#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> #include<cstdlib> usingnamespace std; constint N = 600010; int trie[N * 24][2], latest[N * 24]; // latest和end可合并为一个数组 int s[N], root[N], n, m, tot;
// 本题需要统计子树latest,故使用递归插入 // 插入s[i],当前为s[i]的第k位 voidinsert(int i, int k, int p, int q){ if (k < 0) { latest[q] = i; return; } int c = s[i] >> k & 1; if (p) trie[q][c ^ 1] = trie[p][c ^ 1]; trie[q][c] = ++tot; insert(i, k - 1, trie[p][c], trie[q][c]); latest[q] = max(latest[trie[q][0]], latest[trie[q][1]]); }
intask(int now, int val, int k, int limit){ if (k < 0) return s[latest[now]] ^ val; int c = val >> k & 1; if (latest[trie[now][c ^ 1]] >= limit) returnask(trie[now][c ^ 1], val, k - 1, limit); else returnask(trie[now][c], val, k - 1, limit); }
intmain(){ cin >> n >> m; latest[0] = -1; root[0] = ++tot; insert(0, 23, 0, root[0]); for (int i = 1; i <= n; i++) { int x; scanf("%d", &x); s[i] = s[i - 1] ^ x; root[i] = ++tot; insert(i, 23, root[i - 1], root[i]); } for (int i = 1; i <= m; i++) { char op[2]; scanf("%s", op); if (op[0] == 'A') { int x; scanf("%d", &x); root[++n] = ++tot; s[n] = s[n - 1] ^ x; insert(n, 23, root[n - 1], root[n]); } else { int l, r, x; scanf("%d%d%d", &l, &r, &x); printf("%d\n", ask(root[r - 1], x ^ s[n], 23, l - 1)); } } }
int n, m; int sum[N]; int trie[M][2], maxId[M], idx; int root[N];
voidinsert(int i, int k, int p, int q){ if (k < 0) { maxId[q] = i; return; } int c = sum[i] >> k & 1; if (p) trie[q][c ^ 1] = trie[p][c ^ 1]; trie[q][c] = ++idx; insert(i, k - 1, trie[p][c], trie[q][c]); maxId[q] = max(maxId[trie[q][0]], maxId[trie[q][1]]); }
voidinsert(int i, int p, int q){ maxId[q] = i; for (int k = 23; k >= 0; --k) { int c = sum[i] >> k & 1; if (p) trie[q][c ^ 1] = trie[p][c ^ 1]; trie[q][c] = ++idx; q = trie[q][c]; p = trie[p][c]; maxId[q] = i; } }
intask(int now, int val, int k, int limit){ if (k < 0) return sum[maxId[now]] ^ val; int c = val >> k & 1; if (maxId[trie[now][c ^ 1]] >= limit) { returnask(trie[now][c ^ 1], val, k - 1, limit); } else { returnask(trie[now][c], val, k - 1, limit); } }
intask(int nowRoot, int val, int limit){ int p = nowRoot; for (int i = 23; i >= 0; --i) { int c = val >> i & 1; if (maxId[trie[p][c ^ 1]] >= limit) p = trie[p][c ^ 1]; else p = trie[p][c]; } return sum[maxId[p]] ^ val; }
