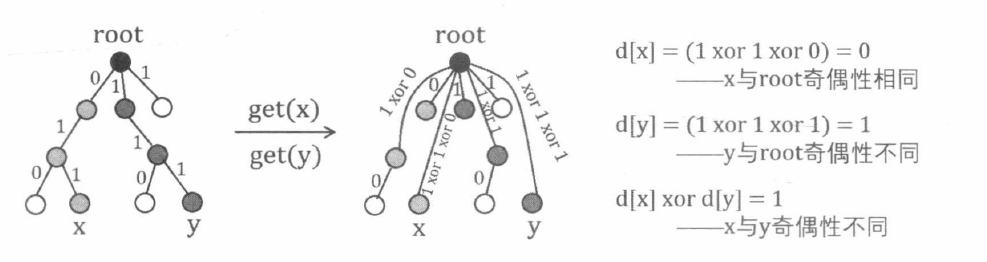
并查集实际上是由若干棵树构成的森林, 我们可以在树中的每条边上记录一个权值, 即维护一个数组 d d d d [ x ] d[x] d [ x ] x x x f a [ x ] f a[x] f a [ x ]
在每次路径压缩后, 每个访问过的节点都会直接指向树根, 如果我们同时更新这些节点的 d d d 。这就是所谓 “边带权” 的并查集。
有一个划分为 N N N 1 , 2 , … , N 1,2,…,N 1 , 2 , … , N
有 N N N 1 , 2 , … , N 1,2,…,N 1 , 2 , … , N i i i i i i
有 T T T
M i j,表示让第 i i i j j j C i j,表示询问第 i i i j j j
现在需要你编写一个程序,处理一系列的指令。
输入格式
第一行包含整数 T T T T T T
接下来 T T T M i j 或 C i j。
其中 M M M C C C i i i j j j
输出格式
你的程序应当依次对输入的每一条指令进行分析和处理:
如果是 M i j 形式,则表示舰队排列发生了变化,你的程序要注意到这一点,但是不要输出任何信息;
如果是 C i j 形式,你的程序要输出一行,仅包含一个整数,表示在同一列上,第 i i i j j j i i i j j j − 1 -1 − 1
数据范围
N ≤ 30000 , T ≤ 500000 N \le 30000 , T \le 500000 N ≤ 30000 , T ≤ 500000
输入样例:
1 2 3 4 5 4 M 2 3 C 1 2 M 2 4 C 4 2
输出样例:
算法分析
一条 “链” 也是一棵树, 只不过是树的特殊形态。因此可以把每一列战舰看作一个集合, 用并查集维护。最初, N N N N N N
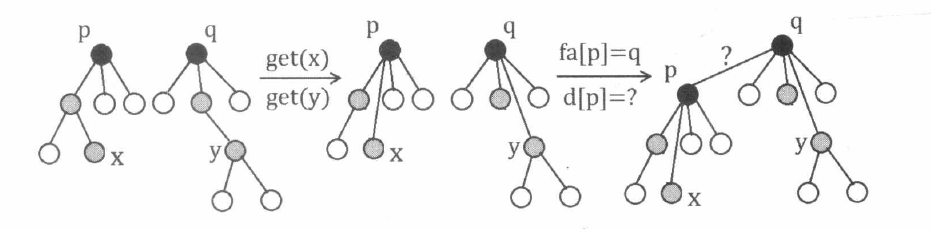
在没有路径压缩的情况下, f a [ x ] f a[x] f a [ x ] x x x
在考虑路径压缩的情况下, 我们额外建立一个数组 d , d [ x ] d, d[x] d , d [ x ] x x x f a [ x ] f a[x] f a [ x ] 在路径压缩把 x x x d [ x ] d[x] d [ x ] x x x 。下面的代码对 Get 函数稍加修改, 即可实现对 d d d
1 2 3 4 5 6 7 int get (int x) if (x == fa[x]) return x; int root = get (fa[x]); d[x] += d[fa[x]]; return fa[x] = root; }
当接收到一个 C x y \mathrm{C} \;x \;y C x y get ( x ) \operatorname{get}(x) get ( x ) get ( y ) \operatorname{get}(y) get ( y ) x x x y y y x x x y y y d [ x ] d[x] d [ x ] x x x d [ y ] d[y] d [ y ] y y y x x x y y y
当接收到一个 M x y \mathrm{M} \;x \;y M x y x x x y y y y y y y y y x x x
1 2 3 4 5 void merge (int x, int y) x = get (x), y = get (y); fa[x] = y, d[x] = size[y]; size[y] += size[x]; }
刚才我们在 “程序自动分析”一题中提到, 并查集擅长维护具有传递性的关系及其连通性。在某些问题中, “传递关系” 不止一种, 并且这些 “传递关系” 能够互相导出。此时可以使用 “扩展域” 或者 “边带权” 的并查集来解决。我们通过几道例题来详细说明。另外, 我们会在 Tarjan算法与有向图连通性 一文中探讨 2-SAT 模型, 学习之后读者就会更加深刻地理解并查集能够处理的 “关系” 本质。
Solution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <iostream> using namespace std;const int N = 30010 ;int fa[N], sz[N], d[N];void init () for (int i = 1 ; i <= 30000 ; ++i) { fa[i] = i; sz[i] = 1 ; d[i] = 0 ; } } int find (int x) if (fa[x] == x) return x; int root = find (fa[x]); d[x] += d[fa[x]]; return fa[x] = root; } bool merge (int x, int y) x = find (x), y = find (y); if (x == y) return false ; d[x] = sz[y]; sz[y] += sz[x]; fa[x] = y; return true ; } int main () init (); int T; cin >> T; while (T--) { char op; int x, y; cin >> op >> x >> y; if (op == 'M' ) { merge (x, y); } else { int rootx = find (x), rooty = find (y); if (rootx == rooty) cout << max (abs (d[x] - d[y]) - 1 , 0 ) << endl; else cout << -1 << endl; } } }
