选择排序(英语:Selection sort)是一种简单直观的排序算法。它的工作原理是每次找出第 i 小的元素(也就是 Ai..n 中最小的元素),然后将这个元素与数组第 i 个位置上的元素交换。
性质
稳定性
由于 swap(交换两个元素)操作的存在,选择排序是一种不稳定的排序算法。
时间复杂度
选择排序的最优时间复杂度、平均时间复杂度和最坏时间复杂度均为 O(n2)。
代码实现
伪代码
123456789Input. An array A consisting of n elements.Output. A will be sorted in nondecreasing order.Method. for i←1 to n−1ith←ifor j←i+1 to nif A[j]<A[ith]ith←jswap A[i] and A[ith]
C++
1 2 3 4 5 6 7 8 9 10 11
voidselection_sort(int a[], int n){ for (int i = 1; i < n; ++i) { int ith = i; for (int j = i + 1; j <= n; ++j) { if (a[j] < a[ith]) { ith = j; } } swap(a[i], a[ith]); } }
1234567891011Input. An array A consisting of n elements.Output. A will be sorted in nondecreasing order stably.Method. flag←Trueflag: need sortwhile flagflag←Falsefor i←1 to n−1if A[i]>A[i+1]flag←TrueSwap A[i] and A[i+1]–n
C++
1 2 3 4 5 6 7 8 9 10 11 12 13
voidbubble_sort(int a[], int n){ bool sorted = false; //整体排序标志,首先假定尚未排序 while (!sorted) { //在尚未确定已全局排序之前,逐趟进行扫描交换 sorted = true; //假定已经排序 for (int i = 1; i < n; ++i) { if (a[i] > a[i + 1]) { sorted = false swap(a[i], a[i + 1]); //因整体排序不能保证,需要清除排序标志 } } --n; //至此末元素必然就位,故可以缩短待排序序列的有效长度 } }
1234567891011Input. An array A consisting of n elements.Output. A will be sorted in nondecreasing order stably.Method. for i←2 to nkey=A[i]Insert A[i] into the sorted sequence A[1⋯i−1]j=i−1while j>0 and A[j]>keyA[j+1]=A[j]j=j−1A[j+1]=key
C++
1 2 3 4 5 6 7 8 9 10 11 12
voidinsertion_sort(int a[], int n){ // 对 a[1],a[2],...,a[n] 进行插入排序 for (int i = 2; i <= n; ++i) { int key = a[i]; int j = i - 1; while (j > 0 && a[j] > key) { a[j + 1] = a[j]; --j; } a[j + 1] = key; } }
计数排序
1
注意:本页面要介绍的不是基数排序。
计数排序(英语:Counting sort)是一种线性时间的排序算法。
工作原理
计数排序的工作原理是使用一个额外的数组 C,其中第 i 个元素是待排序数组 A 中值等于 i 的元素的个数,然后根据数组 C 来将 A 中的元素排到正确的位置。
它的工作过程分为三个步骤:
