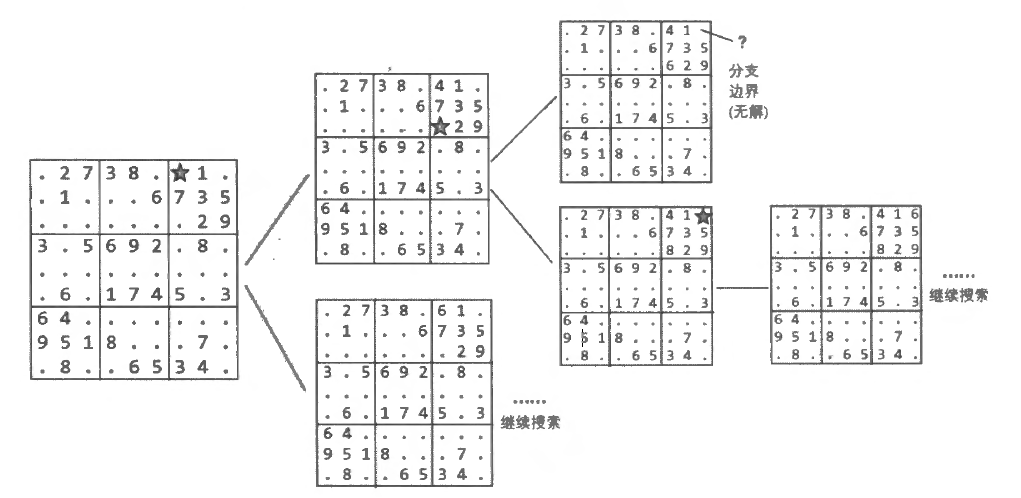
4.....8.5.3..........7......2.....6.....8.4......1.......6.3.7.5..2.....1.4...... ......52..8.4......3...9...5.1...6..2..7........3.....6...1..........7.4.......3. end
inlinevoidflip(int x, int y, int z){ row[x] ^= 1 << z; col[y] ^= 1 << z; grid[g(x, y)] ^= 1 << z; }
booldfs(int now){ if (now == 0) return1; int temp = 10, x, y; for (int i = 0; i < 9; i++) for (int j = 0; j < 9; j++) { if (str[i][j] != '.') continue; int val = row[i] & col[j] & grid[g(i, j)]; if (!val) return0; if (cnt[val] < temp) { temp = cnt[val]; x = i, y = j; } } int val = row[x] & col[y] & grid[g(x, y)]; for (; val; val -= val&-val) { int z = num[val&-val]; str[x][y] = '1' + z; flip(x, y, z); if (dfs(now - 1)) return1; flip(x, y, z); str[x][y] = '.'; } return0; }
intmain(){ for (int i = 0; i < 1 << 9; i++) for (int j = i; j; j -= j&-j) cnt[i]++; for (int i = 0; i < 9; i++) num[1 << i] = i; char s[100]; while (~scanf("%s", s) && s[0] != 'e') { for (int i = 0; i < 9; i++) for (int j = 0; j < 9; j++) str[i][j] = s[i * 9 + j]; for (int i = 0; i < 9; i++) row[i] = col[i] = grid[i] = (1 << 9) - 1; tot = 0; for (int i = 0; i < 9; i++) for (int j = 0; j < 9; j++) if (str[i][j] != '.') flip(i, j, str[i][j] - '1'); else tot++; dfs(tot); for (int i = 0; i < 9; i++) for (int j = 0; j < 9; j++) s[i * 9 + j] = str[i][j]; puts(s); } }
booldfs(int ans){ if (!ans) return1; int k = 10, t; for (int i = 0; i < 81; i++) if (s[i] == '.') { get(i); int w = x[gx] & y[gy] & z[gz]; if (cnt[w] < k) { k = cnt[w]; t = i; } } get(t); int w = x[gx] & y[gy] & z[gz]; while (w) { int now = f[w&-w]; s[t] = now + '1'; work(t, now); if (dfs(ans - 1)) return1; work(t, now); s[t] = '.'; w -= w & -w; } return0; }
voidSudoku(){ for (int i = 0; i < 9; i++) x[i] = y[i] = z[i] = (1 << 9) - 1; int ans = 0; for (int i = 0; i < 81; i++) if (s[i] != '.') work(i, s[i] - '1'); else ++ans; if (dfs(ans)) for (int i = 0; i < 81; i++) cout << s[i]; cout << endl; }
intget_cnt(int i){ int ans = 0; while (i) { ++ans; i -= (i & -i); } return ans; }
intmain(){ for (int i = 0; i < (1 << 9); i++) cnt[i] = get_cnt(i); for (int i = 0; i < 9; i++) f[1<<i] = i; for (int i = 0; i < 81; i++) { X[i] = i / 9; Y[i] = i % 9; } while (cin >> s && s[0] != 'e') Sudoku(); return0; }
char g[N][N]; int row[N], col[N], cell[N][N]; int ones[M], map[37]; string str; int cnt;
intlowbit(int x){// 返回末尾的1 return x & -x; }
voiddraw(int x, int y, int k, bool flag){ int t = 1 << k; if (flag) g[x][y] = k + '1'; else g[x][y] = '.'; row[x] ^= t; col[y] ^= t; cell[x / 3][y / 3] ^= t; }
booldfs(int now){ if (now == 0) returntrue; //找到“能填的合法数字”最少的位置 int minv = 10, x, y; for (int i = 0; i < 9; ++i) { for (int j = 0; j < 9; ++j) { if (g[i][j] == '.') { int state = row[i] & col[j] & cell[i / 3][j / 3]; if (state == 0) returnfalse; if (ones[state] < minv) { minv = ones[state]; x = i, y = j; } } } } int state = row[x] & col[y] & cell[x / 3][y / 3]; for (int i = state; i; i -= lowbit(i)) { int k = map[lowbit(i) % 37]; draw(x, y, k, true); if (dfs(now - 1)) returntrue; draw(x, y, k, false); } returnfalse; }
