// 指针版 classTrie { public: structNode { bool isEnd = false; int cnt = 0; int len = 0; string s = ""; Node *son[26] = {nullptr}; Node *fail = nullptr; }*root;
Trie() { root = new Node; }
voidinsert(string &s){ auto p = root; for (int i = 0; i < s.size(); ++i) { int c = s[i] - 'a'; if (p->son[c] == nullptr) p->son[c] = new Node; p = p->son[c]; } p->isEnd = true; ++p->cnt; p->len = s.size(); p->s = s; }
voidbuild(){ root->fail = root; queue<Node*> q; for (int i = 0; i < 26; ++i) { if (root->son[i]) { root->son[i]->fail = root; q.push(root->son[i]); } else { root->son[i] = root; } } while (q.size()) { auto now = q.front(); q.pop(); for (int i = 0; i < 26; ++i) { if (now->son[i]) { now->son[i]->fail = now->fail->son[i]; q.push(now->son[i]); } else { now->son[i] = now->fail->son[i]; } } } }
voidask(string &s){ auto now = root; for (int i = 0; i < s.size(); ++i) { int c = s[i] - 'a'; now = now->son[c]; for (auto p = now; p != root; p = p->fail) { if (now->isEnd) { cout << "找到字符串" << p->s << " "; cout << "开始下标:" << i - p->len << " "; } } } }
private: voidclean(Node *t){ for (int i = 0;i < 26; ++i) { if (t->son[i]) clean(t->son[i]); } delete t; } };