小 A A A B B B
首先,小 A A A 0 0 0 1 1 1 S S S N N N
然后,小 B B B A A A M M M
在每个问题中,小 B B B l l l r r r A A A S [ l ∼ r ] S[l \sim r] S [ l ∼ r ] 1 1 1 1 1 1
机智的小 B B B A A A
例如,小 A A A S [ 1 ∼ 3 ] S[1 \sim 3] S [ 1 ∼ 3 ] 1 1 1 S [ 4 ∼ 6 ] S[4 \sim 6] S [ 4 ∼ 6 ] 1 1 1 S [ 1 ∼ 6 ] S[1 \sim 6] S [ 1 ∼ 6 ] 1 1 1
请你帮助小 B B B M M M A A A
即求出一个最小的 k k k 01 01 01 S S S 1 ∼ k 1 \sim k 1 ∼ k 1 ∼ k + 1 1 \sim k+1 1 ∼ k + 1
输入格式
第一行包含一个整数 N N N 01 01 01
第二行包含一个整数 M M M
接下来 M M M l l l r r r even 或 odd,用以描述 S [ l ∼ r ] S[l \sim r] S [ l ∼ r ] 1 1 1 1 1 1
输出格式
输出一个整数 k k k 01 01 01 1 ∼ k 1 \sim k 1 ∼ k 1 ∼ k + 1 1 \sim k+1 1 ∼ k + 1 01 01 01
数据范围
N ≤ 1 0 9 , M ≤ 5000 N \le 10^9 , M \le 5000 N ≤ 1 0 9 , M ≤ 5000
输入样例:
1 2 3 4 5 6 7 10 5 1 2 even 3 4 odd 5 6 even 1 6 even 7 10 odd
输出样例:
算法分析
如果我们用 sum 数组表示序列 S S S
S [ l ∼ r ] S[l \sim r] S [ l ∼ r ] sum [ l − 1 ] \operatorname{sum}[l-1] sum [ l − 1 ] sum [ r ] \operatorname{sum}[r] sum [ r ] S [ l ∼ r ] S[l \sim r] S [ l ∼ r ] sum [ l − 1 ] \operatorname{sum}[l-1] sum [ l − 1 ] sum [ r ] \operatorname{sum}[r] sum [ r ]
注意, 这里没有求出 sum 数组, 我们只是把 sum 看作变量。读者可以发现, 此时本题与本节中 “程序自动分析”一题非常类似一一都是给定若干个变量和关系, 判定这些关系可满足性的问题。不同点是本题的传递关系不止一种:
若 x 1 x_{1} x 1 x 2 x_{2} x 2 x 2 x_{2} x 2 x 3 x_{3} x 3 x 1 x_{1} x 1 x 3 x_{3} x 3
若 x 1 x_{1} x 1 x 2 x_{2} x 2 x 2 x_{2} x 2 x 3 x_{3} x 3 x 1 x_{1} x 1 x 3 x_{3} x 3
若 x 1 x_{1} x 1 x 2 x_{2} x 2 x 2 x_{2} x 2 x 3 x_{3} x 3 x 1 x_{1} x 1 x 3 x_{3} x 3
另外, 序列长度 N N N M M M l − 1 l-1 l − 1 r r r 1 ∼ 2 M 1 \sim 2 M 1 ∼ 2 M
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct {int l, r, ans; } query[10010 ];int a[20010 ], fa[20010 ], d[20010 ], n, m, t;void read_discrete () cin >> n >> m; for (int i = 1 ; i <= m; i++) { char str[5 ]; scanf ("%d%d%s" , &query[i].l, &query[i].r, str); query[i].ans = (str[0 ] == 'o' ? 1 : 0 ); a[++t] = query[i].l - 1 ; a[++t] = query[i].r; } sort (a + 1 , a + t + 1 ); n = unique (a + 1 , a + t + 1 ) - a - 1 ; }
解法一:“边带权”并查集
为了处理本题的多种传递关系, 第一种解决方案是使用 “边带权” 的并查集。边权 d [ x ] d[x] d [ x ] x x x f a [ x ] f a[x] f a [ x ] x x x f a [ x ] f a[x] f a [ x ] x x x x x x
对于每个问题, 设在离散化后 l − 1 l-1 l − 1 r r r x x x y y y
先检查 x x x y y y get ( x ) 、 get ( y ) \operatorname{get}(x) 、 \operatorname{get}(y) get ( x ) 、 get ( y ) d [ x ] d[x] d [ x ] d [ y ] d[y] d [ y ] x x x y y y d [ x ] d[x] d [ x ] d [ y ] ≠ a n s d[y] \neq a n s d [ y ] = an s A \mathrm{A} A