voidprework(){ for (int i = 0; i < 9; ++i) map[(1 << i) % 37] = i; for (int i = 0; i < 1 << 9; ++i) for (int j = i; j; j -= lowbit(j)) ++ones[i]; }
voidinit(){ // 转为 9*9 的图 for (int i = 0; i < 9; ++i) for (int j = 0; j < 9; ++j) g[i][j] = str[i * 9 + j]; // 初始化标记数组 for (int i = 0; i < 9; ++i) { row[i] = col[i] = (1 << 9) - 1; for (int j = 0; j < 9; ++j) { cell[i / 3][j / 3] = (1 << 9) - 1; } } //计算一共需要填多少个数字,并初始化相应状态 cnt = 0; for (int i = 0; i < 9; ++i) { for (int j = 0; j < 9; ++j) { if (g[i][j] != '.') { int k = g[i][j] - '1'; draw(i, j, k, true); } else { ++cnt; } } } }
voidprint(){ for (int i = 0; i < 9; ++i) { for (int j = 0; j < 9; ++j) { cout << g[i][j]; } } cout << endl; }
char g[N][N]; bool vis[N][N]; int n; int xa, ya, xb, yb;
booldfs(int x, int y){ if (g[x][y] == '#') returnfalse; //通过该点不可能到达 if (x == xb && y == yb) returntrue; //当前已到达终点,返回true vis[x][y] = true; for (int i = 0; i < 4; ++i) { int nx = x + dx[i], ny = y + dy[i]; if (nx < 0 || nx >= n || ny < 0 || ny >= n) continue; if (vis[nx][ny]) continue; if (dfs(nx, ny)) returntrue; //通过邻接点能到达终点,返回true } returnfalse; // 到达不了终点,返回false }
intmain(){ int k; cin >> k; while (k--) { cin >> n; for (int i = 0; i < n; ++i) cin >> g[i];
memset(vis, 0, sizeof vis); cin >> xa >> ya >> xb >> yb; if (dfs(xa, ya)) cout << "YES" << endl; else cout << "NO" << endl; } }
intdfs(int x, int y){ // 进入函数的都是合法点 int ans = 1; vis[x][y] = true; for (int i = 0; i < 4; ++i) { // 把不能搜索的情况都在这里一并排除掉 int a = x + dx[i], b = y + dy[i]; if (a < 1 || a > n || b < 1 || b > m) continue; if (g[a][b] == '#') continue; if (vis[a][b]) continue; ans += dfs(a, b); } return ans; }
intmain(){ while (cin >> m >> n, n || m) { int x, y; for (int i = 1; i <= n; ++i) { for (int j = 1; j <= m; ++j) { cin >> g[i][j]; if (g[i][j] == '@') x = i, y = j; } } memset(vis, 0, sizeof vis); //记得要清除标记数组状态 cout << dfs(x, y) << endl; } }
voiddfs(int x, int y, int cnt){ if (++cnt == n * m) ++ans; vis[x][y] = true; for (int i = 0; i < 8; ++i) { int nx = x + dx[i], ny = y + dy[i]; if (nx < 0 || nx >= n || ny < 0 || ny >= m) continue; if (vis[nx][ny]) continue; dfs(nx, ny, cnt); } vis[x][y] = false; }
intmain(){ int T; cin >> T; while (T--) { int x, y; cin >> n >> m >> x >> y; ans = 0; memset(vis, 0, sizeof vis); dfs(x, y, 0); cout << ans << endl; } }
int n, ans; int used[N], comlen[N][N]; string word[N]; char start;
voidprework(){ for (int i = 1; i <= n; ++i) { for (int j = 1; j <= n; ++j) { for (int k = 1; k < min(word[i].size(), word[j].size()); ++k) { if (word[i].substr(word[i].size() - k) == word[j].substr(0, k)) { comlen[i][j] = k; break; } } } } }
voiddfs(string cur, int last){ used[last]++; ans = max((int)cur.size(), ans);
for (int i = 1; i <= n; ++i) { int len = comlen[last][i]; if (len && used[i] < 2) { string next = cur + word[i].substr(len); dfs(next, i); } } used[last]--; }
intmain(){ cin >> n; for (int i = 1; i <= n; ++i) cin >> word[i]; cin >> start; prework(); for (int i = 1; i <= n; ++i) if (word[i][0] == start) dfs(word[i], i);