int n = text.size(); auto now = trie.root; for (int i = 0; i < n; ++i) { int c = text[i] - 'a'; now = now->son[c]; for (auto p = now; p != trie.root; p = p->fail) { if (p->isEnd) ans.push_back({i - p->len + 1, i}), cout << p->s << " "; } }
// 数组版 int idx; structTrie { int cnt = 0; int fail = 0; int son[26] = {0}; }tr[N * Plen]; // N = 模式串个数, Plen = 模式串长度
voidinsert(char *str){ int p = 0; for (int i = 0; str[i]; ++i) { int c = str[i] - 'a'; if (tr[p].son[c] == 0) tr[p].son[c] = ++idx; p = tr[p].son[c]; } ++tr[p].cnt; }
int q[N * S];
voidbuild(){ int hh = 0, tt = -1; for (int i = 0; i < 26; ++i) { if (tr[0].son[i]) q[++tt] = tr[0].son[i]; } while (hh <= tt) { int now = q[hh++]; for (int i = 0; i < 26; ++i) { int &nowson = tr[now].son[i]; int nowfailson = tr[tr[now].fail].son[i]; if (nowson) { tr[nowson].fail = nowfailson; q[++tt] = nowson; } else { nowson = nowfailson; } } } }
intask(char *text){ // 查询文本text中一共出现多少种模式串 int ans = 0; for (int i = 0, now = 0; text[i]; ++i) { int c = text[i] - 'a'; now = tr[now].son[c]; for (int p = now; p; p = tr[p].fail) { ans += tr[p].cnt; tr[p].cnt = 0; } } }
概述
AC 自动机是 以 Trie 的结构为基础,结合 KMP 的思想 建立的。
简单来说,建立一个 AC 自动机有两个步骤:
基础的 Trie 结构:将所有的模式串构成一棵 Trie。
KMP 的思想:对 Trie 树上所有的结点构造失配指针。
然后就可以利用它进行多模式匹配了。
字典树构建