若 x x x y y y p p p q q q p p p q q q d [ x ] d[x] d [ x ] d [ y ] d[y] d [ y ] x ∼ p x \sim p x ∼ p y ∼ q y \sim q y ∼ q p ∼ q p \sim q p ∼ q d [ p ] d[p] d [ p ] x ∼ y x \sim y x ∼ y x ∼ p , p ∼ q x \sim p, p \sim q x ∼ p , p ∼ q q ∼ y q \sim y q ∼ y x x x y y y = d [ x ] =d[x] = d [ x ] d [ y ] d[y] d [ y ] d [ p ] d[p] d [ p ] d [ p ] = d [ x ] d[p]=d[x] d [ p ] = d [ x ] d [ y ] d[y] d [ y ]
“边带权” 并查集解法的主要代码片段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int get (int x) if (x == fa[x]) return x; int root = get (fa[x]); d[x] ^= d[fa[x]]; return fa[x] = root; } int main () read_discrete (); for (int i = 1 ; i <= n; i++) fa[i] = i; for (int i = 1 ; i <= m; i++) { int x = lower_bound (a + 1 , a + n + 1 , query[i].l - 1 ) - a; int y = lower_bound (a + 1 , a + n + 1 , query[i].r) - a; int p = get (x), q = get (y); if (p == q) { if ((d[x] ^ d[y]) != query[i].ans) { cout << i - 1 << endl; return 0 ; } } else { fa[p] = q; d[p] = d[x] ^ d[y] ^ query[i].ans; } } cout << m << endl; }
解法二:“扩展域” 并查集
第二种解决方案是使用 “扩展域” 的并查集。
把每个变量 x x x x o d d x_{o d d} x o dd x even, x_{\text {even, }} x even, x o d d x_{o d d} x o dd sum [ x ] \operatorname{sum}[x] sum [ x ] x e v e n x_{e v e n} x e v e n sum [ x ] \operatorname{sum}[x] sum [ x ] x x x
对于每个问题, 设在离散化后 l − 1 l-1 l − 1 r r r x x x y y y
若 ans = 0 =0 = 0 x odd x_{\text {odd }} x odd y odd , x even y_{\text {odd }}, x_{\text {even }} y odd , x even y even y_{\text {even}} y even x x x y y y x x x y y y
若 ans = 1 =1 = 1 x odd x_{\text {odd }} x odd y even , x even y_{\text {even }}, x_{\text {even }} y even , x even y odd y_{\text {odd}} y odd x x x y y y x x x y y y
上述合并同时还维护了关系的传递性。试想, 在处理完 ( x , y , 0 ) (x, y, 0) ( x , y , 0 ) ( y , z , 1 ) (y, z, 1) ( y , z , 1 ) x x x z z z
在处理每个问题之前, 我们当然也要先检查是否存在矛盾。若两个变量 x x x y y y x o d d x_{o d d} x o dd y o d d y_{o d d} y o dd x x x y y y x o d d x_{o d d} x o dd y e v e n y_{e v e n} y e v e n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <cstdio> #include <cstring> #include <algorithm> #include <queue> using namespace std;struct {int l, r, ans; } query[10010 ];int a[20010 ], fa[40010 ], n, m, t;void read_discrete () cin >> n >> m; for (int i = 1 ; i <= m; i++) { char str[5 ]; scanf ("%d%d%s" , &query[i].l, &query[i].r, str); query[i].ans = (str[0 ] == 'o' ? 