intmain(){ cin.tie(0); ios::sync_with_stdio(false); cin >> n >> m; maxId[0] = -1; root[0] = ++idx; insert(0, 0, root[0]); for (int i = 1; i <= n; ++i) { int x; cin >> x; sum[i] = sum[i - 1] ^ x; root[i] = ++idx; insert(i, root[i - 1], root[i]); } char op[2]; int l, r, x; while (m--) { cin >> op; if (op[0] == 'A') { cin >> x; ++n; sum[n] = sum[n - 1] ^ x; root[n] = ++idx; insert(n, root[n - 1], root[n]); } else { cin >> l >> r >> x; cout << ask(root[r - 1], sum[n] ^ x, l - 1) << endl; } } }
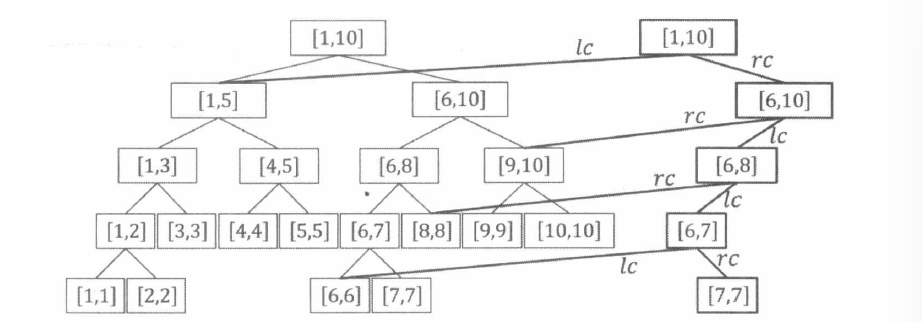
// 可持久化线段树,建树 structSegmentTree { int lc, rc; // 左右子节点编号 int dat; // 区间最大值 } tree[MAX_MLOGN]; int tot, root[MAX_M]; // 可持久化线段树的总点数和每个根 int n, a[MAX_N];
intbuild(int l, int r){ int p = ++tot; if (l == r) { tree[p].dat = a[l]; return p; }
intbuild(int l, int r){ int p = ++idx; // p 新建一个点 if (l == r) return p; int mid = l + r >> 1; tr[p].ls = build(l, mid); tr[p].rs = build(mid + 1, r); return p; }
intinsert(int now, int l, int r, int x){ int p = ++idx; // p 新建一个点 tr[p] = tr[now]; // 复制现版本数据 if (l == r) { // l == x && r == x ++tr[p].cnt; return p; } int mid = l + r >> 1; if (x <= mid) tr[p].ls = insert(tr[now].ls, l, mid, x); else tr[p].rs = insert(tr[now].rs, mid + 1, r, x); tr[p].cnt = tr[tr[p].ls].cnt + tr[tr[p].rs].cnt; return p; }
intask(int q, int p, int l, int r, int k){ if (l == r) return r; int mid = l + r >> 1; // tr[tr[q].ls].cnt 是 q(root[r]) 版本中 在[l, mid]左半区间范围里的数个数 // tr[tr[p].ls].cnt 是 p(root[l - 1]) 版本中 在[l, mid]左半区间范围里的数个数 int cnt = tr[tr[q].ls].cnt - tr[tr[p].ls].cnt; if (k <= cnt) returnask(tr[q].ls, tr[p].ls, l, mid, k); elsereturnask(tr[q].rs, tr[p].rs, mid + 1, r, k - cnt); }
intmain(){ cin.tie(0); ios::sync_with_stdio(false); cin >> n >> m; for (int i = 1; i <= n; ++i) { cin >> a[i]; nums.push_back(a[i]); } // 离散化 sort(nums.begin(), nums.end()); nums.erase(unique(nums.begin(), nums.end()), nums.end()); // 第0个版本的什么都没有就用build, build是建立好骨架, 每个版本insert改不同数据 root[0] = build(0, nums.size() - 1); // 后面的每插入一个点算一个版本, 每次插入都只是比上一个版本多1个数 // 左右参数给0和nums.size()-1是因为离散化之后的值域就是在0, nums.size()-1之间 // 要插入必须得把这些地方全包才能保证找得到插入点 for (int i = 1; i <= n; ++i) { root[i] = insert(root[i - 1], 0, nums.size() - 1, find(a[i])); } while (m--) { int l, r, k; cin >> l >> r >> k; int id = ask(root[r], root[l - 1], 0, nums.size() - 1, k); cout << nums[id] << endl; } }