AC 自动机在初始时会将若干个模式串丢到一个 Trie 里,然后在 Trie 上建立 AC 自动机。这个 Trie 就是普通的 Trie,该怎么建怎么建。
tr[now,c]:有两种理解方式。我们可以简单理解为字典树上的一条边,即 trie[now,c];也可以理解为从状态(结点)now 后加一个字符 c 到达的状态(结点),即一个状态转移函数 trans(now,c)。下文中我们将用第二种理解方式继续讲解。
队列 q:用于 BFS 遍历字典树。
fail[now]:结点 now 的 fail 指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// C++ Version voidbuild(){ for (int i = 0; i < 26; i++) if (tr[0][i]) q.push(tr[0][i]); while (q.size()) { int now = q.front(); q.pop(); for (int i = 0; i < 26; ++i) { int &nowson = tr[now][i]; int nowfailson = tr[fail[now]][i]; if (nowson) { fail[nowson] = nowfailson; q.push(nowson); } else { nowson = nowfailson; } } } }
而 trans[S][c] 相当于是在 S 后添加一个字符 c 变成另一个状态 S′。如果 S′ 存在,说明存在一个模式串的前缀是 S′,否则我们让 trans[S][c] 指向 trans[fail[S]][c]。由于 fail[S] 对应的字符串是 S 的后缀,因此 trans[fail[S]][c] 对应的字符串也是 S′ 的后缀。
换言之在 Trie 上跳转的时侯,我们只会从 S 跳转到 S′,相当于匹配了一个 S′;但在 AC 自动机上跳转的时侯,我们会从 S 跳转到 S′ 的后缀,也就是说我们匹配一个字符 c,然后舍弃 S 的部分前缀。舍弃前缀显然是能匹配的。那么 fail 指针呢?它也是在舍弃前缀啊!试想一下,如果文本串能匹配 S,显然它也能匹配 S 的后缀。所谓的 fail 指针其实就是 S 的一个后缀集合。
tr 数组还有另一种比较简单的理解方式:如果在位置 now 失配,我们会跳转到 fail[now] 的位置。所以我们可能沿着 fail 数组跳转多次才能来到下一个能匹配的位置。所以我们可以用 tr 数组直接记录记录下一个能匹配的位置,这样就能节省下很多时间。
// C++ Version intask(string &s){ int ans = 0; int now = 0; for (int i = 0; i < s.size(); ++i) { int c = s[i] - 'a'; now = tr[now][c]; //转移 for (int p = now; p; p = fail[p]) { ans += cnt[p]; cnt[p] = 0; } } return ans; }