计算每个数出现了几次;
求出每个数出现次数的前缀和;
利用出现次数的前缀和,从右至左计算每个数的排名。
算法导论详解
计数排序假设 n 个输入元素中的每一个都是在 0 到 k 区间内的一个整数, 其中 k 为某个整 数。当 k=O(n) 时, 排序的运行时间为 Θ(n) 。
计数排序的基本思想是:对每一个输入元素 x, 确定小于 x 的元素个数。利用这一信息, 就 可以直接把 x 放到它在输出数组中的位置上了。例如, 如果有 17 个元素小于 x, 则 x 就应该在第 18 个输出位置上。当有几个元素相同时, 这一方案要略做修改。因为不能把它们放在同一个输出位置上。
COUNTING-SORT (A,B,k)12345678910111213let C[0…k] be a new array for i=0 to kC[i]=0for j=1 to A. length C[A[j]]=C[A[j]]+1//C[i] now contains the number of elements equal to i.for i=1 to kC[i]=C[i]+C[i−1]//C[i] now contains the number of elements less than or equal to i.for j=A. length downto 1B[C[A[j]]]=A[j]C[A[j]]=C[A[j]]−1return B
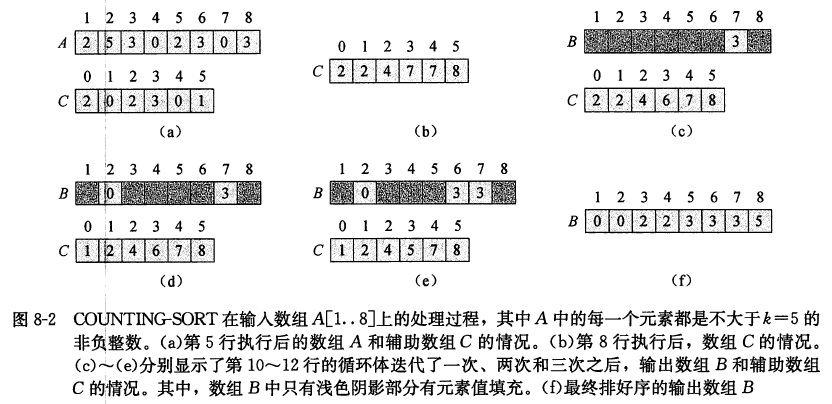
下图展示了计数排序的运行过程。在第 2∼3 行 for 循环的初始化操作之后, 数组 C 的值全 被置为 0 ; 第 4∼5 行的 for 循环遍历每一个输入元素。如果一个输入元素的值为 i, 就将 C[i] 值加 1 。于是, 在第 5 行执行完后, C[i] 中保存的就是等于 i 的元素的个数, 其中 i=0,1,⋯,k 。 第 7∼8 行通过加总计算确定对每一个 i=0,1,⋯,k, 有多少输入元素是小于或等于 i 的。
12345678910111213Input. An array A consisting of n positive integers no greater than w.Output. Array A after sorting in nondecreasing order stably.Method. for i←0 to wcnt[i]=0for i←1 to ncnt[A[i]]=cnt[A[i]]+1for i←1 to wcnt[i]=cnt[i]+cnt[i−1]for i←n downto 1B[cnt[A[i]]]=A[i]cnt[A[i]]=cnt[A[i]]−1return B
C++
1 2 3 4 5 6 7 8 9 10 11 12
// C++ Version constint N = 100010; constint W = 100010;
int n, w, a[N], cnt[W], b[N];
voidcounting_sort(){ memset(cnt, 0, sizeof(cnt)); for (int i = 1; i <= n; ++i) ++cnt[a[i]]; for (int i = 1; i <= w; ++i) cnt[i] += cnt[i - 1]; for (int i = n; i >= 1; --i) b[cnt[a[i]]--] = a[i]; //如果b从0开始存储,则--cnt[a[i]] }
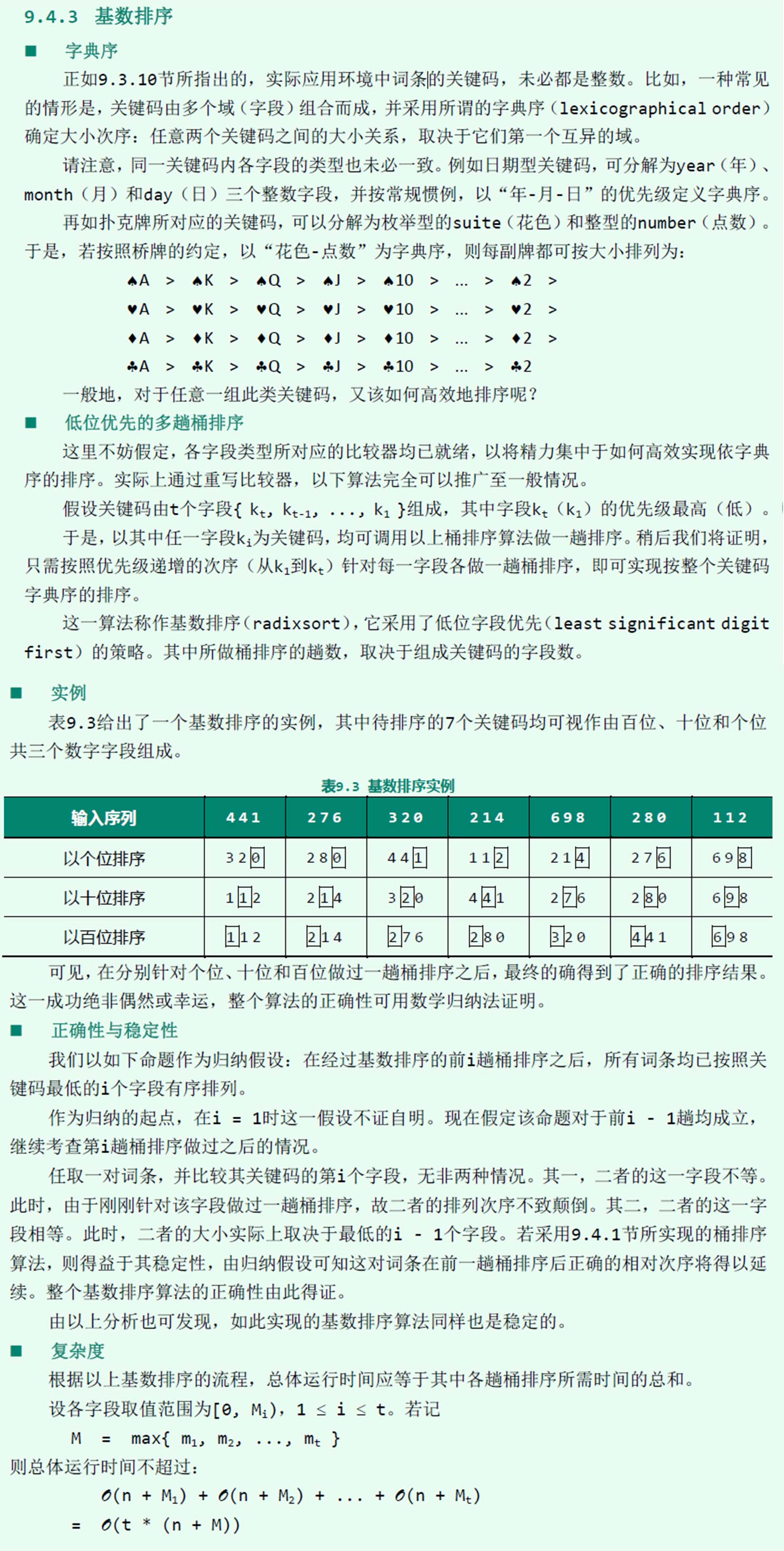
基数排序的代码是非常直观的。在下面的代码中, 我们假设 n 个 d 位的元素存放在数组 A 中, 其中第 1 位是最低位, 第 d 位是最高位。
RADIX-SORT (A,d)12for i=1 to duse a stable sort to sort array A on digit i
引理 8.3: 给定 n 个 d 位数, 其中每一个数位有 k 个可能的取值。如果 RADIX-SORT 使用的稳定排序方法耗时 Θ(n+k), 那么它就可以在 Θ(d(n+k)) 时间内将这些数排好序。