1 : 0 ); a[++t] = query[i].l - 1 ; a[++t] = query[i].r; } sort (a + 1 , a + t + 1 ); n = unique (a + 1 , a + t + 1 ) - a - 1 ; } int get (int x) if (x == fa[x]) return x; return fa[x] = get (fa[x]); } int main () read_discrete (); for (int i = 1 ; i <= 2 * n; i++) fa[i] = i; for (int i = 1 ; i <= m; i++) { int x = lower_bound (a + 1 , a + n + 1 , query[i].l - 1 ) - a; int y = lower_bound (a + 1 , a + n + 1 , query[i].r) - a; int x_odd = x, x_even = x + n; int y_odd = y, y_even = y + n; if (query[i].ans == 0 ) { if (get (x_odd) == get (y_even)) { cout << i - 1 << endl; return 0 ; } fa[get (x_odd)] = get (y_odd); fa[get (x_even)] = get (y_even); } else { if (get (x_odd) == get (y_odd)) { cout << i - 1 << endl; return 0 ; } fa[get (x_odd)] = get (y_even); fa[get (x_even)] = get (y_odd); } } cout << m << endl; }
Solution
边带权
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <iostream> #include <string> #include <unordered_map> using namespace std;const int N = 10010 ;int n, m;int fa[N], d[N];unordered_map<int , int > hm; int get (int x) if (hm.count (x) == 0 ) hm[x] = ++n; return hm[x]; } void init () for (int i = 1 ; i < N; ++i) { fa[i] = i; d[i] = 0 ; } } int find (int x) if (fa[x] == x) return x; int root = find (fa[x]); d[x] ^= d[fa[x]]; return fa[x] = root; } int main () init (); cin >> n >> m; n = 0 ; int ans = m; for (int i = 1 ; i <= m; ++i) { int l, r; string op; cin >> l >> r >> op; int x = get (l - 1 ), y = get (r); int rootx = find (x), rooty = find (y); if (rootx == rooty) { int t = d[x] ^ d[y]; if (op == "even" && t) { ans = i - 1 ; break ; } if (op == "odd" && !t) { ans = i - 1 ; break ; } } else { if (op == "even" ) d[rootx] = d[x] ^ d[y]; if (op == "odd" ) d[rootx] = d[x] ^ d[y] ^ 1 ; fa[rootx] = rooty; } } cout << ans; }
扩展域
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <iostream> #include <string> #include <unordered_map> using namespace std;const int N = 20010 ;int n, m;int fa[2 * N];unordered_map<int , int > hm; int get (int x) if (hm.count (x) == 0 ) hm[x] = ++n; return hm[x]; } void init () for (int i = 1 ; i < 2 * N; ++i) { fa[i] = i; } } int find (int x) if (fa[x] == x) return x; return fa[x] = find (fa[x]); } int main () init (); cin >> n >> m; n = 0 ; int ans = m; for (int i = 1 ; i <= m; ++i) { int l, r; string op; cin >> l >> r >> op; int x = get (l - 1 ), y = get (r); if (op == "even" ) { if (find (x + N) == find (y)) { ans = i - 1 ; break ; } else { fa[find (x)] = find (y); fa[find (x + N)] = find (y + N); } } if (op == "odd" ) { if (find (x) == find (y)) { ans = i - 1 ; break ; } else { fa[find (x + N)] = find (y); fa[find (x)] = find (y + N); } } } cout << ans; }
动物王国中有三类动物 A , B , C A,B,C A , B , C
A A A B B B B B B C C C C C C A A A
现有 N N N 1 ∼ N 1 \sim N 1 ∼ N