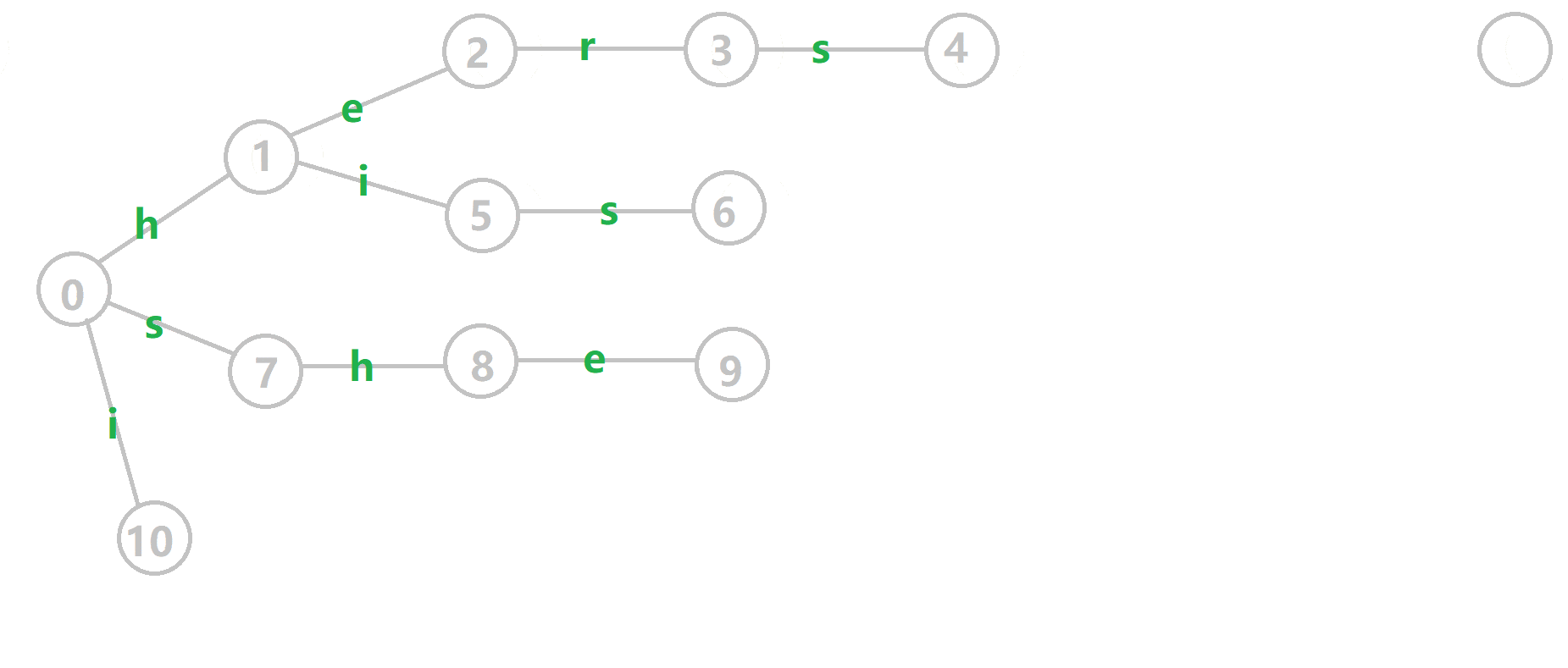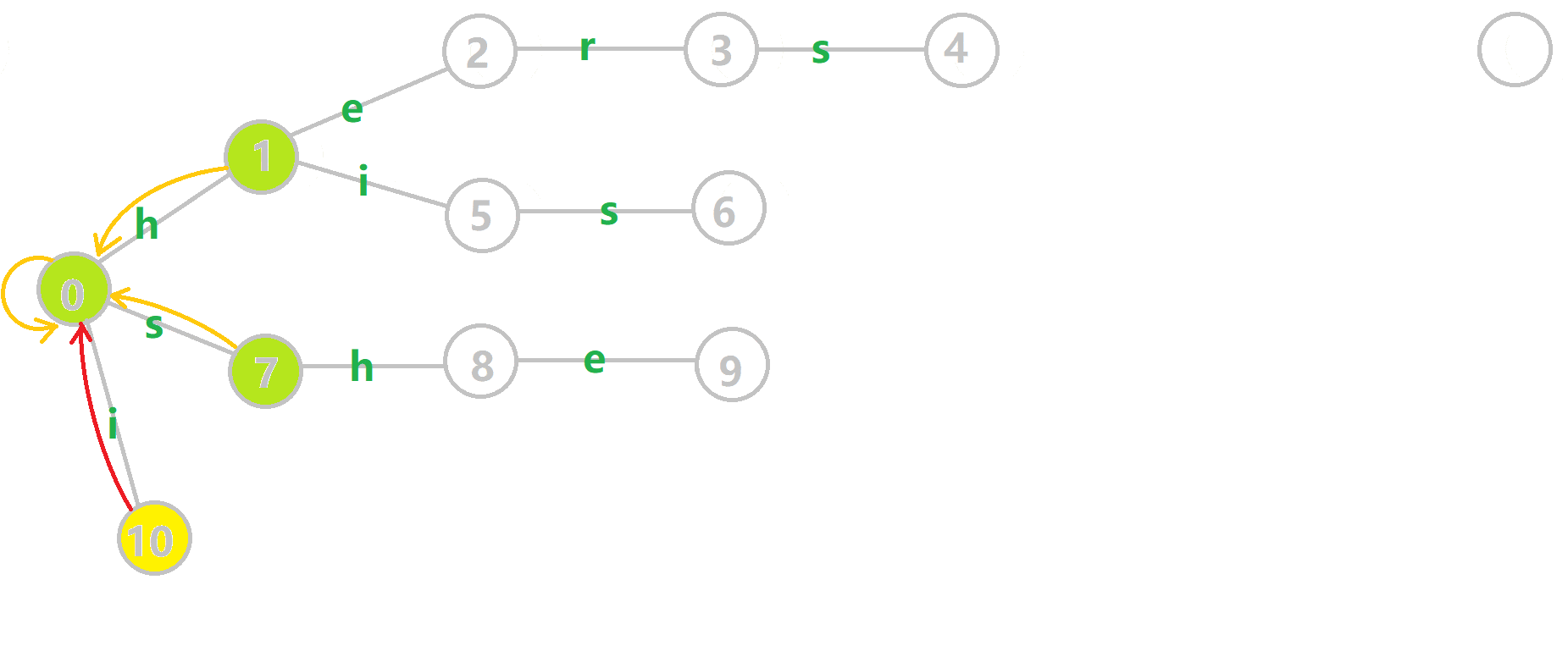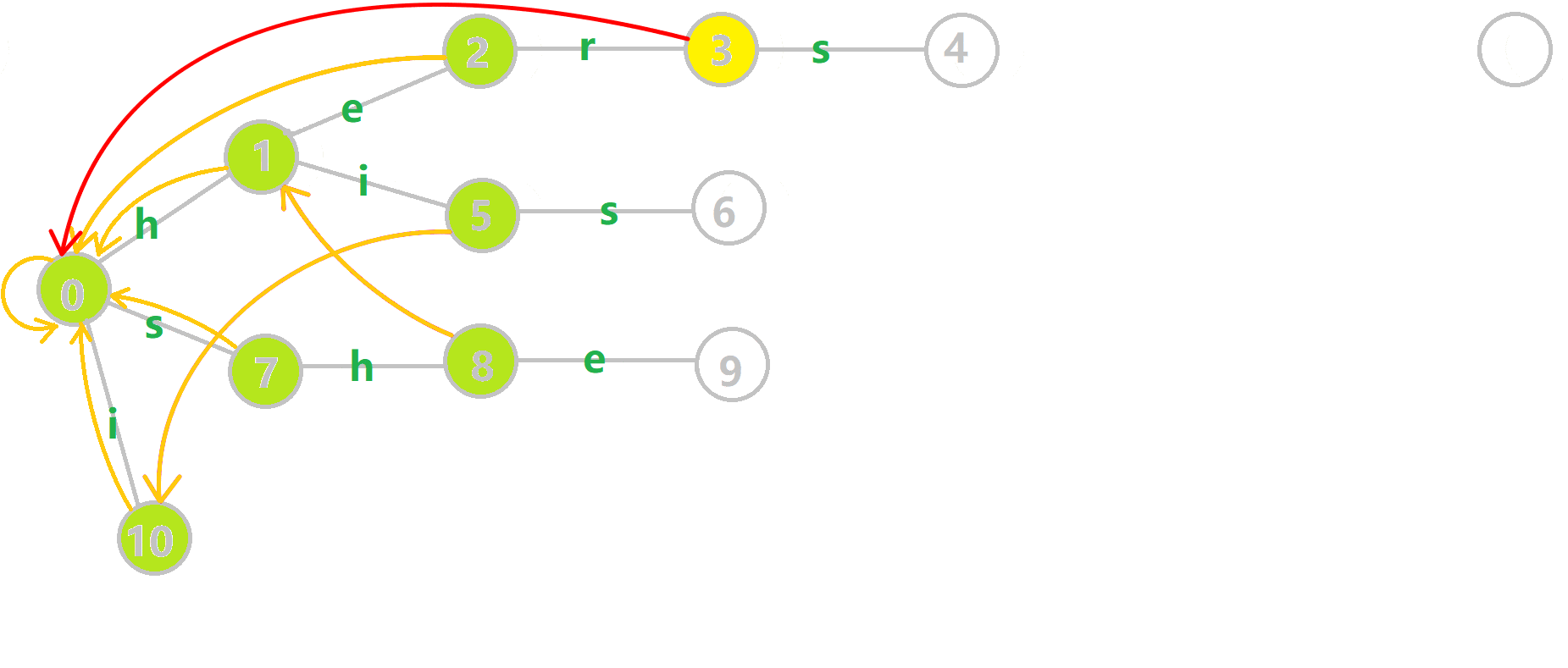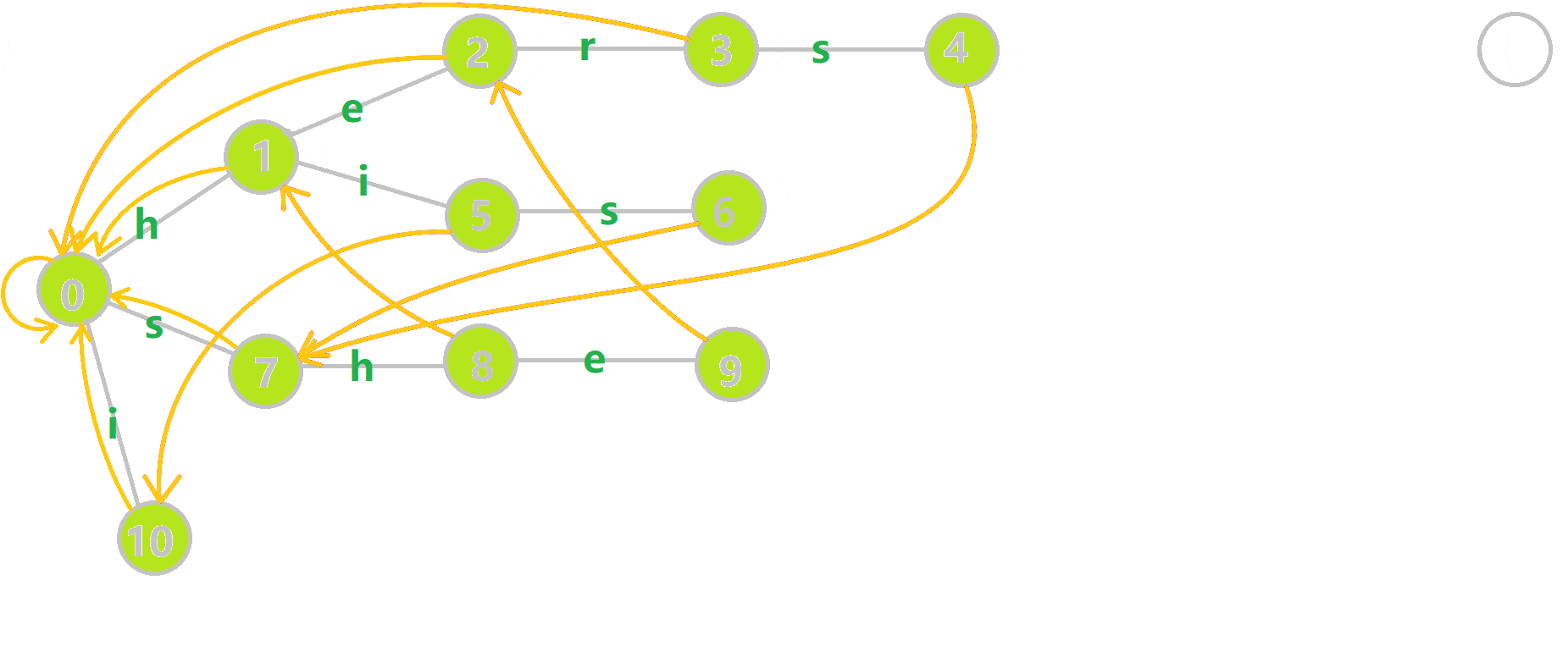
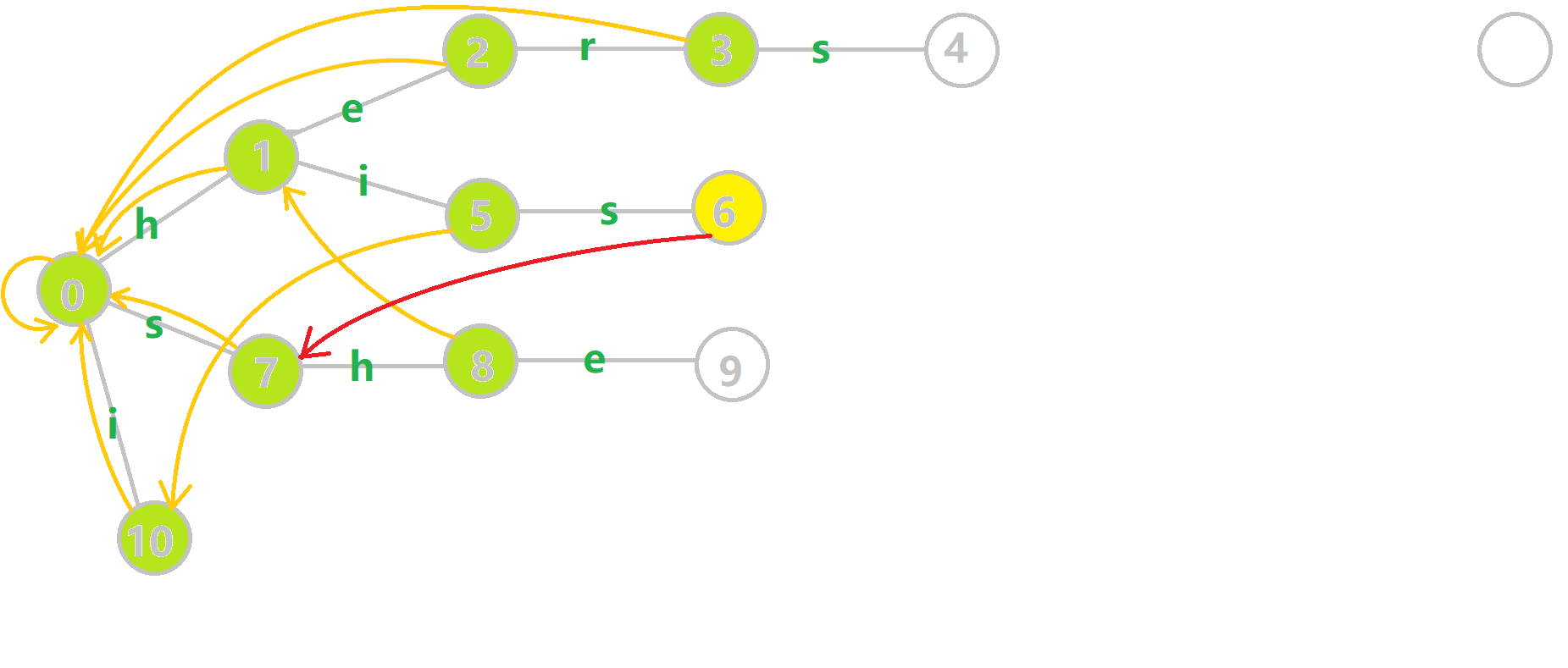
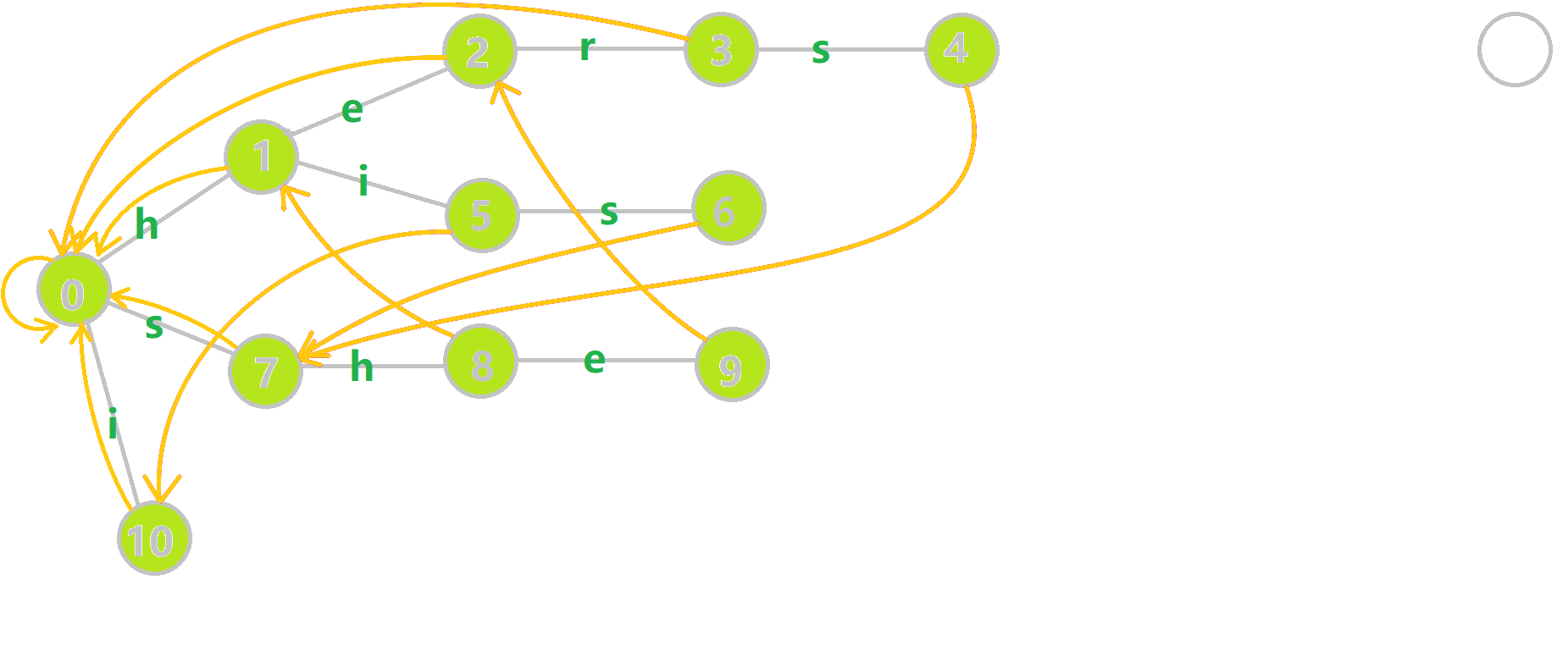
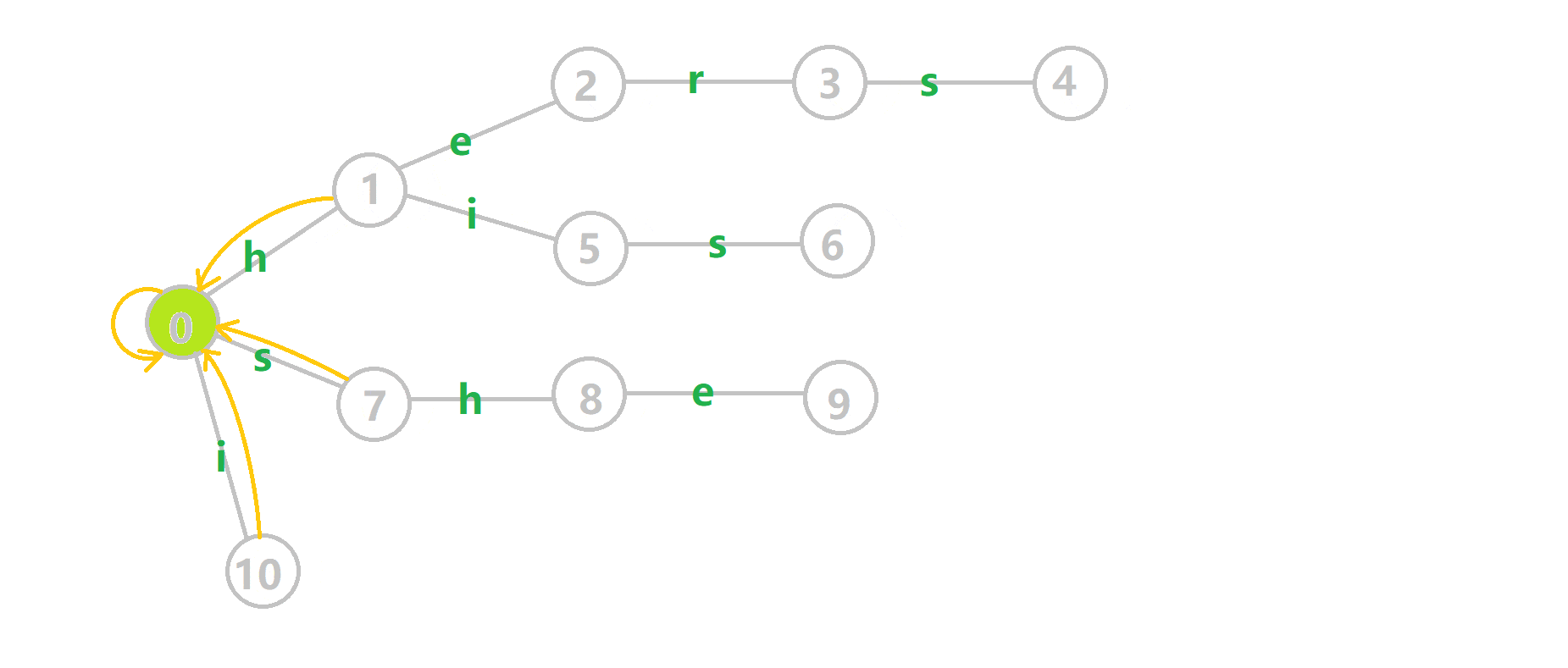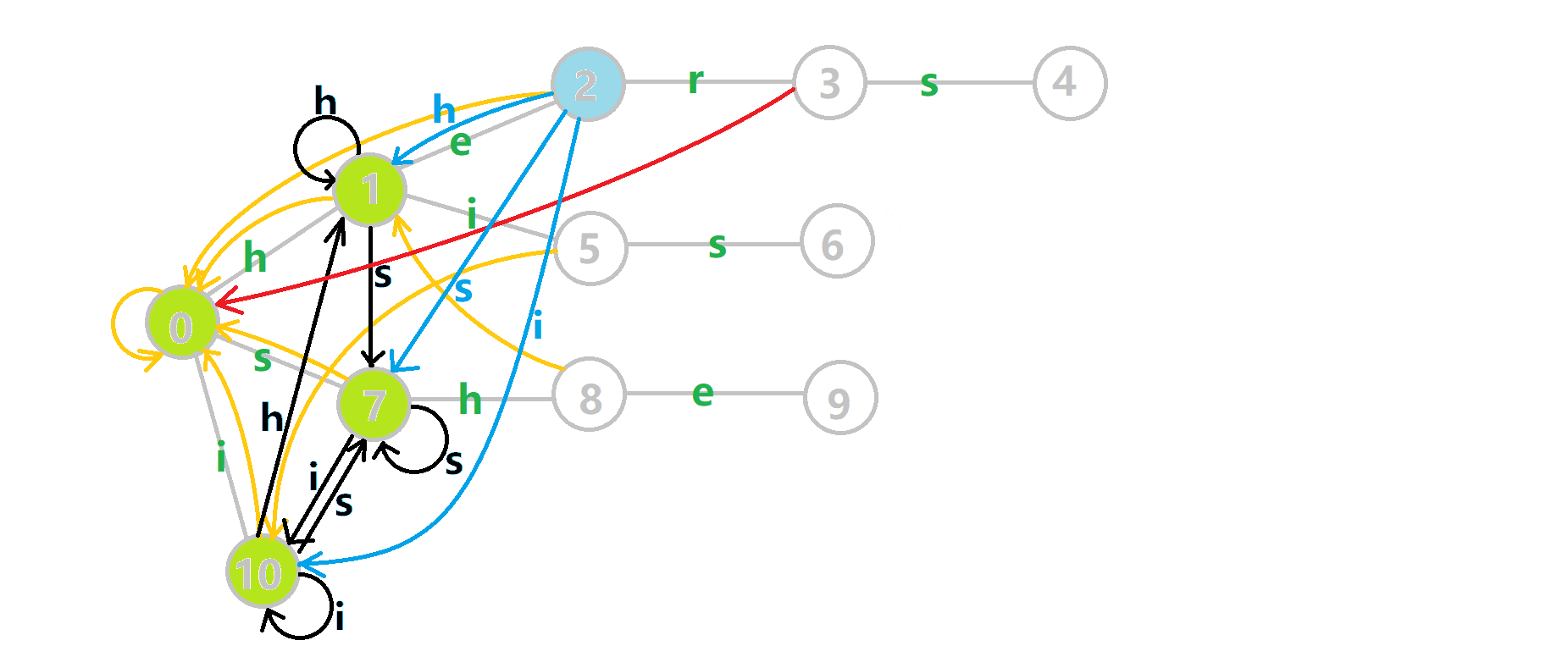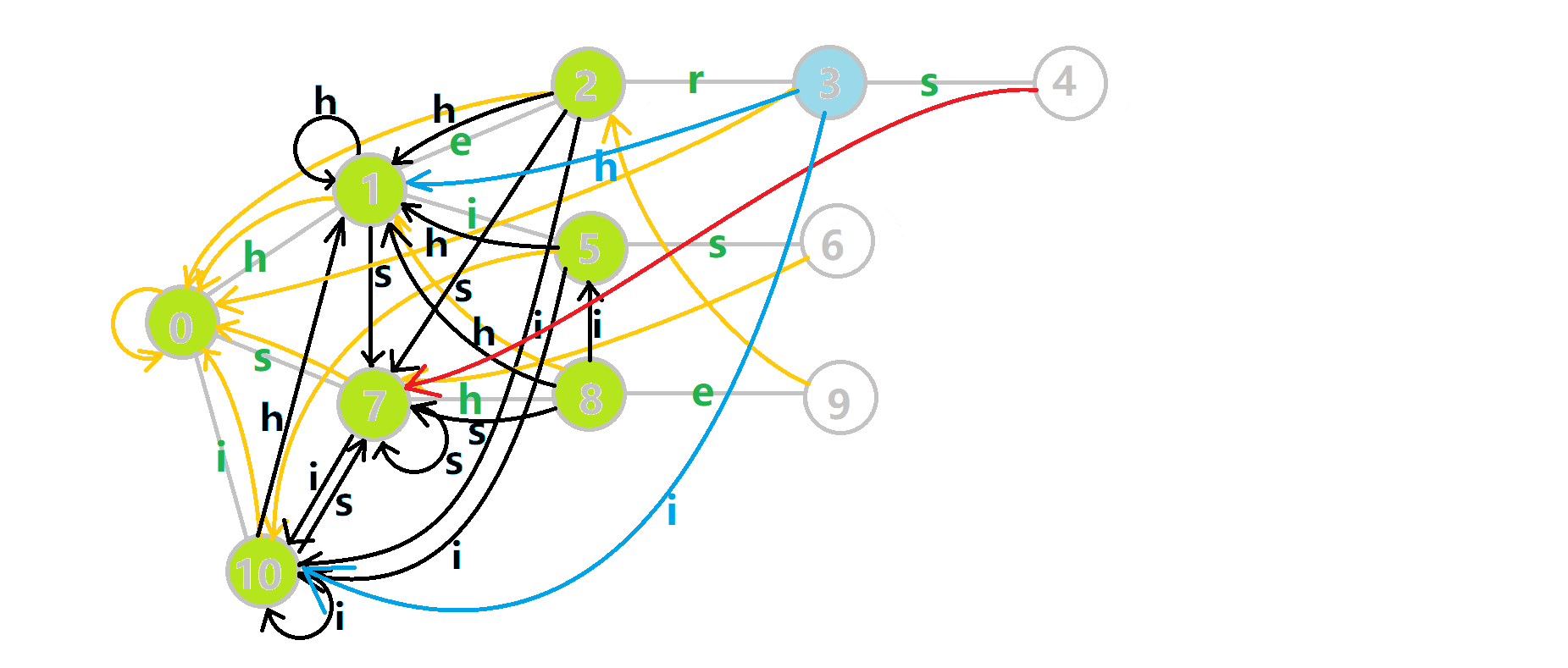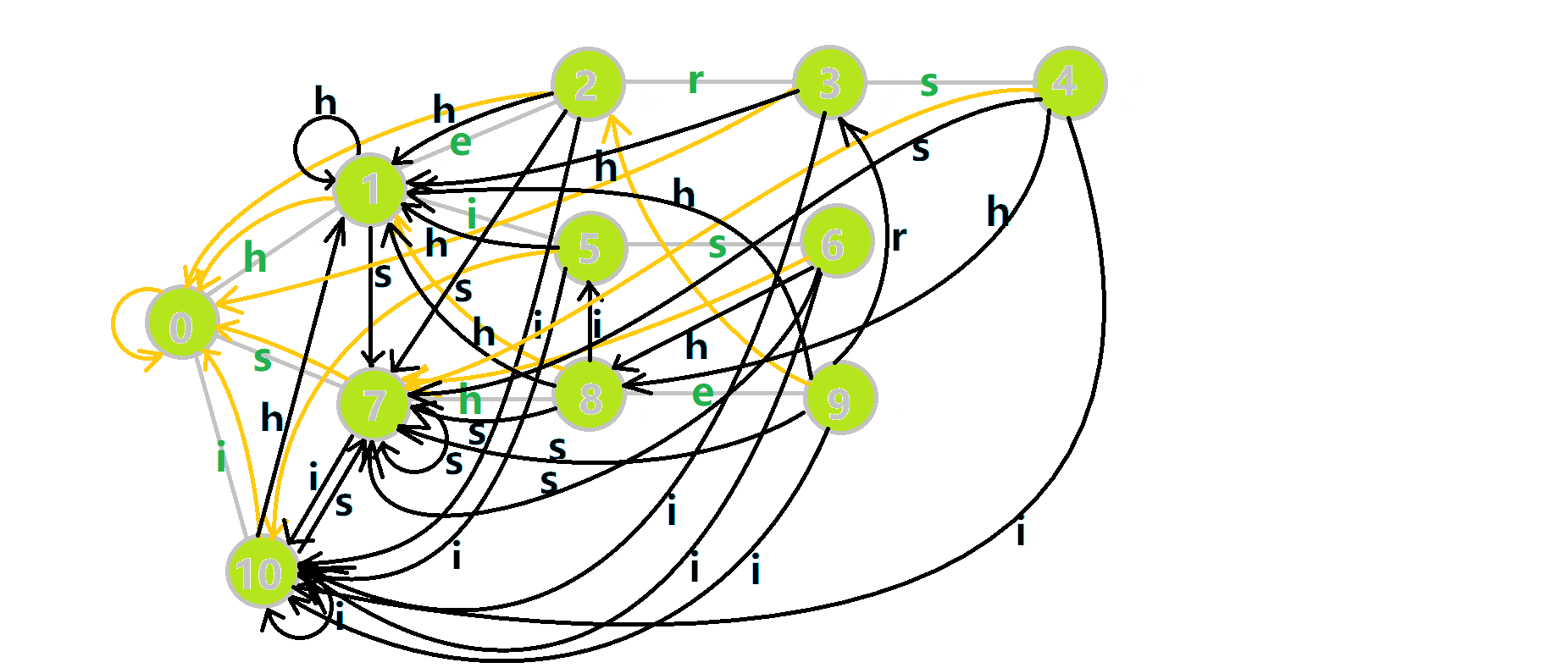
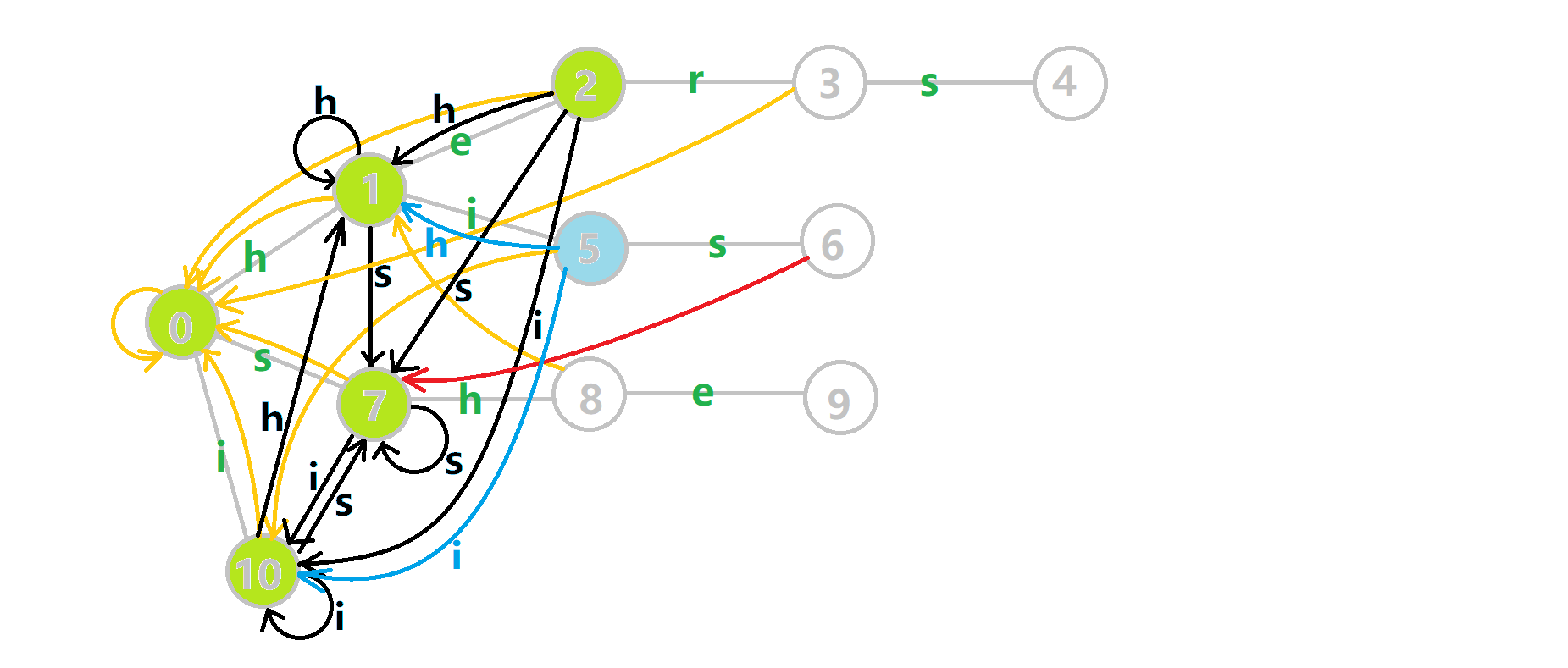
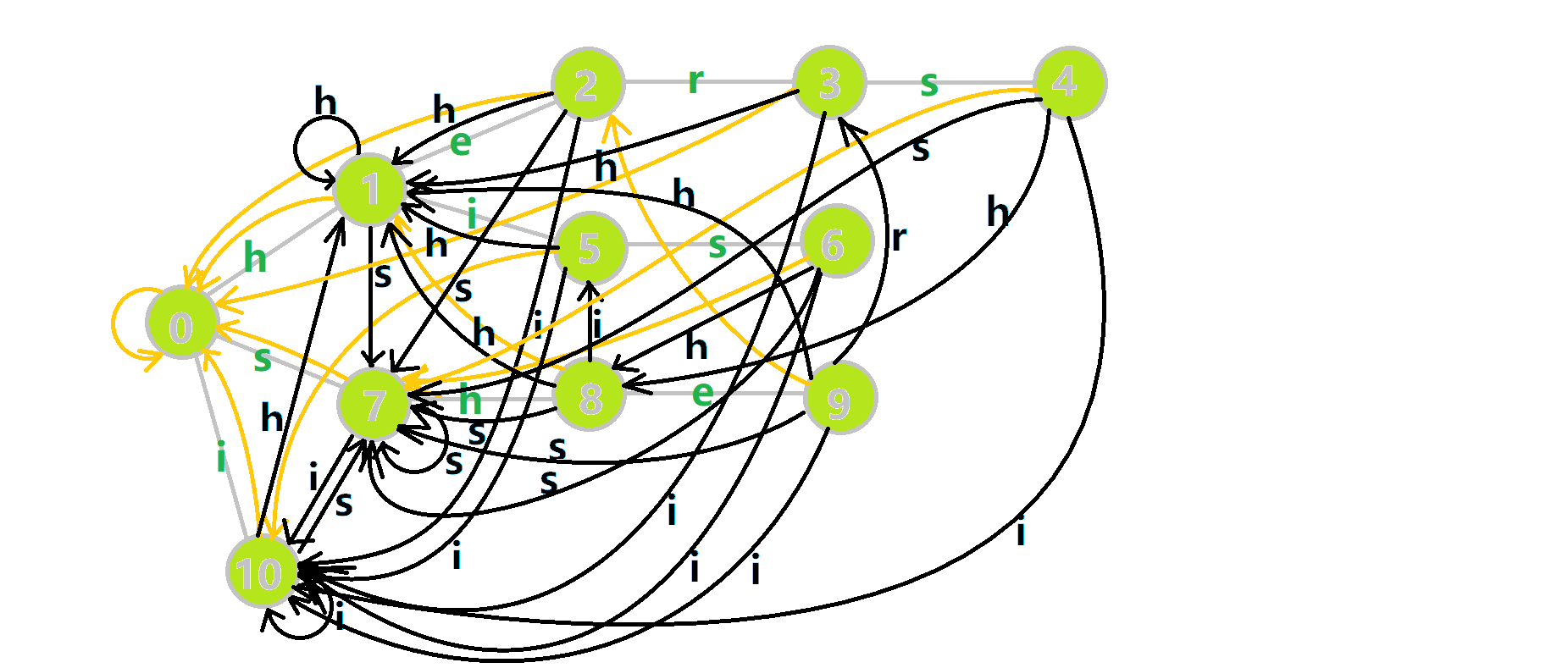