证明: 基数排序的正确性可以通过对被排序的列进行归纳而加以证明。对算法时间代价的分析依赖于所使用的稳定的排序算法。当每位数字都在 0 到 k−1 区间内(这样它就有 k 个可能的取值), 且 k 的值不太大的时候, 计数排序是一个好的选择。对 n 个 d 位数来说, 每一轮排序耗时 Θ(n+k) 。共有 d 轮, 因此基数排序的总时间为 Θ(d(n+k)) 。
当 d 为常数且 k=O(n) 时, 基数排序具有线性的时间代价。在更一般的情况中, 我们可以灵活地决定如何将每个关键字分解成若干位。
引理 8.4: 给定一个 b 位数和任何正整数 r⩽b, 如果 RADIX-SORT 使用的稳定排序算法对数据取值区间是 0 到 k 的输入进行排序耗时 Θ(n+k), 那么它就可以在 Θ((b/r)(n+2r)) 时间内将这些数排好序。
一般来说,如果每个关键字的值域都不大,就可以使用 计数排序 作为内层排序,此时的复杂度为 O(kn+i=1∑kwi),其中 wi 为第 i 关键字的值域大小。如果关键字值域很大,就可以直接使用基于比较的 O(nklogn) 排序而无需使用基数排序了。
空间复杂度
基数排序的空间复杂度为 O(k+n)。
算法实现
伪代码
12345Input. An array A consisting of n elements, where each element has k keys.Output. Array A will be sorted in nondecreasing order stably.Method. for i←k down to 1sort A into nondecreasing order by the i-th key stably
void radix_sort(int n, int a[]) { int *b = new int[n]; // 临时空间 int *cnt = new int[1 << 8]; int mask = (1 << 8) - 1; int *x = a, *y = b; for (int i = 0; i < 32; i += 8) { for (int j = 0; j != (1 << 8); ++j) cnt[j] = 0; for (int j = 0; j != n; ++j) ++cnt[x[j] >> i & mask]; for (int sum = 0, j = 0; j != (1 << 8); ++j) { // 等价于 std::exclusive_scan(cnt, cnt + (1 << 8), cnt, 0); sum += cnt[j], cnt[j] = sum - cnt[j]; } for (int j = 0; j != n; ++j) y[cnt[x[j] >> i & mask]++] = x[j]; std::swap(x, y); } delete[] cnt; delete[] b; }
int main() { std::ios::sync_with_stdio(false); std::cin.tie(0); int n; std::cin >> n; int *a = new int[n]; for (int i = 0; i < n; ++i) std::cin >> a[i]; radix_sort(n, a); for (int i = 0; i < n; ++i) std::cout << a[i] << ' '; delete[] a; return 0; }
参考资料与注释
Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein.Introduction to Algorithms(3rd ed.). MIT Press and McGraw-Hill, 2009. ISBN 978-0-262-03384-8. “8.3 Radix sort”, pp. 199.