每个动物都是 A , B , C A,B,C A , B , C
有人用两种说法对这 N N N
第一种说法是 1 X Y,表示 X X X Y Y Y
第二种说法是 2 X Y,表示 X X X Y Y Y
此人对 N N N K K K K K K
当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
当前的话与前面的某些真的话冲突,就是假话;
当前的话中 X X X Y Y Y N N N
当前的话表示 X X X X X X
你的任务是根据给定的 N N N K K K
输入格式
第一行是两个整数 N N N K K K
以下 K K K D , X , Y D,X,Y D , X , Y D D D
若 D = 1 D=1 D = 1 X X X Y Y Y
若 D = 2 D=2 D = 2 X X X Y Y Y
输出格式
只有一个整数,表示假话的数目。
数据范围
1 ≤ N ≤ 50000 1 \le N \le 50000 1 ≤ N ≤ 50000 0 ≤ K ≤ 100000 0 \le K \le 100000 0 ≤ K ≤ 100000
输入样例:
1 2 3 4 5 6 7 8 100 7 1 101 1 2 1 2 2 2 3 2 3 3 1 1 3 2 3 1 1 5 5
输出样例:
算法分析
本题仍然可以用 “边带权” 或者 “扩展域” 的并查集解决。我们以 “扩展域” 并查集为例进行讲解。
把每个动物 x x x x self x_{\text {self }} x self x eat x_{\text {eat }} x eat x enemy x_{\text {enemy}}{ } x enemy
若一句话说 “ x x x y y y x x x y y y x x x y y y x x x y y y x self x_{\text {self }} x self y self , x eat y_{\text {self }}, x_{\text {eat }} y self , x eat y eat , x enemy y_{\text {eat }}, x_{\text {enemy }} y eat , x enemy y enemy y_{\text {enemy}} y enemy
若一句话说 “ x x x y y y x x x y y y x x x y y y x x x y y y x x x y , y y, y y , y z , z z, z z , z x x x x eat x_{\text {eat }} x eat y self y_{\text {self }} y self x self x_{\text {self }} x self y enemy , x enemy y_{\text {enemy }}, x_{\text {enemy }} y enemy , x enemy y eat y_{\text {eat }} y eat
在处理每句话之前, 都要检查这句话的真假。
有两种信息与 “ x x x y y y
x eat x_{\text {eat }} x eat y self y_{\text {self }} y self x x x y y y x self x_{\text {self }} x self y eat y_{\text {eat }} y eat y y y x x x
有两种信息与 “ x x x y y y
x self x_{\text {self }} x self y self y_{\text {self }} y self x x x y y y x self x_{\text {self }} x self y eat y_{\text {eat }} y eat y y y x x x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <algorithm> #include <cstdio> #include <cstring> #include <iostream> using namespace std;int fa[200000 ];int n, m, k, x, y, ans;int get (int x) if (x == fa[x]) return x; return fa[x] = get (fa[x]); } void merge (int x, int y) get (x)] = get (y); }int main () cin >> n >> m; for (int i = 1 ; i <= 3 * n; i++) fa[i] = i; for (int i = 1 ; i <= m; i++) { scanf ("%d%d%d" , &k, &x, &y); if (x > n || y > n) ans++; else if (k == 1 ) { if (get (x) == get (y + n) || get (x) == get (y + n + n)) ans++; else { merge (x, y); merge (x + n, y + n); merge (x + n + n, y + n + n); } } else { if (x == y || get (x) == get (y) || get (x) == get (y + n)) ans++; else { merge (x, y + n + n); merge (x + n, y); merge (x + n + n, y + n); } } } cout << ans << endl; }
Solution