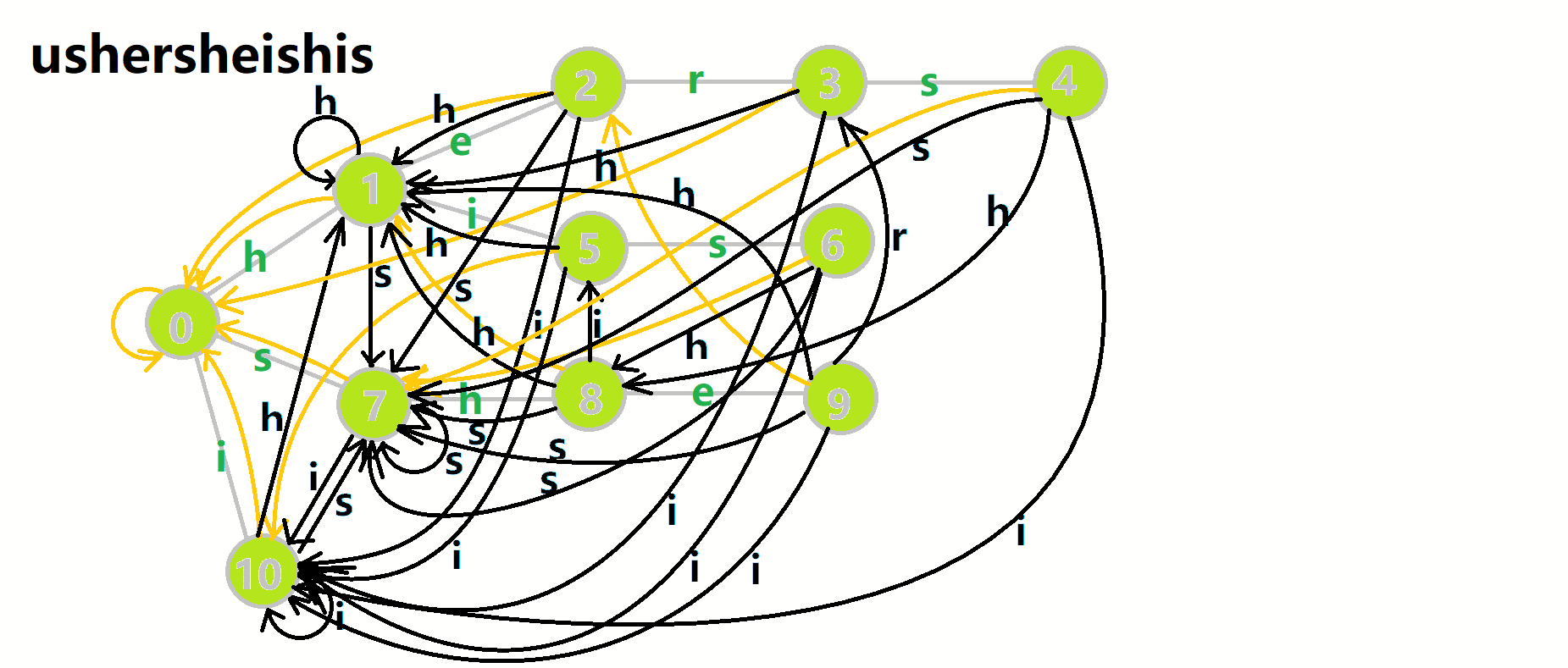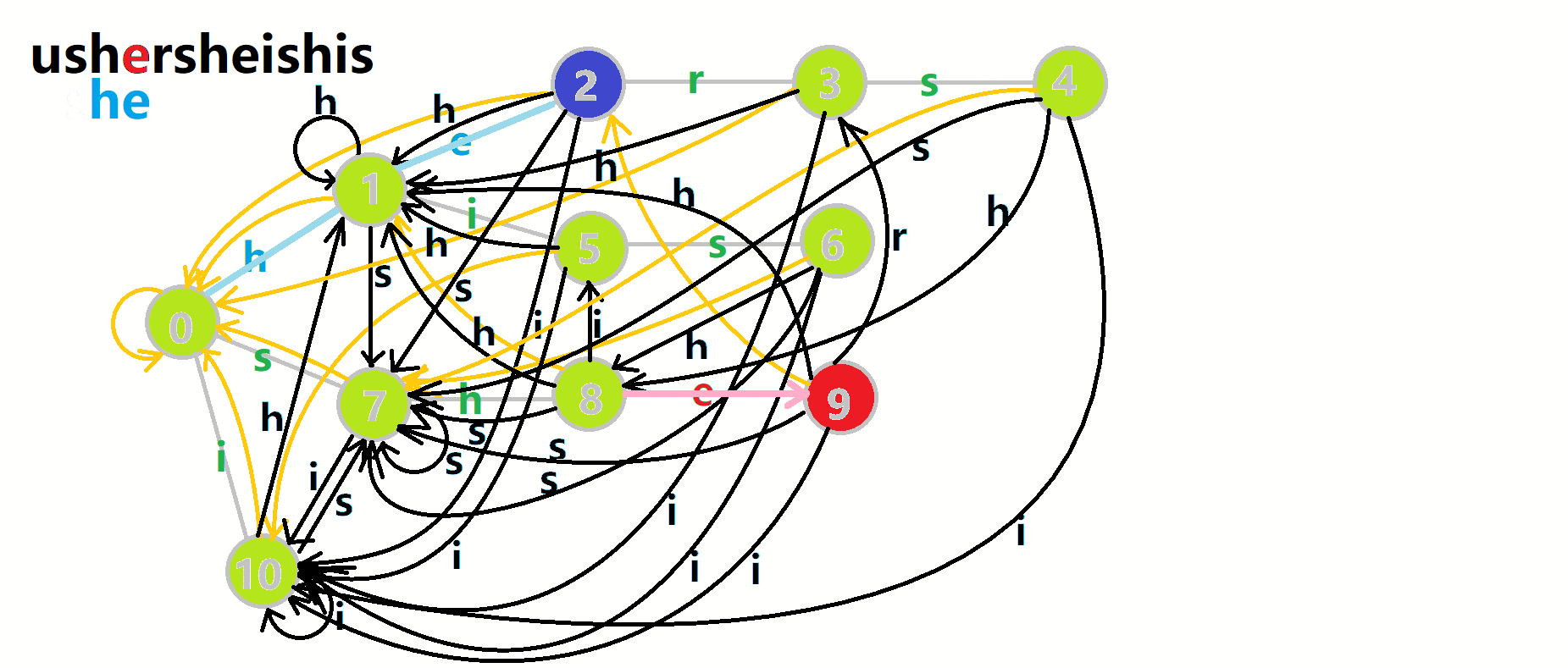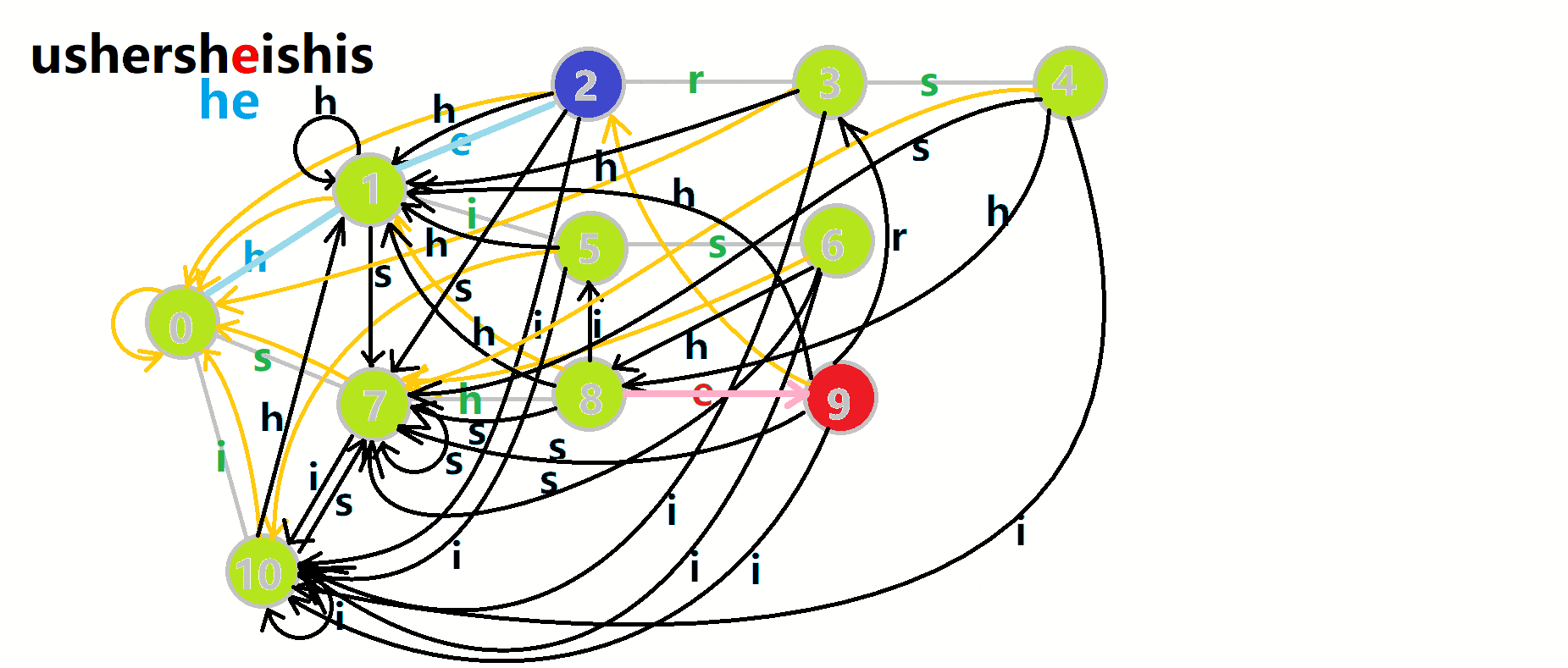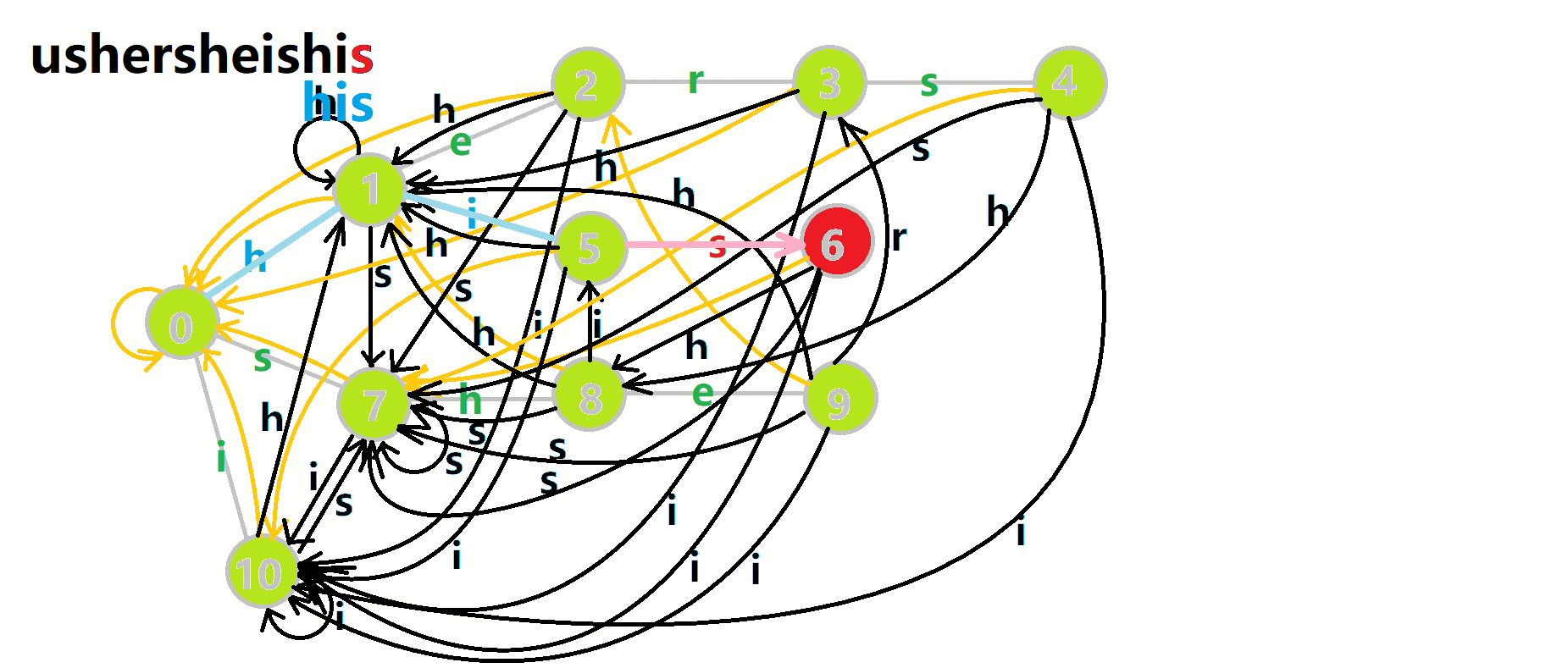
这里 now 作为字典树上当前匹配到的结点,ans 即返回的答案。循环遍历匹配串,now 在字典树上跟踪当前字符。利用 fail 指针找出所有匹配的模式串,累加到答案中。然后清零。在上文中我们分析过,字典树的结构其实就是一个 trans 函数,而构建好这个函数后,在匹配字符串的过程中,我们会舍弃部分前缀达到最低限度的匹配。fail 指针则指向了更多的匹配状态。最后上一份图。对于刚才的自动机:
我们从根结点开始尝试匹配 ushersheishis,那么 p 的变化将是:
红色结点:p 结点
粉色箭头:p 在自动机上的跳转,
蓝色的边:成功匹配的模式串
蓝色结点:示跳 fail 指针时的结点(状态)。
总结
时间复杂度:定义 ∣si∣ 是模板串的长度,∣S∣ 是文本串的长度,∣Σ∣ 是字符集的大小(常数,一般为 26)。如果连了 trie 图,时间复杂度就是 O(∑∣si∣+n∣Σ∣+∣S∣),其中 n 是 AC 自动机中结点的数目,并且最大可以达到 O(∑∣si∣)。如果不连 trie 图,并且在构建 fail 指针的时候避免遍历到空儿子,时间复杂度就是 O(∑∣si∣+∣S∣)。