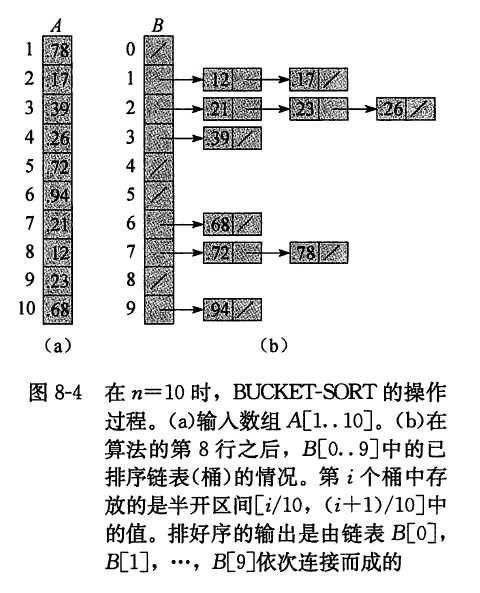
桶排序将 [0,1) 区间划分为 n 个相同大小的子区间, 或称为桶。然后, 将 n 个输入数分别放 到各个桶中。因为输入数据是均匀、独立地分布在 [0,1) 区间上, 所以一般不会出现很多数落在同一个桶中的情况。为了得到输出结果, 我们先对每个桶中的数进行排序, 然后遍历每个桶, 按照次序把各个桶中的元素列出来即可。
在桶排序的代码中, 我们假设输入是一个包含 n 个元素的数组 A, 且每个元素 A[i] 满足 0⩽A[i]<1 。此外, 算法还需要一个临时数组 B[0..n−1] 来存放链表 (即桶), 并假设存在一种用于维护这些链表的机制。
BUCKET-SORT (A)1n=A. length 2 let B[0..n−1] be a new array 3 for i=0 to n−14 make B[i] an empty list 5 for i=1 to n6 insert A[i] into list B[⌊nA[i]]]7 for i=0 to n−18 sort list B[i] with insertion sort 9 concatenate the lists B[0],B[1],⋯,B[n−1] together in order
voidinsertion_sort(vector<int>& A){ for (int i = 1; i < A.size(); ++i) { int key = A[i]; int j = i - 1; while (j >= 0 && A[j] > key) { A[j + 1] = A[j]; --j; } A[j + 1] = key; } }
voidbucket_sort(){ int bucket_size = w / n + 1; for (int i = 0; i < n; ++i) { bucket[i].clear(); } for (int i = 1; i <= n; ++i) { bucket[a[i] / bucket_size].push_back(a[i]); } int p = 0; for (int i = 0; i < n; ++i) { insertion_sort(bucket[i]); for (int j = 0; j < bucket[i].size(); ++j) { a[++p] = bucket[i][j]; } } }
123456789101112131415161718 MERGE (A,p,q,r)n1=q−p+1n2=r−qlet L[1…n1+1] and R[1.n2+1] be new arrays for i=1 to n1L[i]=A[p+i−1]for j=1 to n2R[j]=A[q+j]L[n1+1]=∞R[n2+1]=∞i=1j=1for k=p to rif L[i]⩽R[j]A[k]=L[i]i=i+1elseA[k]=R[j]j=j+1
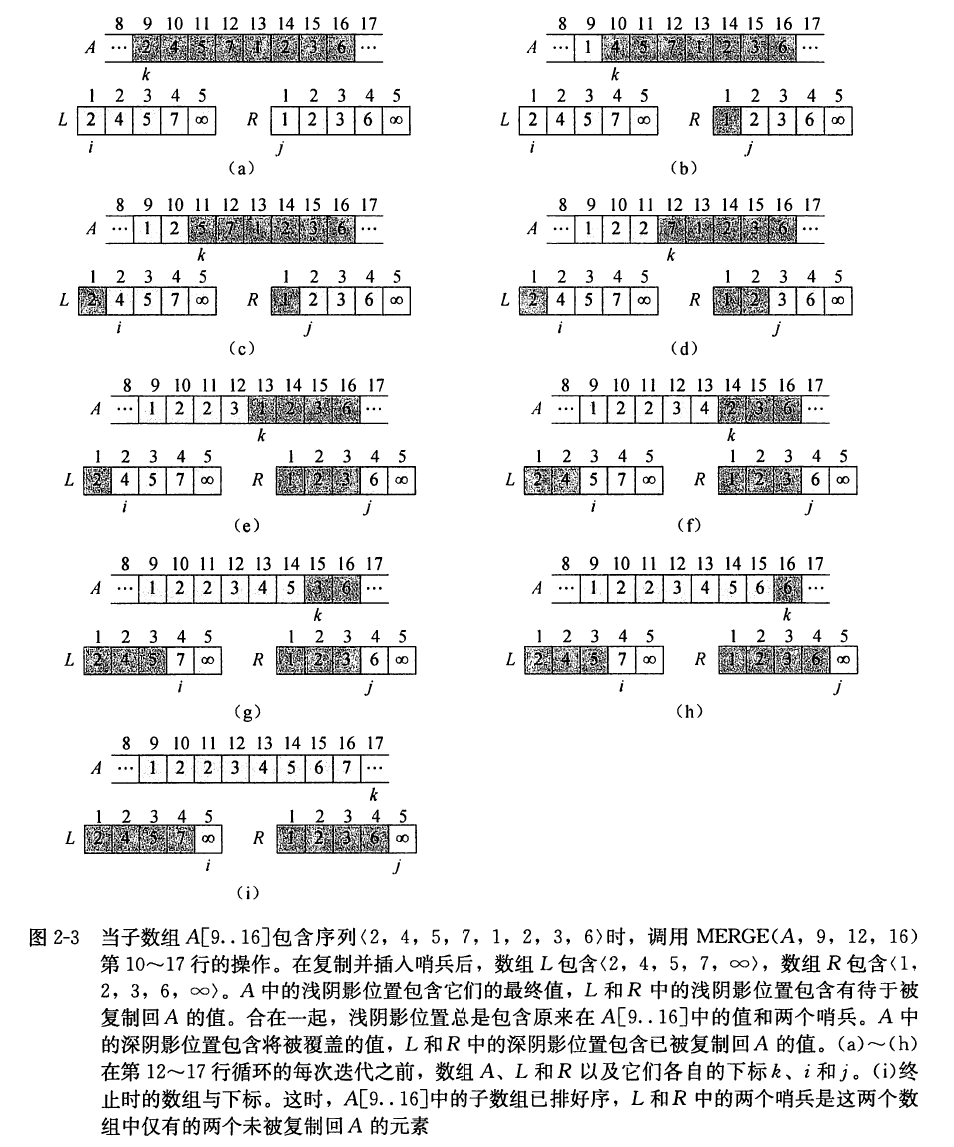
过程 MERGE 的详细工作过程如下: 第 1 行计算子数组 A[p..q] 的长度 n1, 第 2 行计算子数组 A[q+1..r] 的长度 n2 。在第 3 行, 我们创建长度分别为 n1+1 和 n2+1 的数组 L 和 R ( “左”和“右”), 每个数组中额外的位置将保存哨兵。第 4∼5 行的 for 循环将子数组 A[p..q] 复制到 L[1…n1], 第 6∼7 行的 for 循环将子数组 A[q+1..r] 复制到 R[1..n2] 。第 8∼9 行将哨兵放在数组 L 和 R 的末尾。第 10∼18 行图示在上图中, 通过维持以下循环不变式, 执行 r−p+1 个基本步骤:
在开始第 12∼18 行 for 循环的每次迭代时, 子数组 A[p..k−1] 按从小到大的顺序包含 L[1⋯n1+1] 和 R[1⋯n2+1] 中的 k−p 个最小元素。进而, L[i] 和 R[j] 是各自所在数组中未被复制回数组 A 的最小元素。
我们必须证明第 12∼18 行 for 循环的第一次迭代之前该循环不变式成立, 该循环的每次迭 代保持该不变式, 并且循环终止时, 该不变式提供了一种有用的性质来证明正确性。
初始化: 循环的第一次迭代之前, 有 k=p, 所以子数组 A[p..k−1] 为空。这个空的子数组 包含 L 和 R 的 k−p=0 个最小元素。又因为 i=j=1, 所以 L[i] 和 R[j] 都是各自所在数组中未被复制回数组 A 的最小元素。
保持: 为了理解每次迭代都维持循环不变式, 首先假设 L[i]⩽R[j] 。这时, L[i] 是未被复制回数组 A 的最小元素。因为 A[p..k−1] 包含 k−p 个最小元素,所以在第 14 行将 L[i] 复制到 A[k] 之后, 子数组 A[p..k] 将包含 k−p+1 个最小元素。增加 k 的值(在 for 循环中更新)和 i 的值(在第 15 行中) 后, 为下次迭代重新建立了该循环不变式。反之, 若 L[i]>R[j], 则第 16∼18 行执行适当的操作来维持该循环不变式。
终止: 终止时 k=r+1 。根据循环不变式, 子数组 A[p..k−1] 就是 A[p..r] 且按从小到大的顺序包含 L[1..n1+1] 和 R[1…n2+1] 中的 k−p=r−p+1 个最小元素。数组 L 和 R 一起包含 n1+n2+2=r−p+3 个元素。除两个最大的元素以外, 其他所有元素都已被复制回数组 A, 这两个最大的元素就是哨兵。
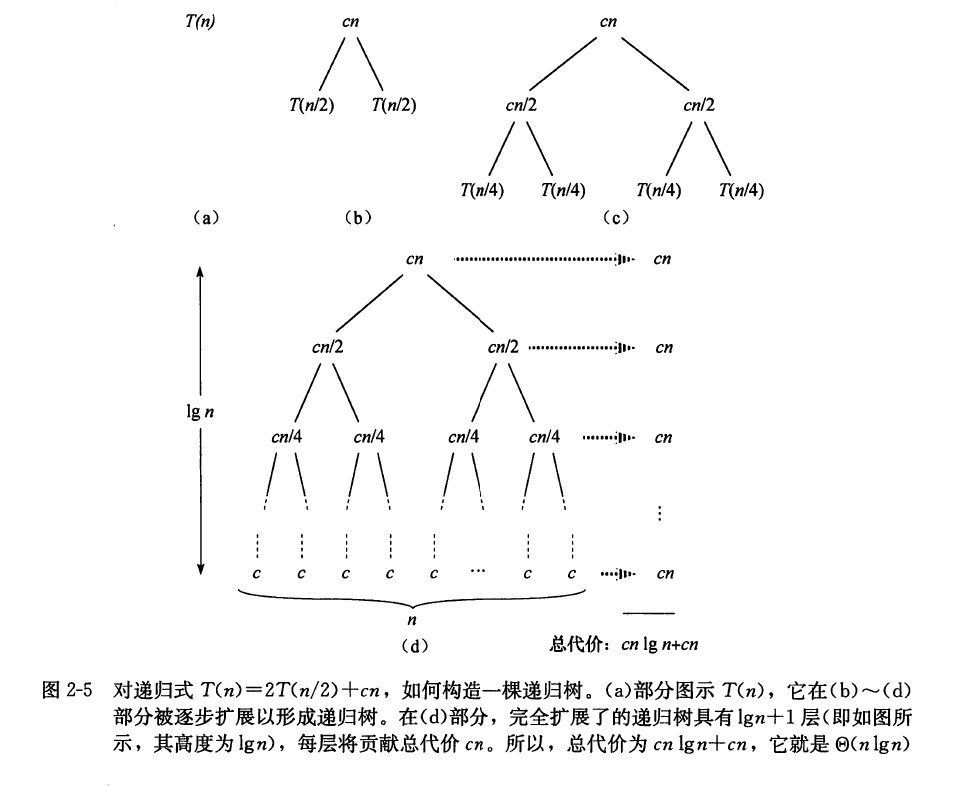
为了理解过程 MERGE 的运行时间是 Θ(n), 其中 n=r−p+1, 注意到, 第 1∼3 行和第 8∼11 行中的每行需要常量时间, 第 4∼7 行的 for 循环需要 Θ(n1+n2)=Θ(n) 的时间, 并且, 第 12∼18 行的 for 循环有 n 次迭代, 每次迭代需要常量时间。
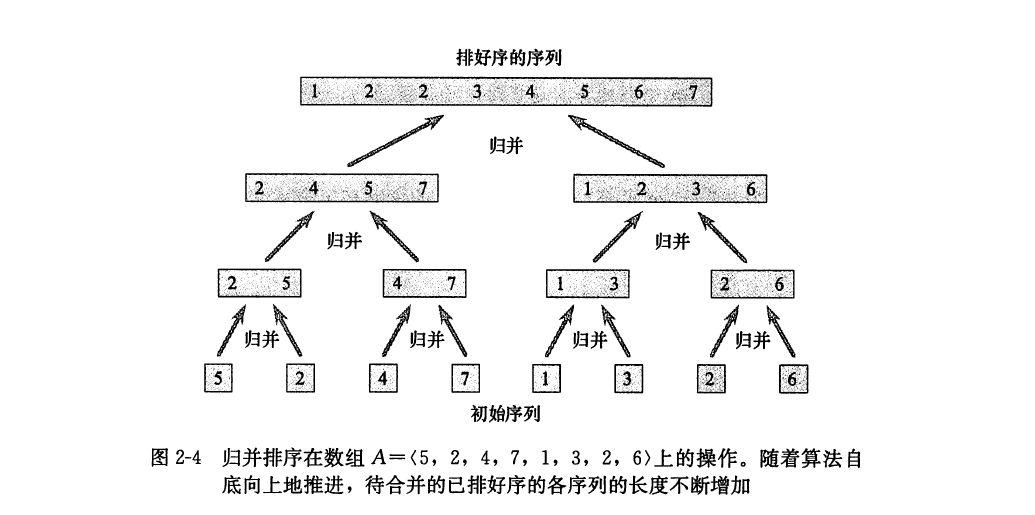
1234567891011121314151617181920Input. 待排序的数组A和用作临时存储的数组TOutput. 数组A中的元素将会按照不减的顺序进行稳定排序Method.mergeSort(A,T,l,r)ifl⩾rreturnmid←⌊2l+r⌋mergeSort(A,T,ll,mid)mergeSort(A,T,mid,rr)i=lj=mid+1for each k in the l…rifj>rori⩽midandA[i]⩽A[j]T[k]=A[i]i=i+1elseT[k]=A[j]j=j+1copy T[l…r] to A[l…r]
C++
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// temp数组是临时存放有序的版本用的。 voidmergeSort(int a[], int l, int r){ if (l >= r) return;
int mid = l + r >> 1; mergeSort(a, l, mid); mergeSort(a, mid + 1, r); int k = l, i = l, j = mid + 1; while (k <= r) { if (j > r || i <= mid && a[i] <= a[j]) temp[k++] = a[i++]; else temp[k++] = a[j++]; } for (int i = l; i <= r; ++i) a[i] = temp[i]; } // 关键点在于一次性创建数组,避免在每次递归调用时创建,以避免内存分配的耗时。
逆序对
归并排序还可以用来求逆序对的个数。
所谓逆序对,就是对于一个数组 a,满足 ai>aj 且 i<j 的数对 (i,j)。
代码实现中注释掉的 ans += mid - p 就是在统计逆序对个数。具体来说,算法把靠后的数放到前面了(较小的数放在前面),所以在这个数原来位置之前的、比它大的数都会和它形成逆序对,而这个个数就是还没有合并进去的数的个数,即 mid - p。
voidquicksort(int a[], int l, int r){ if (l >= r) return;
int pivot = a[l + r >> 1]; int i = l - 1, j = r + 1; while (i < j) { while (a[++i] < pivot); while (a[--j] > pivot); if (i < j) swap(a[i], a[j]); } // [l, j]:<= pivot , [j + 1, r]:>= pivot quicksort(a, l, j); quicksort(a, j + 1, r); }
在下面的代码示例中,第 k 大的数被定义为序列排成升序时,第 k 个位置上的数(编号从 0 开始)。
找第 k 大的数(K-th order statistic),最简单的方法是先排序,然后直接找到第 k 大的位置的元素。这样做的时间复杂度是 O(nlogn),对于这个问题来说很不划算。
我们可以借助快速排序的思想解决这个问题。考虑快速排序的划分过程,在快速排序的「划分」结束后,数列 Ap⋯Ar 被分成了 Ap⋯Aq 和 Aq+1⋯Ar,此时可以按照左边元素的个数(q−p+1)和 k 的大小关系来判断是只在左边还是只在右边递归地求解。
可以证明,在期望意义下,程序的时间复杂度为 O(n)。
最坏情况下 O(n) 算法:Median of medians
实现(C++)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
intquickSelect(int a[], int l, int r, int k){ if (l >= r) return a[r];
int pivot = a[l + r >> 1]; int i = l - 1, j = r + 1; while (i < j) { while (a[++i] < pivot); while (a[--j] > pivot); if (i < j) swap(a[i], a[j]); } // [l, j]:<= pivot , [j + 1, r]:>= pivot int n = j - l + 1; // [l, j] 是最小的 n 个数 if (k <= n) returnquickSelect(a, l, j, k); elsereturnquickSelect(a, j + 1, r, k - n); }
classHeap { public: voidbuild(vector<int> &h, int last){ // 自底向上建堆,时间复杂度O(n) // 从最后一个节点的父节点逆序开始 down 以完成堆化 (heapify) for (int i = last / 2; i >= 0; --i) down(h, i, last); }
voidheapSort(vector<int> &h, int last){ build(h, last); // 首先建立大顶堆 // 将堆顶的元素取出,作为最大值,与数组尾部的元素交换,并维持残余堆的性质,重复 for (int i = last; i > 0; --i) { swap(h[0], h[i]); down(h, 0, i - 1); } }
voiddown(vector<int> &h, int u, int last){ int fa = u; while (fa <= last) { int ls = 2 * fa + 1, rs = 2 * fa + 2; int t = fa; if (ls <= last && h[ls] > h[t]) t = ls; if (rs <= last && h[rs] > h[t]) t = rs; if (t != fa) { // 子节点比父节点大,交换父子内容,子结点再和孙结点比较 swap(h[fa], h[t]); fa = t; } else { // 如果父结点比子结点大,代表调整完毕,直接跳出函数 return; } } } };
// C++ Version voidsift_down(int arr[], int start, int end){ // 计算父结点和子结点的下标 int parent = start; int child = parent * 2 + 1; while (child <= end) { // 子结点下标在范围内才做比较 // 先比较两个子结点大小,选择最大的 if (child + 1 <= end && arr[child] < arr[child + 1]) child++; // 如果父结点比子结点大,代表调整完毕,直接跳出函数 if (arr[parent] >= arr[child]) return; else { // 否则交换父子内容,子结点再和孙结点比较 swap(arr[parent], arr[child]); parent = child; child = parent * 2 + 1; } } }
voidheap_sort(int arr[], int len){ // 从最后一个节点的父节点开始 sift down 以完成堆化 (heapify) for (int i = (len - 1 - 1) / 2; i >= 0; i--) sift_down(arr, i, len - 1); // 先将第一个元素和已经排好的元素前一位做交换,再重新调整(刚调整的元素之前的元素),直到排序完毕 for (int i = len - 1; i > 0; i--) { swap(arr[0], arr[i]); sift_down(arr, 0, i - 1); } }
// C++ Version template <typename T> voidshell_sort(T array[], int length){ int h = 1; while (h < length / 3) { h = 3 * h + 1; } while (h >= 1) { for (int i = h; i < length; i++) { for (int j = i; j >= h && array[j] < array[j - h]; j -= h) { std::swap(array[j], array[j - h]); } } h = h / 3; } }
intcompare(constvoid *p1, constvoid *p2)// int 类型数组的比较函数 { int *a = (int *)p1; int *b = (int *)p2; if (*a > *b) return1; // 返回正数表示 a 大于 b elseif (*a < *b) return-1; // 返回负数表示 a 小于 b else return0; // 返回 0 表示 a 与 b 等价 }
注意:返回值用两个元素相减代替正负数是一种典型的错误写法,因为这样可能会导致溢出错误。
以下是排序结构体的一个示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
structeg // 示例结构体 { int e; int g; };
intcompare(constvoid *p1, constvoid *p2)// struct eg 类型数组的比较函数:按成员 e 排序 { structeg *a = (struct eg *)p1; structeg *b = (struct eg *)p2; if (a->e > b->e) return1; // 返回正数表示 a 大于 b elseif (a->e < b->e) return-1; // 返回负数表示 a 小于 b else return0; // 返回 0 表示 a 与 b 等价 }